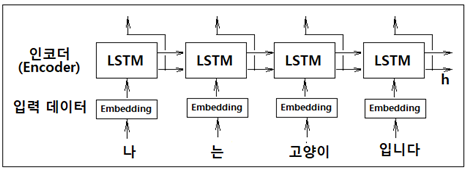
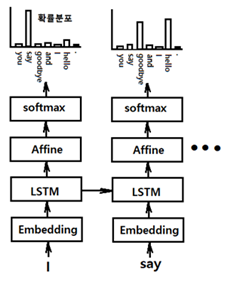
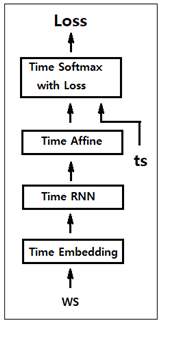
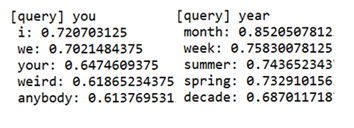
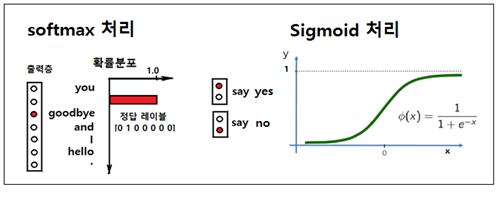
기계 번역 분야에서 매우 인기가 있었던 Sequence to Sequence 모델은 두 개의 RNN 즉 인코더와 디코더를 짝으로 구성된다. 인코더는 입력을 순차적으로 처리하고 모든 입력 데이터를 감안한 은닉층 벡터를 생성한다. 그 생성된 은닉층 데이터는 해당 컨텍스트를 사용하여 적절한 대상 시퀀스(번역, 챗봇의 응답)를 예측 학습하는 디코더로 전달된다. 중요 응용 분야는 다음과 같다. 기계 번역: 한 언어의 문장을 다른 언어로 번역 자동 용약: 긴 문장을 짧게 요약된 문장으로 변환 질의 응답: 질문을 응답으로 변환 메일 자동 응답: 수신한 이메일 문장을 답변 글로 변환 sequence는 RNN 이나 LSTM에서 일정한 길이를 가지는 데이터를 의미한다. 인코더의 역할은 특정 언어의 입력 데이터를 받아들여 ..