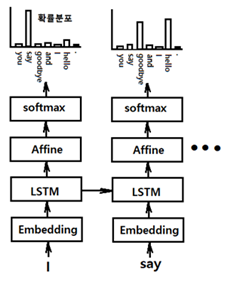
LSTM을 사용하는 텍스트 즉 문장 생성의 원리에 대해서 살펴보자.
“You say goodbye and I say hello.” 라는 단어장으로부터 학습하는 모델을 생각해보자. 이 절의 내용은 2022년 12월 베타버전이 오픈된 오늘날의 chatGPT3.5 버전의 기원이 될 수도 있는 중요한 알고리듬의 영역에 해당함에 유의하자.
그림과 같이 ‘I’가 입력 데이터일 때 출력을 ‘say’라는 단어 자체로 결정론적으로 학습시키는 것이 아니라 ‘say’라는 단어의 출현 확률로도 학습이 가능하다.
6.7절에서 사용했던 특정한 단어를 직접 지정하는 경우는 결정론적(deterministic) 방법에 해당한다, 이는 출현 단어의 확률 분포 측면에서 보면 해당 단어의 출현 확률이 1.0 이고 나머지는 모두 0.0 이 되는 즉 one hot 코드 형태가 된다. 반면에 확률적인 지정도 가능하다. 각 후보 단어들의 확률에 따라 선택이 이루어지므로 높은 확률을 가지는 단어가 선택될 확률이 높다. 하지만 확률이기 때문에 확률이 낮은 단어가 선택될 수도 있음에 유의하자. 매번 실행 시마다 다른 결과가 얻어질 수도 있을 것이다.
‘say’가 두 번째 입력 단어일 경우 변경된 확룰분포를 출력에 적용해야 한다. ‘goodbye’ 또는 ‘hello’기 선택될 확률이 높다. 이런 방식으로 확률분포 학습 및 확률적 선택에 따른 문장이 생성될 수 있을 것이다.
텍스트 생성을 위해 generate_text가 호출하는 RnnlmGen() 클라스의 인수가 Rnnlm 클라스(“밑바닥부터 시작하는 딥러닝 2편, 6장“ 참조) 임에 유의해서 연관되는 instance(self) 변수들을 단계별로 찾아보자. RnnlmGen() 클라스에서 Rnnlm 클라스를 통째로 인수로 제공할 경우 Rnnlm 클라스의 메서드 predict, forward, backward, reset_state, save_params, load_params 들을 상속받아 사용할 수 있다. 아울러 RnnlmGen() 클라스에 추가된 메서드 generate()도 상속 사용이 가능해진다.
PTB 학습 데이터세트를 읽어서 corpus, word_to_id, id_to_word를 추출한다.
단어장(corpus) 크기는 929,589이며 vocab_size 크기는 10000 이다.
RnnlmGen() 클라스에서 통째로 인수로 제공되는 Rnnlm 클라스의 초기화 메서드를 보면 vocab_size=10,000 으로 정의된다. 만약 여기서 이 값을 317로 정의하면 상류 generate_text에서 10,000으로 설정해도 하류에서 초기화된 값이 세팅됨에 유의하자. (※ 원칙적으로는 동일한 값을 설정해야 한다.)
| class Rnnlm(BaseModel): def __init__(self, vocab_size=10,000, wordvec_size=100, hidden_size=100): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn print('vocab_size=', vocab_size) |
RnnlmGen 클라스를 model로 설정하고, 2종류 문장 생성 사례를 검토하자.
첫 번째는 앞 절의 Rnnlm클라스 perplexity 계산에서 전체 PTB 파일을 대상으로 학습한 결과를 사용치 않는 사례이다. 두 번째는 이 PTB 파일 학습 결과를 불러서 문장을 생성하는 사례이다. 당연히 두 번째를 사용해야 하지만 코드 알고리듬 이해 차원에서 첫 번째를 골부할 필요가 있다.
