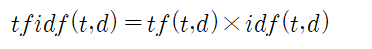수많은 영화들이 성공적 흥행을 목표로 쏟아지고 있는 미디어 세계에서 개봉 이전에 광고 중인 영화의 등급(rate) 예상에 관한 사례를 살펴보자. IMDb 영화 리뷰에 의한 학습 및 테스트에서처럼 개봉 이후 충분히 확보된 영화 리뷰 결과를 사용하여 머신 러닝 시키는 경우도 있겠지만 반면에 본능적인 평가를 택하는 경우도 있을 수 있다. 하지만 지금도 수없이 쏟아지는 영화들에 대해서 영화 리뷰 데이터나 본능을 배제하는 좀 더 괜찮은 방법은 없을까? IMDb를 대상으로 하는 (실제 사례)를 소개하기로 한다. 대략 내용은 IMDb 웹 사이트 접근법 및 데이터 수집 방법을 제시한다. 아울러 수집된 포스터 데이터를 대상으로 안면인식 알고리듬을 적용하여 배우 수를 추적하고 배우 수를 파라메터로 하여 영화 등급 설정과의..