seq2seq RNN 모델에서 인코더 알고리듬을 개량해 보자. 앞서 기술된 인코더 구조에서는 마지막 LSTM 셀로부터 출력되는 은닉층 정보 h 가 디코더의 LSTM 첫 번째 셀에 전달하는 단순한 구조를 보여주었다.
개선 이전의 인코더에서는 문장 전체를 쪼개서 각각의 LSTM 셀에 입력하여 은닉층 연산 후 펼쳐진 마지막 LSTM 셀에서 출력되는 은닉층 정보 h 를 디코더에 입력했었다. 개선 후에는 인코더 각각의 LSTM 셀로부터 출력되는 은닉층 정보를 모은 h 를 디코더에 입력하는 방법이다. 이렇게 하면 인코더 sequence 의 ‘고정길이’라는 제약을 벗어날 수 있다. 즉 마지막 LSTM 하나의 셀에서 결과를 넘기는 것에 비해 입력데이터 수에 해당하는 만큼의 은닉층 정보 전체를 전달하므로 고정된 길이의 벡터라는 제약을 벗어날 수 있다는 뜻이다.

현재의 LSTM에 대한 입력 방향은 왼쪽에서 오른쪽으로 설정되어 있지만 방향성에 의한 치우침으로 인해 벡터 h 형성에 불균형이 초래할 수도 있으므로 양방향 (bidirectional) 알고리듬을 사용하여 해소할 수도 있다.
두 번째 개선안은 인코더로부터의 은닉층 정보 h 를 디코더의 LSTM 레이어에 입력하는 방법 개선안이다. 즉 첫 번째 개선안에 따라 출력하여 준비한 은닉층 정보 h 를 디코더의 첫 번째 LSTM 레이어에 직접 입력하는 것이 아니라 아래 그림에서처럼 디코더 각각의 LSTM 레이어와 이어지는 Affine 레이어의 입력에 합산(concatenation)하여 디코더 전체에서 활용하도록 하는 것이다. 이와같이 은닉층 정보 h 를 Affine 레이어에서 공유 처리함으로 인해 번역의 경우 효율이 상당히 개선될 수 있다. 다음 그림에서의 이러한 기법을 Peeky seq2seq 알고리듬이라고 한다.
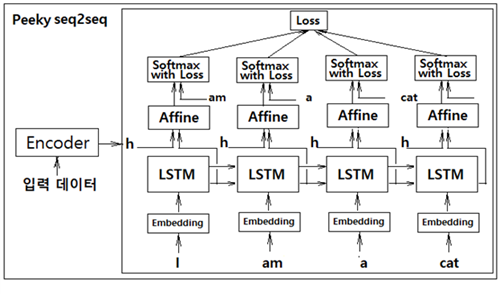
Peeky seq2seq 알고리듬의 번역 성능을 더욱 높이기 위해서는 인코더에서 준비하는 은닉층 정보의 모음 hs 에서 예를 들자면 ‘나=I’, ‘고양이=cat’ 과 같은 명백한 관계에 주목(attention)할 필요가 있으며 이 정보를 디코더에 어떤 방식으로 넘겨주느냐는 문제로 귀착된다.
인코더의 마지막 LSTM 셀로부터의 은닉층 정보는 이 예제에서는 h4 에 해당한다. 이 결과물은 그대로 디코더의 첫 번째 LSTM 셀에 입력하도록 하자. 아울러 인코더 각각의 LSTM 셀의 은닉층 정보 h1, h2, h3, h4 를 모아 둔 hs 는 디코더 각각의 LSTM 셀에서의 은닉층 정보 출력과 함께 연산 레이어에 입력하자. 이 연산 레이어는 인코더 은닉층 정보 hs 와 각각의 LSTM 셀에서의 은닉층 정보 출력과 상관관계가 높도록 어떤 연산 즉 attention 레이어를 수행해야 할 것이다. 자연어 처리에 있어서 대부분의 레이어는 순전파 Affine 레이어와 그 편미분에 의한 역전파 레이어로 구성되지만 attention 레이어는 디코더 입력과의 연관성을 추출 하기 위한 다소 특별한 알고리듬 도입이 필요하다.
