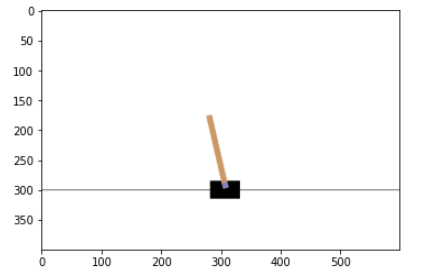
Frozen Break 에 이은 강화학습(reinforcement learning) 예제는 CartPole 이다. 이는 밸런싱 로봇과 같이 폴대를 넘어뜨리 않도록 하부의 대차를 적절히 움직여야 하는 PID 제어공학적 문제로 알려져 있으나 강화학습에서는 PID 제어와 같은 개념을 사용하는 것이 아니라 Cost 함수를 설정하고 최소화 해 나가는 과정일 것이다.이 블로그 내용은 인터넷 사이트에 올려둔 구글 Colab 코드 즉 GymRendering.ipynb (https://colab.research.google.com/drive/16gZuQlwxmxR5ZWYLZvBeq3bTdFfb1r_6#scrollTo=6L4YayzR4FYj)를 불러 그대로 실행해 보는 것으로 한다. 게임에서의 Reinforcement..