문제 개요
아래의 Prompt 문제는 난이도가 높은 문제로서 Python 프로그래밍이 가능해야 풀 수 있는 문제이므로 문제 내용 자체 보다는 문제의 구조 설명과 응답 별 채점 포인트와 Justification 작성을 설명하기 위해 채택하였다. 실제 부과되는 task들은 99% 텍스트 기반 대화로 생각하면 된다.
내용은 탑 1000 발리우드 영화 오픈 데이터셋을 처리하여 그래프를 작성하는 문제로서, 엑셀을 사용치 않고 파이썬의 그래픽 지원 라이브러리와 데이터 입력을 위해 pandas 라이브러리를 사용하여 처리하는 multi-disciplinary한 문제임을 참고하자.
응답 풀이 요령은 Prompt에서 주어진 사항을 잘 이행하여 visual 이 괜찮은 그래프를 출력하여 보여 주는 것이다.
주어진 Prompt
Top_1000_Bollywood_Movies.csv 오픈 데이터 세트가 주어졌습니다. 최고 수익 상위 10개 영화에 대한 'WorldWide'와 'India Net' 흥행 수익 간의 관계를 시각화하는 그래프를 작성주세요. 각 영화는 기본 y축에 'WorldWide' 수익이, 보조 y축에 'India Net' 수익이 있는 데이터 포인트로 표시되어야 합니다. 또한 세 번째 y축을 추가하여 이러한 영화의 'Budget'을 꺾은 선형 챠트로 나타내주세요. 각 데이터 요소에 영화 이름으로 레이블을 지정하고 범례, 제목과 명확한 축 레이블을 제공해주세요. 'India Net' 수익을 기준으로 영화를 내림차순으로 정렬하고 줄거리에 'Verdict'이 'All Time Blockbuster' 또는 'Blockbuster'인 영화만 포함하도록 합니다.
Chatbot 이 생성한 Response 1 과 Response 2
Response 별로 채점 기준 적용은 동일하다.
Overall Quality 의 위치가 맨 앞에 있으나 각 항목 별 채점이 끝난 후 마지막에 하는 것이 원침임에 유의하자.
Correctness는 Truthfulness 또는 Accuracy 와 대등한 개념이다.
Completeness 는 Instruction Following 과 대등한 개념이다.
채점 점수 차가 발생하게 되면, 3점 만점이 아닌 감점 항목들에 대해서 판정(Justification)란에서 영어로 간단히 빠짐없이 지적한 후 최종 어느 응답이 우수(better), 훨씬우수(much better)한지 등의 판정 결과를 영문으로 작성하여 제출해야 한다. 번역기가 더 빠르면 얼마든지 사용해도 좋다.

① 이 과제에서 첫번째 채점 항목은 Overall Quality 로서 5점 기준에 읽어보고 글이 괜찬으면 대체로 3점을 부여하면 아무런 문제가 없다. 완벽하면 1점(Amazing, Excellent)으로 판단하면 된다. 완벽이란 토씨, 맞춤법, 띄어 쓰기 및 분석내용까지도 모조리 포함하므로 5점(Horrible)의 경우는 거의 없는 편이며 대충 3점(Okay, Adequate) 부여하면 되는데 그 대신 따라오는 채점 항목에서 트집(troubles)을 잡아 약간 감점해야 한다.
4점(Pretty Bad)은 언제 부여하느냐는 Prompt에서 해달라는 내용 지시사항(instructions following)을 응답에서 제대로 하지 않을 경우다. 또는 구체적인 내용은 없고 실재하는 웹 주소 URL's 만 찾아 놓은 경우이다. 이따위 생성형 AI는 말을 듣지 않는다는 것이므로 쓸모가 없어 철저히 가려내어 체크해야 한다.
5점(Horrible)은 Prompt에 대한 응답이 완전한 헛소리(gibberish)이거나 기존 ChatGPT나 Gemini에서 표절했거나(소프트웨어로 체크 가능) 욕설(Profane)이거나 유해하거나(harmful) 불법적인(Illegal) 내용이거나 인종/성 차별 같은 선입관념(Biased)이나 고정관념(Stereotyped)이거나 민감한 개인정보(PII)를 시 에 해당한다.
5점의 경우 분석 여지가 없으며, 폐기 대상이므로 거의 출제 되지 않는다.
② Correctness 는 데이터의 경우(날짜, 값, 액수 등) 숫자가 정확히 맞는지 여부를 뜻하며, 내용이나 진술의 경우 fact 또는 false 인가 여부이다.