메인 코드 generate_text.py 의 앞 부분을 살펴보자. 학습용 PTB 파일을 대상으로 corpus, word_to_id, id_to_word를 얻어내자. 내부적으로 load_data를 부르면 그 안에서 load_vocab를 사용하여 피클된 ptb.vocab.pkl로부터 이들 정보를 얻는다. 하지만 이 피클 파일에는 파라메터 데이터는 포함되지 않는다.
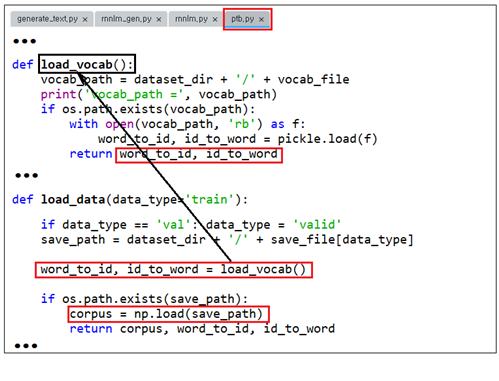
corpus를 load 하는 주소를 출력해보자(Anaconda 사례)
word_to_id 와 id_to_word를 출력하는 vocab_path를 출력해 보자(Anaconda 사례)
한편 메인인 generate_text.py를 실행시키면 가중치 및 기울기를 포함하는 이미 학습된 파라메터 데이터는 model을 상속하는 RnnlmGen 클라스의 인수인 Rnnlm 클라스의 메서드인 load_params를 사용하여 Rnnlm.pkl을 불러와서 처리된다.
| 1 | corpus, word_to_id, id_to_word = ptb.load_data('train') vocab_size = len(word_to_id) print('vocab size = ', vocab_size) corpus_size = len(corpus) print('corpus size = ', corpus_size) model = RnnlmGen() #model.load_params('../ch06/Rnnlm.pkl') 첫번째 사례에 해당 start_word = 'you' # start 문자와 skip 문자 설정 ------------------------------------------------------------ vocab size = 10000 corpus size = 929589 |
우선 첫 번째 사례를 고려해보자. 시작어를 ‘you’ 로 선정 후 word_to_id 를 출력해보면 316임을 알수 있다. 금지어 ['N', '<unk>', '$'] 는 [27, 26, 416] 이다.
| 2 | # start 문자와 skip 문자 설정 start_word = 'you' start_id = word_to_id[start_word] print('start_id = ', start_id) skip_words = ['N', '<unk>', '$'] skip_ids = [word_to_id[w] for w in skip_words] print(skip_ids) ------------------------------------------------------------ start_id = 316 [27, 26, 416] |
모델 즉 RnnlmGen 클라스의 generate 메서드를 사용하여 문장을 생성하기 위한 단어 id들을 생성하여 이들을 연결(join) 하자. <eos> 는 마침표 및 new line(.\n)으로 대체하도록 한다.
| 3 | # 문장 생성 word_ids = model.generate(start_id, skip_ids) txt = ' '.join([id_to_word[i] for i in word_ids]) txt = txt.replace(' <eos>', '.\n') print(txt) |
모델의 generate 메서드에서 어떻게 단어들을 생성시켜 끄집어내는지 살펴보자.
generate 메서드의 인수는 start_id, skip_ids, sample_size이다. start_id 는 ‘you’d[ 해당하는 ‘316’이고, 금지어를 뜻하는 skip_id는 ['N', '<unk>', '$']들로서 이미 앞에서 준비가 되었다. sampling_size = 100은 100단어 문장을 생성한다는 의미이다. 메서드 generate의 skip_ids=None 은 상류의 클라스에서 데이터를 지정하여 흘려주면 받아서 처리가 이루어진다.
