이 블로그는 한빛 출판사에서 출간된 사이토 고키 저 "Deep Learning from Scaratch ⓶ 밑바닥부터 시작하는 딥러닝 2편" 의 7장 2절 seq.seq 의 세부 해설이다. 자연어 처리에 관심이 있는 국내 독자라면 그 내용의 뛰어남에 필독을 권해 본다.
하지만 제목에서 '밑바닥부터...'가 암시하듯 이 책은 철저하게 바텀업 방식으로 씌어졌으며 논리상 아무런 문제가 없다고 볼 수 있다. 하지만 개개인의 자연어 처리에 대한 이해도가 낮을 경우 다음과 같은 문제가 발생함을 지적해 둔다.
책 후반인 7장에서 seq2seq 를 읽고 코드를 실행시키다 보면 바닥에서의 기본적인 알고리듬들이 잘 보이지도 않고 이해가 제대로 되지 않는 경험을 할 수도 있다. 즉 7장의 내용은 그 앞까지 전개해 온 내용을 Top Down 개념으로 내려다 봐야 한다는 점이다. 코드를 관찰하는 방향이 변화되어서 인지 세부적인 사항들이 전혀 감이 잡히지 않는다는 점이다.
이런 논점은 자연어 처리에서 중요한 알고리듬인 LSTM 에서 long term 메모리 효과를 상기시키기도 한다. 즉 바텀 업 과정에서 후반에 출현하게 될 알고리듬들을 의식하며 미리 미리 언급을 한다든지 또는 중간에서 바텀업 과정에서 지적했던 사항들을 일깨워 주든지 해야 seq2seq 알고리듬의 완전한 이해가 보다 쉬워질 것이다.
sequenc to sequence 알고리듬 코드의 이해를 위해서는 인위적으로 적은 수의 입력 데이터와 작은 값을 가지는 하이퍼 파라메터들을 사용하여 첫 초기화 단계를 중심으로 출력해 보는 기법을 사용하여 살펴 보자. 이러한 방법으로 코드 구조가 충분한 이해 되었다면 주저없이 충분한 규모의 입력 데이터와 현실적인 하이퍼 파라메터들을 사용하여 코드를 실행시키도록 하자. 아울러 sequenc to sequence 알고리듬 코드의 이해가 중요한 이유는 바로 attention 및 transformer 알고리듬 응용으로 넘어가는 전단계에 해당하기 때문이다.
메인 코드인 train_seq2seq.py 에서 학습 코드를 살펴보자. import 하는 sequence.py, trainer.py, 실행에 주목하자. trainer.py 에서는 Trainer 클라스, seq2seq.py 에서는 Seq2seq 클라스 사용에 주목하자.
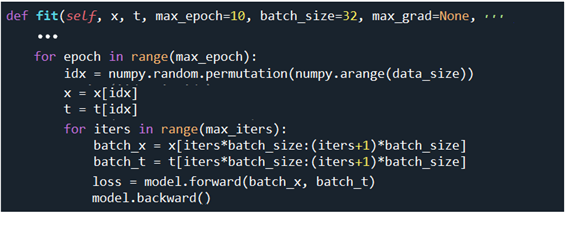
seq2seq.py에서 데이터세트를 읽어 들이기 위해서 sequence.py에 포함된 메서드 load_data를 사용하여 즉 addition.txt를 읽어들인다.

sequence.py 에서는 질문에 해당하는 questions 와 정답에 해당하는 answers를 문자 텍스트로 입력받아 ’+‘ 포함 문자 7개와 ’-‘포함 해답 5글자를 padding 까지 고려하여 처리한다.
메인 코드인 train_seq2seq.py 에서 학습에 필요한 model 을 선언하도록 한다. 즉 seq2seq.py 에 포함되어 있는 Seq2seq 클라스를 model로 선언하고 학습을 위한 trainer.py에 포함되어 있는 Trainer 클라스에 인수로 옵티마이져 ’Adam’과 함께 제공한다.
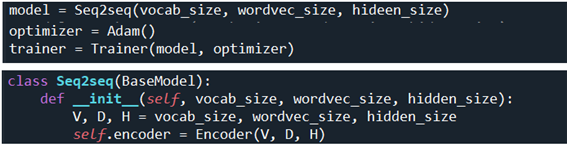
한편 model 즉 Seq2seq 선언과 아울러 아래와 같이 초기화가 이루어지게 된다.

