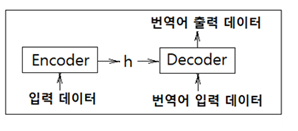
기계 번역 분야에서 매우 인기가 있었던 Sequence to Sequence 모델은 두 개의 RNN 즉 인코더와 디코더를 짝으로 구성된다. 인코더는 입력을 순차적으로 처리하고 모든 입력 데이터를 감안한 은닉층 벡터를 생성한다. 그 생성된 은닉층 데이터는 해당 컨텍스트를 사용하여 적절한 대상 시퀀스(번역, 챗봇의 응답)를 예측 학습하는 디코더로 전달된다.
중요 응용 분야는 다음과 같다.
기계 번역: 한 언어의 문장을 다른 언어로 번역
자동 용약: 긴 문장을 짧게 요약된 문장으로 변환
질의 응답: 질문을 응답으로 변환
메일 자동 응답: 수신한 이메일 문장을 답변 글로 변환
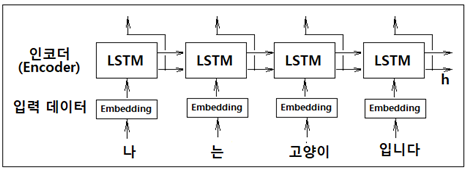
sequence는 RNN 이나 LSTM에서 일정한 길이를 가지는 데이터를 의미한다. 인코더의 역할은 특정 언어의 입력 데이터를 받아들여 LSTM RNN 처리 후 일정 길이의 은닉층 벡터 h를 생성하여 디코더에 전달하여 순전파 및 역전파에 따른 학습이 이루어지게 된다.
다음 그림은 인코더와 디코더를 이용하는 간단한 기계 번역 구조를 보여준다. 인코더에서는 Embedding 레이어에 이어 LSTM 레이어 처리로 종료한 후 은닉층 정보 h 를 준비한다, 인코더에서는 더이상 상류로의 출력 처리는 없다.
아울러 디코더 구조에서는 번역어를 사용하여 LSTM 학습 구조를 갖추면 충분하다. 단 여기서 인코더의 은닉층 정보를 디코더에 어떻게 전달하느냐에 따라 기계 번역기의 성능에 큰 영향을 미친다. 한편 일반적인 LSTM 학습 구조에 인코더에서 전달되는 은닉층 정보 h 로부터 번역을 위한 입출력 데이터와의 연관성을 보강해 주어야 번역 효율이 더욱 좋아진다.
※ 한빛 미디어, Deep Learning from scatch, 2편, 317p., 7.3.4 seq2seq 평가 내용과 관련 코드를 참조한다.
train_seq2seq.py 학습 코드를 살펴보자. import 하는 sequence.py, Trainer, Seq2seq 클라스 명령에 주목하자.
sequence.py 에서는 질문에 해당하는 questions 와 정답에 해당하는 answers를 문자 텍스트로 입력받아 ’+‘ 포함 문자 7개와 ’-‘포함 해답 5글자를 padding 까지 고려하여 처리한다.
seq2seq.py 에 포함되어 있는 Seq2seq 클라스를 model로 선언하여 학습을 위한 Trainer 클라스에 인수로 옵티마이져 ’Adam’과 함께 제공한다.
| 1 | import sys; sys.path.append('..') import numpy as np; import matplotlib.pyplot as plt from dataset import sequence from common.optimizer import Adam from common.trainer import Trainer from common.util import eval_seq2seq from seq2seq import Seq2seq from peeky_seq2seq import PeekySeq2seq |
특별히 addition.txt에서 앞부분을 잘라 아래와 같이 13개의 입력 데이터 즉 N=13인 add.txt 를 준비한다. 12개의 데이터는 학습용으로 나머지 1개는 validation 용으로 사용한다.