| 4 | class RnnlmGen(Rnnlm): def generate(self, start_id, skip_ids=None, sample_size=100): word_ids = [start_id] print('word_ids =', len(word_ids)) x = start_id print(x) |
start ID ‘you’로 시작하는 word_ids는 word_ids.append(int(x)) 명령 실행으로 +1만큼 증가한다. sample_size = 100이므로 len(word_ids) = 1부터 99까지 실행된다. 결과, start ID ‘you’에서 시작 확률적으로 연속 99개의 단어가 순차적으로 선정된다.
instance (self) 변수 score 점수를 계산하기 위해서 시작 단어 x는 (batch size, time size) = (N, T) =(1,1)로 강제 reshape 한 후 Rnnlm.py의 predict 메서드에 입력하여 순전파 연산을 하게되면 shape 이 (N,T,H) = (1,1,100), (1,1,100), (1,1,10000) 된다. 100은 은닉층 사이즈이며, 10000은 vocab_size이다. softmax 에서 10000개의 단어에 대해서 확률 계산을 하게 되는 것이다.
corpus를 load 하는 주소를 출력해보자(Anaconda 사례)
word_to_id 와 id_to_word를 출력하는 vocab_path를 출력해 보자(Anaconda 사례)
한편 메인인 generate_text.py를 실행시키면 가중치 및 기울기를 포함하는 이미 학습된 파라메터 데이터는 model을 상속하는 RnnlmGen 클라스의 인수인 Rnnlm 클라스의 메서드인 load_params를 사용하여 Rnnlm.pkl을 불러와서 처리된다.
| 1 | corpus, word_to_id, id_to_word = ptb.load_data('train') vocab_size = len(word_to_id) print('vocab size = ', vocab_size) corpus_size = len(corpus) print('corpus size = ', corpus_size) model = RnnlmGen() #model.load_params('../ch06/Rnnlm.pkl') 첫번째 사례에 해당 start_word = 'you' # start 문자와 skip 문자 설정 ------------------------------------------------------------ vocab size = 10000 corpus size = 929589 |
우선 첫 번째 사례를 고려해보자. 시작어를 ‘you’ 로 선정 후 word_to_id 를 출력해보면 316임을 알수 있다. 금지어 ['N', '<unk>', '$'] 는 [27, 26, 416] 이다.
| 2 | # start 문자와 skip 문자 설정 start_word = 'you' start_id = word_to_id[start_word] print('start_id = ', start_id) skip_words = ['N', '<unk>', '$'] skip_ids = [word_to_id[w] for w in skip_words] print(skip_ids) ------------------------------------------------------------ start_id = 316 [27, 26, 416] |
모델 즉 RnnlmGen 클라스의 generate 메서드를 사용하여 문장을 생성하기 위한 단어 id들을 생성하여 이들을 연결(join) 하자. <eos> 는 마침표 및 new line(.\n)으로 대체하도록 한다.
| 3 | # 문장 생성 word_ids = model.generate(start_id, skip_ids) txt = ' '.join([id_to_word[i] for i in word_ids]) txt = txt.replace(' <eos>', '.\n') print(txt) |
모델의 generate 메서드에서 어떻게 단어들을 생성시켜 끄집어내는지 살펴보자.
generate 메서드의 인수는 start_id, skip_ids, sample_size이다. start_id 는 ‘you’d[ 해당하는 ‘316’이고, 금지어를 뜻하는 skip_id는 ['N', '<unk>', '$']들로서 이미 앞에서 준비가 되었다. sampling_size = 100은 100단어 문장을 생성한다는 의미이다. 메서드 generate의 skip_ids=None 은 상류의 클라스에서 데이터를 지정하여 흘려주면 받아서 처리가 이루어진다.
| 4 | class RnnlmGen(Rnnlm): def generate(self, start_id, skip_ids=None, sample_size=100): word_ids = [start_id] print('word_ids =', len(word_ids)) x = start_id print(x) |
start ID ‘you’로 시작하는 word_ids는 word_ids.append(int(x)) 명령 실행으로 +1만큼 증가한다. sample_size = 100이므로 len(word_ids) = 1부터 99까지 실행된다. 결과, start ID ‘you’에서 시작 확률적으로 연속 99개의 단어가 순차적으로 선정된다.