초기화 과정을 살펴보기 위해 Encoder 와 Decoder를 들여다 보면 time_layers.py 의 TmeEmbedding을 호출하고 있음을 알 수 있다.
Encoder
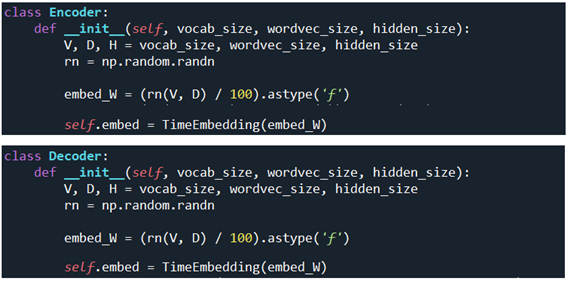
TimeEmbedding 에 출력문을 넣어서 실행해 보면 Encoder 및 Decoder 가 각각 호출에 따라 랜덤수로 초기화된 3X13 리스트 데이터가 출력됨을 확인할 수 있다.

코드 구조 이해에 도움이 될 수 있도록 데이터 수를 최소 규모로 줄이자. addition.txt 에서 앞부분을 잘라 13개의 입력 데이터 즉 N=13인 add.txt 를 준비한다. 이로서 char_to_id 와 id_to_char 데이터가 준비된다.
| 1 | 16+75 _91 | 8 | 84+317 _401 |
| 2 | 52+607 _659 | 9 | 9+3 _12 |
| 3 | 75+22 _97 | 10 | 6+2 _8 |
| 4 | 63+22 _85 | 11 | 18+8 _26 |
| 5 | 795+3 _798 | 12 | 85+52 _137 |
| 6 | 706+796_1502 | 13 | 9+1 _10 |
| 7 | 8+4 _12 |
12개의 데이터는 학습용으로 나머지 1개는 validation 용으로 사용된다. 아울러 학습용 각각의 데이터는 questions 파트와 answers 파트로 나뉘어 x_train 과 t_train 으로 재구성된다. 물론 12개씩이며 나머지 1개는 테스트 즉 validation 용도이다.
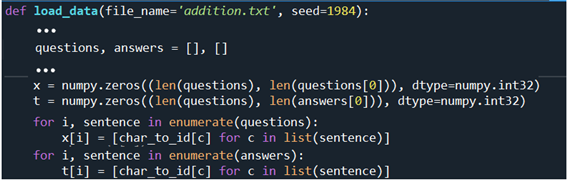
하이퍼 파라메터 값들도 작게 조작해 두자.
| 3 | vocab_size = len(char_to_id); wordvec_size = 3 # (N, T, D) ->D hideen_size = 2; batch_size = 3; max_epoch = 1; max_grad = 5.0 |
shape 이 V 인 vocab_size 는 13 으로 ‘0’ ~ ‘9’, ‘+’, ‘_’ 및 ‘ ’(블랭크, space bar)를 포함한다.
| ※ | id_to_char {0: '1', 1: '6', 2: '+', 3: '7', 4: '5', 5: ' ', 6: '_', 7: '9', 8: '2', 9: '0', 10: '3', 11: '8', 12: '4'} |
shape 이 D 에 해당하는 wordvec_size 는 16 정도의 크기가 제대로 된 값이지만 최소화 해서 3 으로 설정한다.
shape 이 H 에 해당하는 hidden_size 는 128 로 충분히 큰 값을 취해야 하나 여기서는 간단히 2 로 둔다.
batch_size =128 로 충분히 큰 값을 취해야 하나 여기서는 3 으로 둔다.
max_epoch = 5 정도로 두어야 하난 여기서는 1 로 둔다.
하이퍼 파라메터들을 인위적으로 조절해 둔 상태에서 출력값을 살펴보면서 코드의 실행을 시뮬레이션해 본다.
메인 코드인 train_seq2seq.py에서 Trainer 의 메서드인 fit을 사용하여 학습을 시키도록 하자. 학습용 questions 데이터 x_train 과 answers 데이터 t_train 이 제공된다.

