다음 그림의 Simple CBOW 알고리듬에 의한 알고리듬을 살펴보면 입력 데이터의 은닉층 처리와 출력층 처리에 Matrix Multiplication 처리가 핵심적인 역할을 담당한다. Simple CBOW 알고리듬 학습과정 알고리듬을 코딩하려면 MatMul층에 대한 순전파(forward propagation)와 역전파(back-propagation) 연산이 필수적일 것이다. 순전파 연산은 메트릭스의 곱셈과 덧셈 연산을 이해하면 쉽게 코딩이 충분히 가능하지만 다층 구조에서 역전파는 합성함수의 편미분 값들을 체계적으로 연산할 필요가 있다.
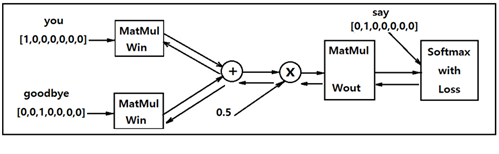
머신러닝에서 역전파 연산의 필요성은 웨이트 값들을 랜덤한 값으로 초기화하므로 Cost 함수가 취해야 할 최소값과는 큰 차이가 있다. 이러한 차이를 줄여 학습을 통해 Cost 함수를 최소화 하려면 웨이트 값들을 다음과 같이 지속적으로 업데이트 해야 할 필요가 있다.

이 업데이트 공식에서 lr 은 learning rate를 나타내며 일반적으로 0.1 이하의 작은 숫자 값을 나타낸다.
Cost 함수 L의 웨이트 메트릭스 W 에 관한 편미분 연산을 위헤서 class MatMul 의 Back-propagation 연산 알고리듬을 살펴보자.
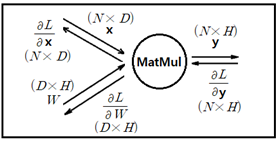

즉 y = xW 의 메트릭스 연산에서 x, y, W의 shape은 각각 (1xD), (DxH), (1xH) 로 주어진다. 특히 x 와 y는 열(row) 벡터로 주어진다.
위 다이아그램을 참조하여 다음과 같이 Cost(Loss) 함수의 편미분을 연산해 보자.
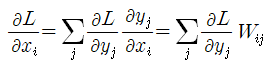
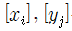
는 열벡터이므로 Cost 함수의 이들에 대한 편미분은 열 벡터가 된다. 윗 식에서 Cost 함수 L의 [yj]
에 대한 편미분과 웨이트 메트릭스 W 의 j 행과의 내적으로 연산 됨을 알 수 있다. 웨이트 메트릭스 W의 Transpose를 사용하여 다음과 같이 바꿀 수 있다.

이 식은 다음과 같이 간단한 메트릭스 형태로 쓸 수도 있다.

위 다이아그램을 참조하여 다음과 같이 또 다른 Cost(Loss) 함수의 편미분을 연산해 보자.
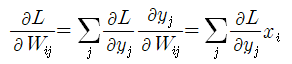
이 식은 다음과 같이 간단한 메트릭스 형태로 쓸 수도 있다. Wij 에서 i 는 열, j 는 행을 나타낸다.

앞에서 연산된 편미분들 중에 back-propagation 연산에 반드시 필요한 항목은 Cost 함수 L의 웨이트 W에 관한 편미분으로서 마이너스부호를 취하고 learning rate을 곱한 후 현재의 웨이트에 더하여 업데이트하여 사용한다.
이와 같은 Back-propagation 연산 수행을 위한 class MatMul을 구체적으로 코딩해보자. class MatMul 은 다음과 같이 3개의 메서드(method) 즉 init, forward, backward 로 구성된다.
초기화 메서드 init 에서 인스턴스 연산을 위한 변수 self.params는 상위루틴에서 제공되는 웨이트 W를 리스트화 한다.
인스턴스 연산을 위한 변수 self.grads는 웨이트 웨이트 메트릭스 W와 동일한 구조를 준비하여 0.0 으로 초기화 한다.
상위 루틴에서 제공하는 입력 데이터 x 는 아직 개수 즉 크기가 구체적으로 설정되지 않았기 때문에 차후에 결정할 수 있도록 None 으로 처리해둔다.
순전파 메서드 forward에서 상위 루틴으로부터 x를 제공받는다.
self.params를 W, 에 입력하여 1차원 shape 속성을 부여 받는다.
(※ 리스트 데이터 자체는 shape 속성을 가지지 않는다는 점에 유의하자.)
x와 W를 내적(dot)곱하여 순전파 출력 out을 계산한다.
입력 데이터 x는 인스턴스 변수 self.x 로 두어 이어지는 backward 루틴에서 받아서 사용한다.

인스턴스 변수들 self 와 상위루틴에서 제공하는 dout 값을 불러 온다.
인스턴스 변수로 넘겨받은 self.params를 W, 로 둔다.
상위 루틴으로 부터의 dout 과 Transpose W를 내적 곱하여 dx를 계산한다.
self.x의 Transpose 와 dout과의 내적곱 계산에 의해서 기울기(gradient)를 계산하고 dW 로 둔다. dW는 self.grads[0][...] 위치에 저장한다.
MatMul 연산 알고리듬을 사용하여 Simple BOW 알고리듬을 구성할 수 있지만 Corpus 즉 단어장에 포함된 단어수가 10만 100만으로 늘어나게 되면 MatMul 알고리듬 조차도 컴퓨팅 부담이 상당하기에 입력 데이터의 one hot 코드화에 의한 Embedding 알고리듬으로 개량이 필요하다. 세부적인 내용은 다음 절을 참조하자.
(참조: word2vec, CBOW (Continuous Bag of Words,
http://ejleep1.tistory.com/1432)
첨부된 코드를 다운 받아서 Colab에서 실행시켜보자.
'자연어처리' 카테고리의 다른 글
| Attention RNN 알고리듬에서의 shape 변경 기법 (0) | 2023.01.20 |
|---|---|
| word2vec, CBOW (Continuous Bags of Words) (0) | 2023.01.03 |
| IMDB 영화 리뷰 데이타 베이스 Sentiment 분석 (0) | 2022.12.19 |
| 한글 자연어 처리 KoNLPy 설치 (0) | 2022.07.04 |
| IMDb 영화등급 설정 파라메터 연구 사례 (0) | 2022.07.03 |