사용자가 신나게 키보드나 조이스틱으로 입력하는 게임을 생각할지는 모르겠으나 막상 컴퓨터 AI가 게임을 진행하기 위해서는 진정한 의미의 학습 또는 훈련이 가능한 AI 알고리듬이 필요할지도 모르겠다. 도대체 컴퓨터 화면 앞이나 또는 가상세계에서 하게 되는 게임의 진정한 특성은 과연 무엇인가?
수많은 게임들이 있지만 대개는 현재 상태로부터 액션을 계속적으로 가져가 목표 즉 Goal 을 달성하는 것이다. 아래의 Frozen Lake 게임도 에이전트가 호수(Lake) 라는 환경(Environment) 내에서 상하좌우로 안전하게(Safe) 한 스텝씩 움직여서 잘 얼어 있는 얼음(Frozen Lake) 지역을 통과하여 위험한 구멍(Hole)영역에 빠지지 않고 목표(Goal)에 도달하여야 보상(Reward)을 받게된다. 만약 구멍(H)에 빠지게되면 게임이 끝나고 다시 S에서 시작해야 한다. 제대로 경로를 알아내기 위해서는 이 게임을 여러번 되풀이해야 하므로 그때마다 목숨을 제공해 주어야 하며 목적지(Goal) 에 도달해도 다시 목숨 하나를 다시 받아서 S로부터 시작해야한다.

실제 게임에서는 위와같이 테이블이 보이지 않으므로 상당히 많은 시도를 해야 어디에 위험한 구멍들이 분포하는지 알아챌 수가 있는 것이다. 다음은 이 문제를 해결하기 위한 OpenAI 파이선 코드이며 해당하는 이론적 알고리듬을 보여준다. FrozenLake 전체 영역에서 정의되는 Q는 이산적인 조각영역의 위치와 아울러 액션 a 의 함수로서 이는 확률이나 보상은 아니지만 보상과 동질의 숫자로 표현이 가능하다.
이와같은 게임의 기본 알고리듬은 아래의 마코프연쇄(markov chain)의 일종으로 볼 수 있다. 즉 Agent가 현재의 상태 (St,Rt)를 가지고 다음 Action At 를 준비하여 환경(Environment)에 입력하면 Environment 는 다음 스텝의 (St+1,Rt+1) 을 Agent에게 되돌려 주게 된다. 하지만 게임의 과정이므로 여러번 되풀이 하여 소기의 목표를 달성하게 되면 게임이 종료되게 된다.

특히 루프를 돌 때마다 한번씩 목표(Goal)에 도달하게 되면 도달하기 위해서 움직이게 되는 인접 영역에서 보상을 받아 Q 값이 커지게 된다. Q 값을 결정하는 요인으로는 상태 s 즉 state 와 액션이 있으며 상태는 좌표 ( i, j) 로 표현이 가능하다.
많은 수의 루프를 돌게되면 각 영역들은 Q 가 업데이트되어 커진 영역으로부터 바로 인접한 영역에 인접한 영역에 합산됨다. max 값을 취해야 하는 이유는 어느 영역에서도 좌우 상하로 액션하게 됨에 따라 인접한 영역의 Q들이 다르므로 최대값이라는 방향성을 부여하도록 한다. 하지만 초기에 Q값들이 다같이 0 일 경우는 3방향이나 4방향으로 랜덤 액션이 일어난다.
OpenAI GYM 홈페이지의 Q learning 알고리듬을 나타내는 간단한 파이선 코드 구조를 살펴보자. 이미 GYM 라이브러리가 아나콘다에 설치되어 있다면 GYM 을 불러 들인다. OpenAI GYM 게임 중에 가장 기본적인 환경(Environment) 중에서 'FrozenLake-v1'을 호출한다. 홈페이지에는 업데이지 되지 않은 'FrozenLake-v0'로 되어 있으므로 교정하도록 한다.
적정한 수의 episode 수를 설정한다. env.render()는 여타 GYM 게임 실행 시 콘솔이나 셸 오의 별도 스크린을 띄워준다. 하지만 'FrozenLake-v1'에서는 셸에 S,F,H,G 를 사용한 텍스트 출력을 제공할 따름이다.
Environment에 액션을 가하고 이를 env.step()에 입력하면 observation, reward, done, info 가 얻어딘다. done은 게임이 성공적으로 끝났을 때 boolean True 를 출력해 준다. 이 코드에서 주의해야 할 점은 is_slippery=False 를 반드시 선언해야 출력에서 에이젼트가 움직인 방향 확인이 가능하다. 이러한 조건 설정은 게임의 속성이 불확실성이 높은(stochastic) 과정이 아닌 확정적(deterministic) 과정임을 뜻한다. 따라서 is_slippery=True 일 경우 실제 대단히 미끄러운 얼음판 조건이라면 미끄러지는 방향이 어느쪽일지 가늠하기 대단히 어려워질 것이다.
다음은 코드 내용을 간단히 보여준다.