한편 trainer.py 에서 메서드인 fit 에서는 x_train 과 t_train 을 미니배치 크기인 batch_size 단위로 준비하여 Seq2seq 클라스의 메서드 forward를 사용하여 순전파 연산에 의해서 loss를 계산하고 model.backward에 의해 오차 역전파 연산을 실행하게 된다.
메인 코드인 train_seq2seq.py 으로부터 제공되는 x_train 데이터는 trainer.py 에 의해서 실행되는 model.forward 즉 seq2seq.py 의 Seq2seq 클라스의 메서드인 forward 순전파 연산에서 decoder 와 encoder 입력 데이터가 id 형태로 준비된다. decoder 용 입력 데이터 ts[] 는 ‘_‘ 포함 5자리이지만 그 중 4자리만 사용한다. 반면에 정답 레이블은 ’_‘ 를 제외 한 자리씩 당겨서 준비된다. 아울러 아래의 self.encoder.forward(xs) 실행은 TimeEmbedding 과 TimeLSTM 실행에 의해 은닉층 벡터 h 의 순전파 연산이 이루어진 후 decoder 연산과정에 투입된다.
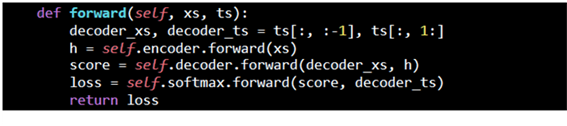
바로 위 코드의 은닉층 h 계산을 위한 연산 과정을 살펴보자. Encoder 클라스에서 embed_W 는 shape 이 (13, 3)으로 주어지며 랜덤 수로 초기화 된다.
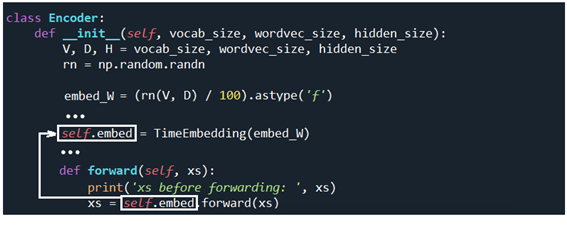
self.embed.forward(xs)를 실행하면 TimeEmbedding 클라스의 메서드 forward 를 사용하여 순전파 연산을 하게된다. TmeEmbedding 클라스 실행 이전에 xs를 출력해 보자. self.encoder.forward(xs) 에서 xs 는 아직까지 idx 값으로 이루어진 리스트 데이터로 남아 있음을 확인할 수 있다.

TimeEmbedding 클라스에서는 인수인 embed_W를 W 로 받아서 instance 변수인 self.W 를 설정하여 출력해 보면 shape 이 13X3 임을 확인할 수 있다.

TimeEmbedding 클라스에서 순전파 forward 연산을 위해서 0, ..., T-1 만큼 펼친 형태의 출력 out을 준비하자. instance 변수 중 self.W 를 layers.py 에 포함되어 있는 Embedding 클라스에 입력한다.
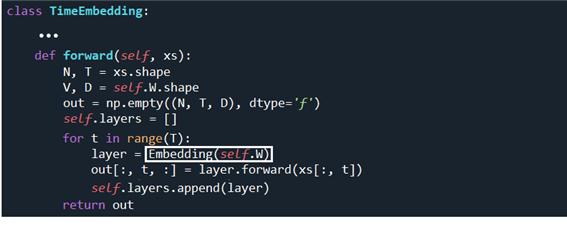
아울러 Embedding 클라스에서 인수로 넘겨받는 idx 리스트 데이터인 xs[:, t] 를 사용하여 출력 out=W[idx]를 계산하여 반환하면 TimeEmbedding 클라스에서 out[:, t, :] 를 하나씩 생성해 append 하므로서 TimeEmbedding 순전파 연산을 완료한다.