Chatbot 이 속임수로 착각할듯한 엉뚱한(hallucinate) 문장 생성이 가능하므로 10분 이내 범위에서 구글링이나 네이버링을 통해 확인할 필요가 있다. 채점에서 가장 중요한 요인이다.
③ Writing Quality 는 대부분 문법적인 요소들 즉 철자, 맞춤법, 띄워쓰기, 문장 구조를 체크해야 한다. 사소한 철자 오타등은 마이너(minor)하므로 2점을 부여한다. 전 후 문장 관계가 바뀌었다든지 좀 심한 경우는 당연히 메이저(major) 급이므로 3점을 부여한다. 깨끗하면 1점(No issues)이다.
한편 Prompt에서는 경어로 물어봤는데 응답에서 반말을 씉다면 이는 한국 사회에선 외국인 빙자 코미디를 제외하고는 있을 수 없는 톤(tone) 문제인데, 이때는 Overall Quality 도 2점(Pretty Bad)으로 감점 수정해야 한다.
⓸ Verbose는 응답이 얼마나 장황한가? 즉 내용은 쬐끔이고 같은 말 반복이 심하고 서두나 끝에 알맹이가 없어 불필요한 껍데기성 멘트가 있어 핵심을 많이 갉아먹으면 3점 Too short 이다.
동일한 입력 Prompt에 대해서 chatbot 은 서로 다른 응답을 줄 수도 있지만 읽어보는 사용자 입장에서 어느 한 편이 나을 수도 있으며 때로는 거의 비슷할 수도 있다.
Prompt에서 주어진 문제의 경우 처리된 그래프를 살펴보면 응답 1은 결과가 나오긴 했으나 그래프 보기가 visual이 껄끄럽게 처리되었고 응답 2는 산뜻하게 처리되었다. 분명한 차이가 나므로 'better' 로 찍는다.
응답 1은 엄청 복잡한 코드를 사용하였지만 (내가 실행 시켜보니 돌지도 않았음) 초라한 비주얼의 그래픽 결과를 주었다.
응답 1은 그래픽 결과 조차도 뭔가 틀린 듯하다.
응답2가 응답 1보다 훌륭하다.
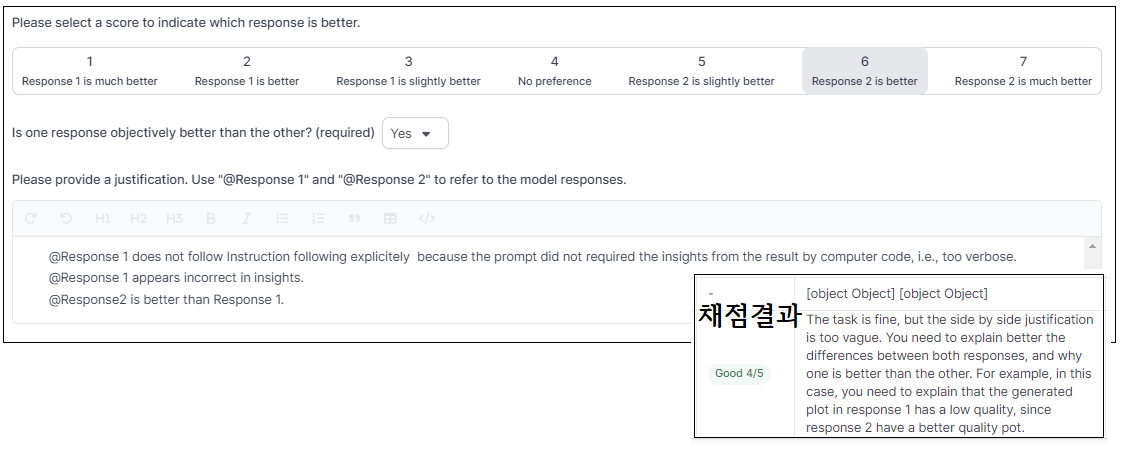
채점 결과를 보니 각 응답별 side by side 채점 결과가 너무 모호하게 처리되었다고 한다.
상기의 예제를 참조하면 초기에 Outlier에서 훈련과제 처리 시에 다소 도움이 될 것입니다.
'자연어처리' 카테고리의 다른 글
| 생성형 AI 가 제공하는 Response의 6. Overall Quality Rating 평가 (0) | 2024.04.30 |
|---|---|
| Attention RNN 모델과 코드 구조 (0) | 2023.03.13 |
| Attention 알고리듬 이해를 위한 Sequence To Sequence 알고리듬 (0) | 2023.03.05 |
| 생성형 AI 언어 모델(LLM: Large Language Model) 입문 (0) | 2023.03.05 |
| ChatGPT로 살펴보는 새로운 경쟁 (0) | 2023.01.23 |