영화리뷰 데이타 세트가 준비되었으면 준비된 텍스트의 집합체를 어떻게 개별 단위의 토큰으로 쪼갤 것인지 하는 문제를 생각해 보자.
문서를 토큰화 하는 방법은 앞장에서 처리했던 클리닝한 문서 데이타(cleaned documents)를 대상으로 여백을 중심으로 단어를 쪼개는 것이다. 그러한 목적을 달성하기 위한 함수도 작성해야 하지만 아울러 아나콘다 TensorFlow 가상환경에 PyPrind에서 처럼 귀찮지만 라이브러리를 설치해야 한다는 점이다. 이미 경험이 있으면 아래 내용을 일독 후 10분 이내에 처리할 정도의 코딩 실력을 갖추도록 하자.

토큰화 관점에서 또 다른 유용한 기법으로서 word stemming 알고리듬이 있는데 이는 단어의 변환 과정애서 어근(root)을 찾아 내는 것이다. 원조 어근 알고리듬은 1979년에 Porter가 연구했으며 Porter stemmer 알고리듬으로 알여져 있다. 다음의 예제를 통해서 어근을 찾아내는 사례를 관찰해 보자.
이 예제를 연습하려면 nltk 라이브러리 모듈을 텐서플로우와 파이선이 설치된 아나콘다에 설치해야 한다. 그 이유는 이 라이브러리가 Numpy 와 함께 사용되는데 Numpy가 TensorFlow 버츄얼 환경에 함께 바인딩 되어 설치되어 있기 때문이다.
설치 방법은 압축 파일을 http://www.nl.tk.org 에서 윈도우즈 사용자 폴더에 다운 받은 후 윈도우즈 명령 창에서 압축을 해제하자.

3번 항을 클릭하여 NLTK 다운로드 사이트로 이동하자.

Download files 버튼을 클릭하여 nltk-3.4.zip 파일을 윈도우즈 바탕화면 사용자 폴더에 다운로드 받는다.

윈도우즈 명령 창에서 바탕화면의 사용자 폴더에 nltk-3.4.zip 파일이 다운로드 되었음을 확인한다.

윈도우즈 명령 창에서 다운로드 받은 파일이 확인되었으면 마우스 오른쪽 버튼 압축해제 기능을 사용하자.
이어서 아나콘다 명령 창을 열도록 하자.
(base) C:\Users\Ysc>conda activate tensorflow
아나콘다 명령 창에서 tensorflow를 activation 시키면 프롬프트 즉 (tensorflow)가 나타난다.

여기서 pip install nltk 명령을 실행시킨다. conda list 명령을 실행해 보면 pip 이미 설치되어 있음을 확인할 수 있다. 아나콘다도 항상 업그레이드 되고 있으므로 항상 pip 도 업그레이드 할 것인지 노란색으로 물어보는데 완료 후 업그레드 해둬도 무방할 것이다.

셸(Shell)애서 다음 명령을 실행하여 아무런 에러 메시지 없이 넘어가면 성공적으로 설치된 것이다.

다음의 porter_stemmer.py 코드를 아나콘다 스파이더에서 미리 실행 시키자,
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
def tokenizer_porter(text):
return [porter.stem(word) for word in text.split()]
셸에서 다음 예제를 실행시키면 어근 처리한 결과가 얻어진다.