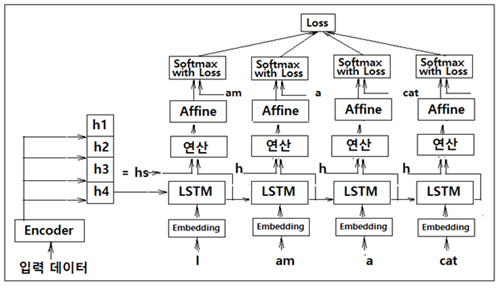
인코더의 각 LSTM 셀로부터 얻어지는 은닉층 개별 정보 hi(h1, h2, h3, h4)는 위 그림과 같이 은닉층 사이즈 크기로 출력이 될 것이며 아무래도 각 LSTM 셀의 상류 레이어 상에서 각 입력 데이터의 특성을 가장 많이 반영하게 될 것이다.
인코더로부터의 모든 은닉층 정보 hs 의 성분 각각에 대해 각 단어의 중요도를 나타낸다고 볼 수 있는 적절한 가중치 a 를 곱하자. a 는 각 성분이 0.0 ~ 1,0 사이 값을 가지며 합이 확률분포처럼 1.0 이 된다고 가정한다. 곱셈 후 axis=0 을 기준으로 합산하여 압력 데이터 수만큼의 성분을 갖는 벡터 C 를 얻는다.
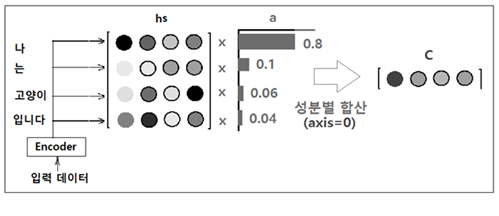
이 그림에서 a 의 첫 번째 중요도 성분이 0.8이라고 하는 것은 입력 데이터 “나‘에 대응하는 가중치가 0.8로서 벡터 C 에 가장 많이 반영되었다는 의미이다.
디코더의 LSTM 은닉층의 출력을 h 라 할 때 과연 이 h 가 hs 의 각 단어 벡터와 얼마나 유사한지 평가하기 위해 dot 연산에 의해 스코어 s 를 계산 후 softmax를 사용 정규화하여 가중치 벡터 a 로 두자. 가중치 a 벡터와 hs 를 곱셈 연산하여 최종적으로 C 벡터를 생성하는 이 알고리듬을 Attention이라 한다.
아래의 계산 그래프를 참조하여 가중치 a 벡터 연산 과정을 살펴보자.
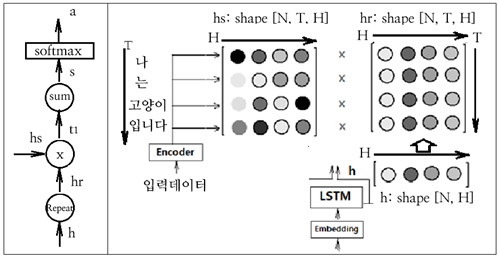
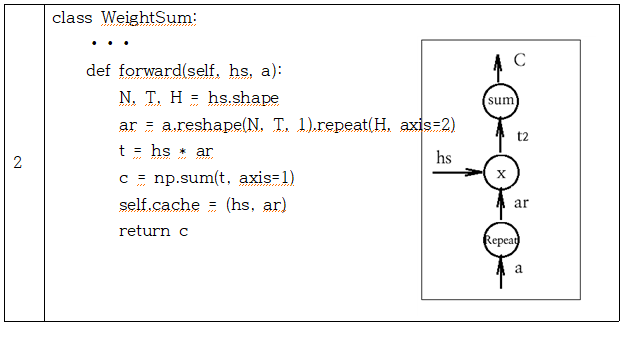
decorder 의 각 LSTM 셀에서 생성되는 h 의 shape 은 [N, H] 이다. encoder 로부터 입력되는 hs 의 shape [N, T, H] 와 같아지도록 shape 이 [N, H] 인 h 를 axis=1을 기준으로 반복 복제하여 shape 이 [N, T, H] 인 hr 을 구한다. 동일한 shape을 가지는 hs 와 hr 을 곱하여 역시 shape 이 [N, T, H] 인 t1 을 계산한다. t1 에서 axis=2 즉 H에 대해 합산(sum)하여 [N, T] 로 reshape 하여 스코어 s 로 둔다. s 를 softmax 처리하여 확률과 유사하게 정규화하여 shape 이 [N, T] 인 가중치 a 로 두자. 이 연산 과정을 AttentionWeight 클라스로 선언하자.