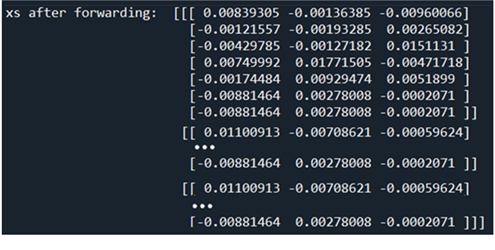
idx 로 이루어진 xs 를 입력받아서 W[idx] 를 출력해보면 다음과 같이 7X3 의 결과를 얻을 수 있다. 7은 입력데이터 xs 의 questions 에 해당하는 패딩 포함 7개의 문자를 나타내며 3 은 wordvec_size=3을 나타낸다.
다시 Encoder 클라스로 돌아가서 idx 형태의 xs 를 사용한 연산 결과를 Embedding 클라스에서 가중치인 W[idx] 로 변환하자. 아울러 이를 lstm 에 입력하여 순전파 연산을 실행하자. self.lstm.forward 연산은 TmeLSTM 클라스를 사용하여 이루어진다.

self.lstm.forward 연산을 위해서 TimeLSTM 의 메서드 forward 에서 앞서 준비한 W[idx] 형태의 xs 를 인수로 받는다. 현재 다루고 있는 ‘+“ 연산이나 번역 문제 같은 경우는 주어지는 입력 데이터 길이가 짧기 때문에 앞 스테지의 정보 기억이 그다지 필요치 않으며, stateful=False 로 설정한다.

T개의 LSTM 셀을 펼치면서 은닉층 h 와 connection c 를 계산하자. 특히 stateful=False 로 설정된 t= 0 인 경우는 앞 스테이지로부터 self.h 와 self.c 를 넘겨받을 필요가 없으므로 0 으로 둔다. 하지만 t=1, ..., T-1 인 경우는 recursive 방식으로 self.h 와 self.c 를 사용하여 계산이 이루어진다.
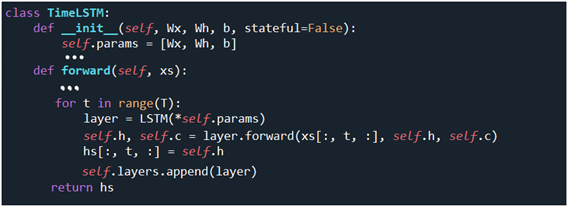
Seq2seq 클라스에서 self.encoder.forward 에 이어 self.lstm.forward(xs) 연산에서 반환된 hs 중 hs[:, -1, :] 는 T 개의 셀로 펼쳐진 인코더의 LSTM 셀 중에서 가장 나중의 것이며 이는 디코더 연산 시 입력으로 사용된다. 나머지는 어디에 사용하는가? 이 문제는 seq2seq 알고리듬을 더욱 개량할 수 있는 Attention 알고리듬에서 hs 전체 정보를 활용하게 됨에 유의하자.

여기까지가 메인코드인 train_seq2seq.py 의 epoch loop에서 학습을 위해 호출하는 trainer.py 의 메서드 fit 코드에서 미니배치를 대상으로 한 기본적인 1 싸이클 학습과정에서 순전파에 해당하는 알고리듬이다. 오차 역전파 연산은 Decoder 클라스 실행 후 이루어지게 된다.
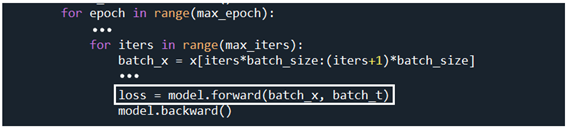
아래 연산 결과는 Seq2seq 클라스에서 Decoder 클라스의 메서드 forward 순전파 계산 바로 이전에 관찰할 수 있는 idx 값들이며 TimeEmbedding 클라스에서 T(=4)개로 펼친 후 마지막 (T-1) 번째 출력으로서 미니배치 3 에 T=4로 이루어진 리스트 데이터로서 wordvec_size=3 인 결과의 출력 out 이다. out 의 shape 은 [batch_size=3, T=4, wordvec_size=3] 이다.
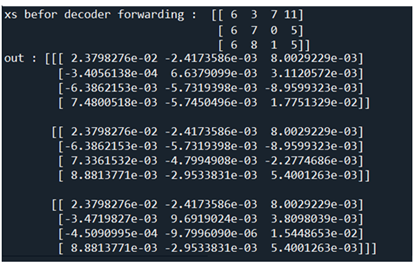
Decoder
decoder의 시작은 Seq2seq 클라스의 메서드 self.decoder.forward 부터이다. encoder 에서는 7개의 입력 데이터를 사용했지만 decoder 에서는 5개의 데이터 중에서 한 자리씩 밀어 처리한 후 4자리 데이터 즉 ts[:, :-1], ts[:, 1:] 를 사용한다. 즉 encoder 의 xs 대신에 decoder_xs 를 입력하는 게 차이점이다.
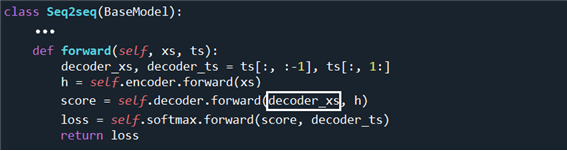
decoder 의 self.decoder.forward 에서는 encoder 와는 달리 self.lstm 의 메서드 set_state(h) 와 affine.forward 실행이 추가된다.