running 의 어근은 run 이며, thus의 어근은 thu 이다.
이와 같이 cleaned text를 대상으로 토큰화 하되 어근을 찾아서 필터링하는 기법이 있을 수 있는 반면에 stop-words removal 이란 기법도 있다. stop-words 란 tfidf에서 검토했던 ‘is’ 사례처럼 많이 사용되지만 특별한 의미가 없는 단어나 텍스트를 의미한다. 즉 부여된 class 가 서로 다른 문서들 사이에서 문서들의 class를 식별해 내는데 그 다지 도움이 되지 않으면서 특별한 정보가 결핍되어 있는 극도로 공통적인 단어들을 뜻한다. stop-words 의 예로는 ‘is’, ‘and’, ‘has’, ‘like’ 와 같은 단어들이 있다. 텍스트 문서를 대상으로 하는 작업에서 stop-words 제거는 tfidf 값 단계에서 머무르는 것이 아니라 빈번하게 나타내는 단어들에 대해서 이미 경감처리가 된 즉 normalization이 이루어진 단어 빈도수를 가지고 작업할 경우에 아주 유용하다.
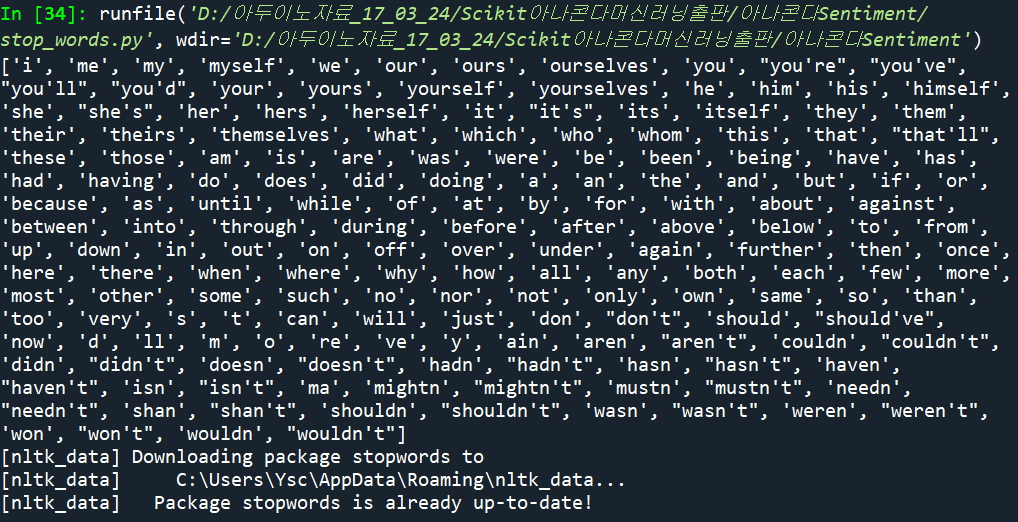
영화 리뷰 파일에서 stop-words를 필터링 해버리기 위해서는 NLTK 라이브러리의 127개 영어 단어로 이루어진 stop-words 세트를 사용하도록 한다.
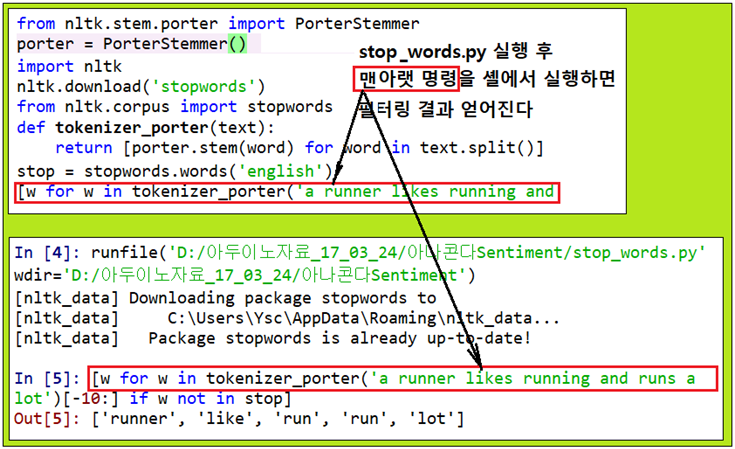
stop words 란 서로 다른 종류의 문서들을 구분함에 필요한 정보 제공이 될 수 없는 지극히 평법한 단어들로서 아래의 출력을 참조해 보자.
이어지는 내용은 로지스틱 함수를 사용하여 문서들을 학습 후 테스트 하는 과정 즉 본론이 대기하고 있다.
#stop_words.py
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
def tokenizer_porter(text):
return [porter.stem(word) for word in text.split()]
stop = stopwords.words('english')
[w for w in tokenizer_porter('a runner likes running and runs a lot')[-10:] if w not in stop]
'자연어처리' 카테고리의 다른 글
| 한글 자연어 처리 KoNLPy 설치 (0) | 2022.07.04 |
|---|---|
| IMDb 영화등급 설정 파라메터 연구 사례 (0) | 2022.07.03 |
| Sentiment 분석에 불필요한 텍스트 데이터 클리닝 (0) | 2022.07.01 |
| tf-idf 단어 관련성 분석 (0) | 2022.07.01 |
| Bag of Words(단어장)에 의한 feature vector 생성 (0) | 2022.07.01 |