instance (self) 변수 score 점수를 계산하기 위해서 시작 단어 x는 (batch size, time size) = (N, T) =(1,1)로 강제 reshape 한 후 Rnnlm.py의 predict 메서드에 입력하여 순전파 연산을 하게되면 shape 이 (N,T,H) = (1,1,100), (1,1,100), (1,1,10000) 된다. 100은 은닉층 사이즈이며, 10000은 vocab_size이다. softmax 에서 10000개의 단어에 대해서 확률 계산을 하게 되는 것이다.

Rnnlm 클라스의 메서드 self.predict(x)에 의한 score 계산을 추적해 보자. 앞 그림의 TimeEmbedding, TimeLSTM, Affine 순전파 연산을 하면 (shape (1,1,10000)의 score 값이 얻어진다.
| 5 | while len(word_ids) < sample_size: x = np.array(x).reshape(1, 1) print(x.shape) score = self.predict(x) print('shape of score =', score.shape) print('score=:', score) |
만약 Rnnlm.py에서 __init__ 메서드에서 생성된 임의의 랜덤 수로 채워진 가중치를 사용하여 첫 번째 변수 score를 계산한 후 flatten 명령을 사용하여 shape을 1차원화 하여 softmax에 입력한다. 얻어지는 출력은 shape이 (10000,)인 확률에 해당하지만 학습된 가중치 파라메터 값이 아닌 랜덤한 값으로 입력이 되었으므로 확률 값도 랜덤할 수 밖에 없으므로 이엉망인 확률로부터 random.choice 명령을 사용하여 선정되는 가장 높은 확률의 단어는 시작 단어 ‘you’와 무관할 수 밖에 없다. 계속 이어지는 다음 단어의 선택과정도 랜덤하게 되풀이되므로 생성된 문장은 랜덤한 단어의 선택이 될 수밖에 없다.
| 6 | p = softmax(score.flatten()) print('p shape:', p.shape) sampled = np.random.choice(len(p), size=1, p=p) print('sampled word: ', sampled) |
6장 LSTM에서 perplexity 값이 136 되도록 학습한 PTP 데이터 세트 학습 결과 가중치 및 기울기 파라메터를 사용하는 두 번째 사례를 고려해보자. load_params 메서드를 사용해 binary 파일로 저장했던 피클 파일 Rnnlm.pkl 을 불러 가중치 파라메터를 채워넣음으로서 Rnnlm 클라스의 __init__ 초기화 메서드를 사용할 필요가 없시 self.predict 메서드에서 순전파 연산을 직접 실행하여 제대로 된 확률 p 계산이 가능하다.
| 7 | model = RnnlmGen() model.load_params('../ch06/Rnnlm.pkl') |
generate_text.py 코드는 학습을 위한 코드가 아니라 이미 학습했던 데이터를 사용하여 필요한 확률 분포를 계산한 후 random.choice 명령을 사용하여 단어 선정 작업을 실행한다. 학습이 안된 경우는 단어 나열 수준이었지만 학습이 된 경우를 적용하면 꽤나 그럴싸한 문장들도 제법 목격이 된다.
첨부된 Colab 파일을 다운받아 실행시켜보자.
Under Construction ...
'인공지능 응용 공학' 카테고리의 다른 글
| Attention RNN 모델 (0) | 2023.02.03 |
|---|---|
| seq2seq RNN (0) | 2023.02.03 |
| Rnnlm 클라스를 사용 PTB 데이터세트 전체를 대상으로 학습시켜보자. (0) | 2023.02.03 |
| Simple Rnnlm 클라스를 사용한 학습에 관해서 살펴보자 (0) | 2023.02.03 |
| word2vec 알고리듬 CBOW 모델의 PTB(Pen Treebank) 데이터 세트 적용 (0) | 2023.02.03 |