| 2 | class WeightSum: ⦁⦁⦁ def forward(self, hs, a): N, T, H = hs.shape ar = a.reshape(N, T, 1).repeat(H, axis=2) t = hs * ar c = np.sum(t, axis=1) self.cache = (hs, ar) return c |
Attention 알고리듬에 의한 seq2seq 코드 작성은 기존의 seq2seq 알고리듬에 attention 처리 부분을 추가하면 되는 구조임에 유의하자.
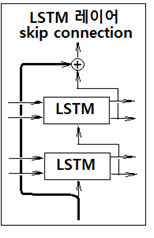
Attention 레이어의 설치는 앞서 설명한 간단한 구조 외에도 다양하게 변형된 패턴을 사용하여 상류 방향으로 여러 층의 LSTM 셀을 추가할 수 있다. 특히 다층 LSTM셀 추가에 따라 기울기의 소실 또는 폭발 문제를 야기할 수 있기때문에 skip 레이어를 설치하기도 한다.
레이어 하나를 건너뛰면서 정보를 전달하기 때문에 역전파에서 + 연산 노드는 기울기 데이터를 그대로 흘려 전달하기 때문에 기울기 소실이나 폭발의 우려를 최소화 할 수 있는 이점이 있디. 이 skip 레이어는 ResNet 처럼 레이어 수가 엄청나게 많을 경우에 중간에 많이 적용하여 기울기 문제 완화에 큰 효과를 볼 수 있다.
Attention RNN 실행코드 train.py(ch8 참조)에서 코드 즉 클라스 명령들을 불러 오는 순서를 살펴보자.
메인코드 train.py에서 데이터를 입력하여 순서를 반전시키자.
하이퍼 파라메터들을 설정하고 AttentionSeq2seq model을 선언한다. Adam 옵티마이저를 지정하여 Trainer 클라스에 인수로 제공한다.
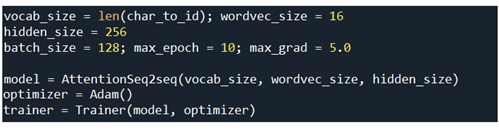
trainer 클라스의 메서드 fit을 사용하여 학습을 시킨다.

학습 과정에서 epoch 별로 미니배치 즉 batch_size 만큼씩 순전파 연산에 의해 loss를 계산하고 이어서 역전파 연산을 실행한다.
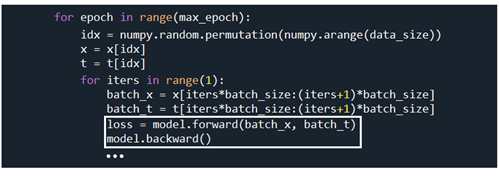
model.forward 에 해당하는 AttentionSeq2seq.forward 를 살펴보자. AttentionSeq2seq 클라스에 메서드 forward 가 나타나 있지 않으므로 self.encoder 즉 AttentionEncoder(*args) 내부 메서드를 살펴보자.
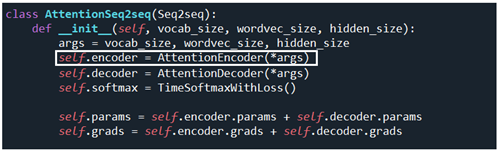
AttentionEncoder(*args) 클라스에서 인수가 Seq2seq 클라스가 제공하는 메서드 Encoder 임에 유의하자. 하지만 AttentionEncoder 클라스에서는 별도로 초기화 메서드가 없으므로 그 대신에 Encoder 메서드의 일부가 우선적으로 실행되는데 그것은 바로 초기화 과정이다. 즉 Encoder 의 __init__ 만이 재사용되고 forward 나 backward 는 AttentionEncoder 의 그것과 다르므로 사용되지 않는다.