self.lstm.forward 순전파 연산을 담당하는 TimeLSTM 을 살펴보자. N=3, T=4, D=3 이므로 xs.shape=[3,4,3] 이 된다. 아울러 xs 를 입력으로 사용한 연산 결과인 hs 의 shape 은 [N, T, H] 로서 [3, 4, 2] 가 되어야 한다.
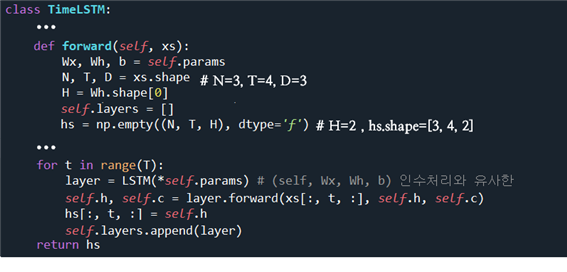
decoder 의 TimeLSTM 클라스에서 set_state 는 encoder 알고리듬에서 생성한 최종 h 값을 인수하는 데 사용된다. 사용되는 입력들이 ’+‘ 연산이므로 긴 문장에서처럼 기억해야 할 부분이 없으므로 connection c= None 으로 처리한다.
decoder 클라스에서 self.embed.forward 와 self.lstm.forward 순전파 계산 알고리듬은 입력 데이터 크기만 7이 아닌 4일뿐이지 encoder 처리 과정과 동일하다.