위 코드를 알고리듬으로 정리하자.

이 코드의 gym.make에서 is_slippery=False 설정이 반드시 필요하다. 이 파라메터 설정이 없으면 출력에서 어느 방향으로 움직였는지 확인이 되지 않는다는 점에 유의하자. 다음 사례에서 처럼 막혀 있는 방향으로는 움직일 수 없으며 뚫린 방향으로만 이동을 확인할 수 있다. 첨부 코드를 실행해서 확인해 보자.

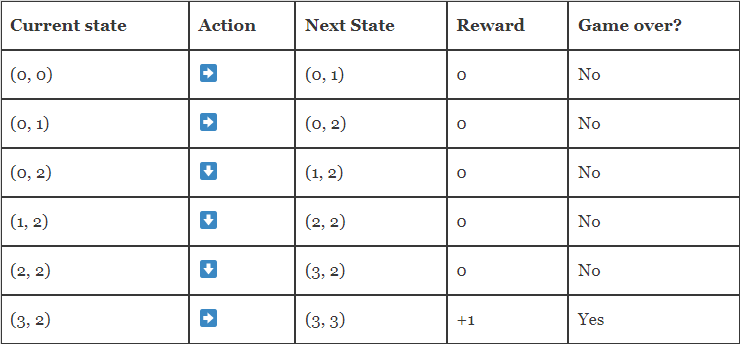
아래 표는 2회 액션을 통해 게임이 종료되는 상황이다.

아래 표는 6회 액션에 의해 Goal 에 도착하여 게임이 종료되는 에피소드 중의 하나이다.
다음 그림은 바로 위 테이블의 성공적인 에피소드의 학습 결과 사례이다.
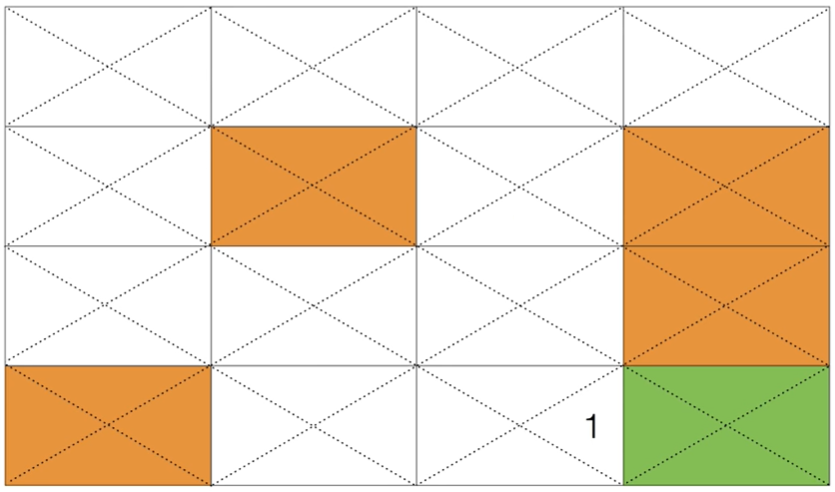
이와 같이 수많은 시행 착오를 통해 학습을 하게되면 다음과 같이 점차 Q값이 1 이 되는 경우가 확산되어 학습이 제대로 이루어진 Q 테이블 사례에 도달할 수 있을 것이다. 이외에도 훨씬 많은 수의 성공적인 경로를 찾을 수도 있을 것이다.

이 정도면 FrozenLake 게임 규칙 해설이 어느 정도 되지 않았나요?
다음 블로그 편에서는 이러한 게임규칙과 유사한 알고리듬으로서 Frozen Lake 대신 강화학습기반 자율주행을 연구하기 위해 “Taxi-v3” 모듈을 이용한 코드를 살펴보도록 하자.
#frozen_01.py
import gym
env = gym.make('FrozenLake-v1',is_slippery=False)
for i_episode in range(3):
observation = env.reset()
for t in range(100):
env.render()
#print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
#print(observation,reward,done,info)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
'강화 학습(Reinforcement Learning)' 카테고리의 다른 글
| 강화학습 Stochastic FrozenLake-v3 DQN (0) | 2022.01.07 |
|---|---|
| 강화학습 Stochastic FrozenLake-v3 Low Pass Filter 방식 알고리듬 적용 (0) | 2022.01.07 |
| 강화학습 Deterministic FrozenLake-v3 예제 게임규칙 (0) | 2022.01.06 |
| 강화 학습 Frozen Lake-v1 텍스트 출력 게임 (0) | 2022.01.05 |
| 강화학습(Reinforcement Learning) 코드작성을 위한 OpenAI GYM 라이브러리 설치 (0) | 2022.01.03 |