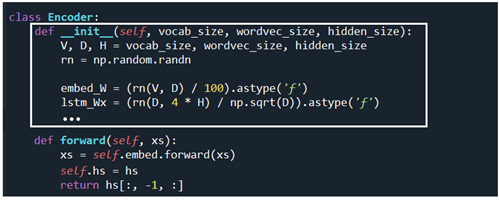
아래의 Encoder 클라스에서는 __init__ 메서드 만 실행하고 이어지는 메서드 forward 즉 decoder 의 첫 번째 LSTM 셀에 넘겨주기 위한 encoder 마지막 LSTM 셀로부터 h 를 계산하는 메서드인데 여기서는 실행되지 않는다. encoder 의 초기화 메서드가 실행된 다음 순서는 바로 앞서 설명했던 AttentionEncoder 클라스에서 볼 수 있듯이 xs = self.embed.forward(xs) 및 hs = self.lstm.forward(xs) 연산이 이루어져 hs 가 연산된다. hs 에는 이미 hs[:, -1, :] 가 포함되어 있다.
model.forward에서 1차로 encoder 초기화와 AttentionEncoder(*args) 의 메서드 forward 가 우선 실행된 후 이어서 AttentionDecoder(*args) 의 초기화와 forward 연산이 뒤따르게 된다.
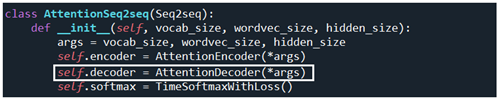
AttentionDecoder 클라스의 초기화를 살펴보면 기존의 decoder 에 비해 3번째에 self.attention 레이어가 추가되어 있음을 알 수 있다.
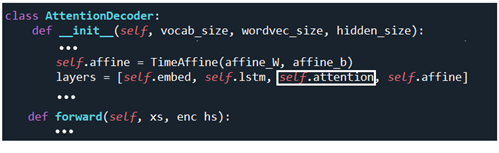
아울러 AttentionDecoder 클라스의 forward 순전파 연산에서도 기존의 h[:, -1,:] 대신에 encoder의 각 LSTM 셀에서 연산되는 h 들의 모음인 enc_hs 가 사용됨을 알 수 있다. AttentionEncoder 의 forward를 살펴보면 순전파 연산 결과인 hs 를 어디론가 반환하는데 코드 상 반환받는 주체가 명시되어 있지 않는 것으로 보아 AttentionDecoder.forward 의 enc_hs 가 바로 그 대상으로 보인다.
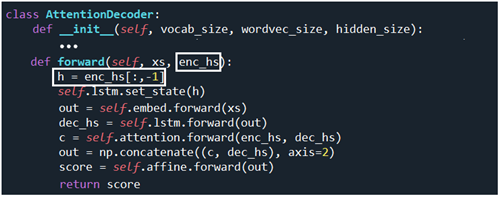
코드 구조가 다소 복잡한 편이므로 초보자가 직접 코드를 작성하기는 어려우나 그 흐름을 잘 파악하면 코드 수정작업은 용이해질 것이다.
'자연어처리' 카테고리의 다른 글
| 생성형 AI 초기 채점 업무 시 예제 사례와 알아야 할 요령 (2) | 2024.06.23 |
|---|---|
| 생성형 AI 가 제공하는 Response의 6. Overall Quality Rating 평가 (0) | 2024.04.30 |
| Attention 알고리듬 이해를 위한 Sequence To Sequence 알고리듬 (0) | 2023.03.05 |
| 생성형 AI 언어 모델(LLM: Large Language Model) 입문 (0) | 2023.03.05 |
| ChatGPT로 살펴보는 새로운 경쟁 (0) | 2023.01.23 |