통상적으로 decoder 의 마지막 단에 self.affine.forward 순전파 연산이 추가된다. self.lstm.forward에서 넘겨 받은 x 의 shape 은 [3,4,2] 가 된다. 아래의 x 연산 결과를 참조하자.
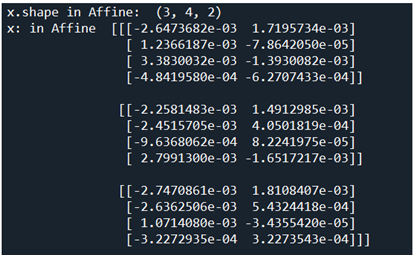
합계 24개의 값을 가지는 x를 [N*T, -1] 형태의 shape 이 되도록 reshape 한다. -1 은 [3, 4, 2] 에서 마지막 항의 값 즉 2 를 의미한다. 위 x 의 값들과 아래의 reshape 된 결과를 비교해 보면 단순히 순서대로 합해졌음을 알 수 있다.
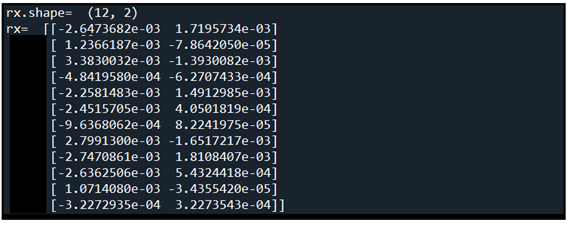
아울러 아래의 코드에서 Affine 메서드에서 가중치 W 와 b 의 shape 은 각각 [2, 13] 및 [13,] 이다. np.dot 명령에서 각 shape 이 2차원이면 매트릭스 계산이 이루어져 shape 이 [12, 13] 이 되며 최종적으로 shape 이 [13,] 인 편향 b 를 더할 경우 12개의 row 들에 대해 편향 b 가 더해지게 되어 shape 은 [12, 13] 이 된다. 이 결과를 다시 [3, 4, 2] 로 reshape하여 반환한다.
※ np.dot 연산은 TensorFlow 에서 tf.matmul(x,W) 와 유사한 연산임에 유의하자.
한편 shape [3, 4, 2] 였던 x 는 self.x 로 두어 다음 단계의 softmax 순전파 연산 후에 시작되는 softmax 오차 역전파 연산 후 Affine 역전파 연산에서 끄집어내어 사용할 예정이다.
순전파 연산 마지막 단계인 softmax.forward를 살펴보자. 앞단의 Affine 에서 연산된 [3, 4, 13] shape 인 out 을 score 로 반환받아 decoder_ts 와 함께 인수로 넘기도록 하자.
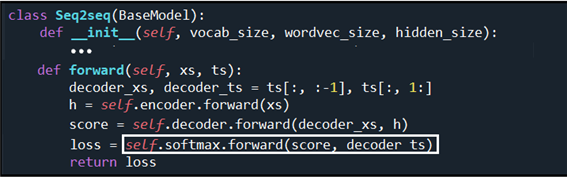
softmax 에서는 3차원 shape 인 xs = out 과 2차원 shape 인 ts 를 인수로 넘긴다. ts 의 값을 조사해 보면 다 0 ~12 사이의 정수이고 ’-1‘ =self.ignore_label 이 아니므로 ts 성분들을 Boolean 인 True 로 설정한다.
3차원 shape 인 xs 를 2차원 shape 으로 2차원 shape 인 ts 와 mask 를 1차원 shape 으로 reshape 한다.
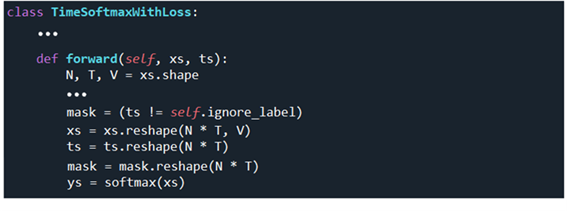
xs를 softmax 처리하여 출력해 보면 다음과 같이 12x13 확률 분포 값이 얻어진다. 각 리스트 13개를 더하면 1.0 이 된다.

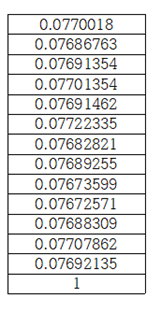
첫 번째 리스트 데이터 13개를 더하면 softmax 처리한 확률이었으므로 합은 1.0 이 됨을 알 수 있다.
이 값들에 대해서 ’0‘ ~’12‘의 vocab_size 13개 중 하나를 나타내는 정답 레이블들 ts[] 의 값에 해당하는 확률 값을 정하여 log 값을 계산한다. 이 확률들을 합산하여 마이너스 부호를 취하고 총 미니배치 수로 나누어 Cost 함수 loss를 계산하자.

여기까지가 오차 역전파 연산을 시작하기 위한 순전파 연산의 마지막 단계이다. 유사한 방법으로 오차 역전파 과정을 분석할 수 있을 것이다. 단 순저파 연산 과정이 다소 까다로운 면들이 있었기때문에 역으로 거슬러 가는 과정에서도 그 이상으로 어렵게 느껴지는 부분들이 많이 있을 것으로 보이며 독자들의 몫으로 남겨두도록 하자.
마지막 한가지 중요한 점은 이 정도 수준으로 코드가 이해가 되었으면 특히 순전파 과정의 h, hs 부분이 정확히 이해되었으면 Attention 알고리듬으로 넘어가서 생존(?)하여 Transformer 알고리듬에 도전해 볼 수 있는 기초가 준비되었을 것으로 본다.
Good Luck!
Under Construction ...
'자연어처리' 카테고리의 다른 글
| 생성형 AI 가 제공하는 Response의 6. Overall Quality Rating 평가 (0) | 2024.04.30 |
|---|---|
| Attention RNN 모델과 코드 구조 (0) | 2023.03.13 |
| ChatGPT로 살펴보는 새로운 경쟁 (0) | 2023.01.23 |
| Attention RNN 알고리듬에서의 shape 변경 기법 (0) | 2023.01.20 |
| word2vec, CBOW (Continuous Bags of Words) (0) | 2023.01.03 |