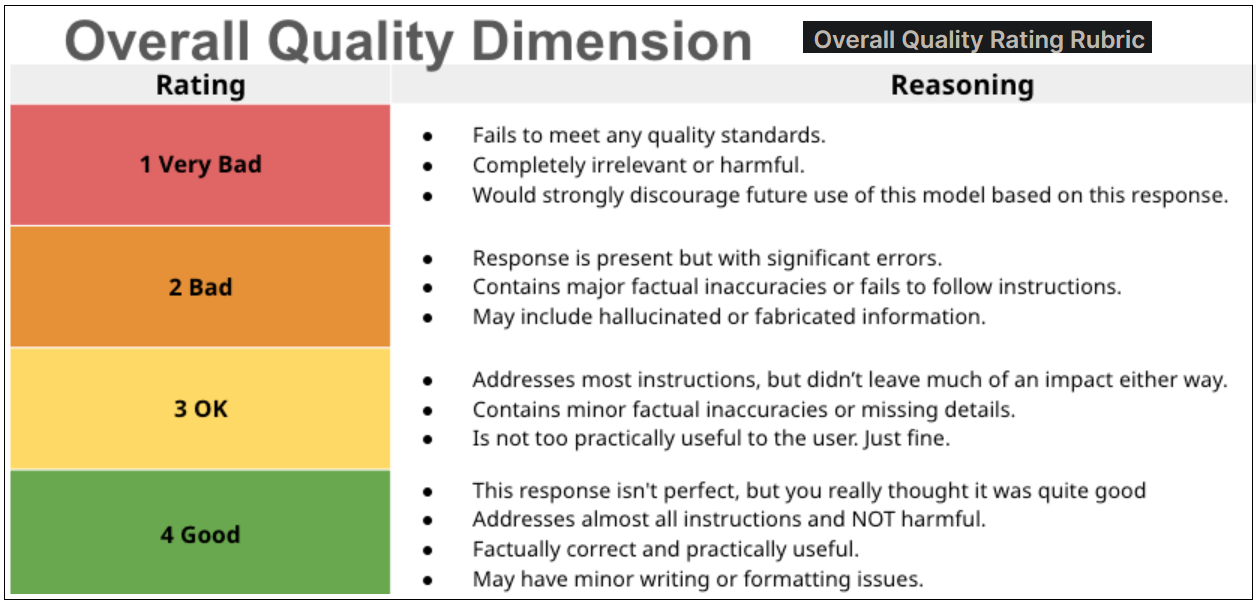
문제 개요아래의 Prompt 문제는 난이도가 높은 문제로서 Python 프로그래밍이 가능해야 풀 수 있는 문제이므로 문제 내용 자체 보다는 문제의 구조 설명과 응답 별 채점 포인트와 Justification 작성을 설명하기 위해 채택하였다. 실제 부과되는 task들은 99% 텍스트 기반 대화로 생각하면 된다.내용은 탑 1000 발리우드 영화 오픈 데이터셋을 처리하여 그래프를 작성하는 문제로서, 엑셀을 사용치 않고 파이썬의 그래픽 지원 라이브러리와 데이터 입력을 위해 pandas 라이브러리를 사용하여 처리하는 multi-disciplinary한 문제임을 참고하자. 응답 풀이 요령은 Prompt에서 주어진 사항을 잘 이행하여 visual 이 괜찮은 그래프를 출력하여 보여 주는 것이다.주어진 PromptTop..