| 1 | 16+75 _91 | 8 | 84+317 _401 |
| 2 | 52+607 _659 | 9 | 9+3 _12 |
| 3 | 75+22 _97 | 10 | 6+2 _8 |
| 4 | 63+22 _85 | 11 | 18+8 _26 |
| 5 | 795+3 _798 | 12 | 85+52 _137 |
| 6 | 706+796_1502 | 13 | 9+1 _10 |
| 7 | 8+4 _12 |
데이터 수가 작고 하이퍼 파라메터 값들이 작으면 출력을 통해 코드 구조 이해에 도움이 된다.
| 3 | vocab_size = len(char_to_id) wordvec_size = 3 # (N, T, D) ->D hideen_size = 2; batch_size = 3; max_epoch = 1 max_grad = 5.0 |
shape 이 V 인 vocab_size 는 13 으로 ‘0’ ~ ‘9’, ‘+’, ‘_’ 및 ‘ ’(블랭크, space bar)를 포함한다.
| ※ | id_to_char {0: '1', 1: '6', 2: '+', 3: '7', 4: '5', 5: ' ', 6: '_', 7: '9', 8: '2', 9: '0', 10: '3', 11: '8', 12: '4'} |
shape 이 D 에 해당하는 wordvec_size 는 16 정도의 크기가 제대로 된 값이지만 최소화 해서 3 으로 설정한다.
shape 이 H 에 해당하는 hidden_size 는 128 로 충분히 큰 값을 취해야 하나 여기서는 간단히 2 로 둔다.
batch_size =128 로 충분히 큰 값을 취해야 하나 여기서는 3 으로 둔다.
max_epoch = 5 정도로 두어야 하난 여기서는 1 로 둔다.
하이퍼 파라메터들을 인위적으로 조절해 둔 상태에서 출력값을 살펴보면서 코드의 실행을 시뮬레이션해 본다.
sequence.py 의 메서드 load_data 를 인수에 해당하는 입력 데이터 파일 ‘add.txt’를 지정하여 실행시키면 학습 데이터와 validation 데이터가 얻어진다.
13개의 데이터를 가진 ‘add.txt’를 사용하면 학습용 12개와 validation용 1개로 나누어 char_to_id 와 id_to_char 데이터가 준비된다.
Seq1seq 클라스를 model 로 선언한다. 인수는 N,D,H 에 해당하는 하이퍼 파라메터 값들이다. 학습을 위해 model 과 optimizer 를 Trainer 클라스에 인수로 제공한다.
| 4 | model = Seq2seq(vocab_size, wordvec_size, hidden_size) optimizer = Adam() trainer = Trainer(model, optimizer) |
Trainer 의 메서드인 fit을 사용하여 학습을 시키도록 하자. model 과 optimizer 를 instance 변수로 둔다.
| 5 | class Trainer: def __init__(self, model, optimizer): self.model = model self.optimizer = optimizer self.loss_list = [] self.eval_interval = None self.current_epoch = 0 |
매서드 fit 에서는 instance 변수 인수들 즉 self.model, self.optimizer 를 일반 변수명인 model, optimizer 로 바꾸어 사용한 후 메서드 fit 의 실행이 끝나도 다시 instance 변수 형태로 fit 외부로 내보낼 필요가 없다.
batch_size 에 해당하는 미니배치의 수를 나타내는 변수 max_iters 는 13 // 3 = 4... 나머지 1 이므로 4가 된다.
| 6 | def fit(self, x, t, max_epoch=10, batch_size=32, max_grad=None, eval_interval=20): data_size = len(x) max_iters = data_size // batch_size self.eval_interval = eval_interval model, optimizer = self.model, self.optimizer total_loss = 0; loss_count = 0 |
메인코드인 위 4항의 학습을 위한 코드 준비에 이어 메서드 fit을 이용한 학습을 실행하자. 간단한 수치 실험을 위해 가장 작은 값인 max_epoch = 1 로 선언하였다. 인식률을 epoch 별로 계산하여 덧붙일 수 있도록 즉 append 할 수 있도록 비어있는 리스트 변수 acc_list 를 준비 선언한다.
| 7 | acc_list = [] for epoch in range(max_epoch): trainer.fit(x_train, t_train, max_epoch=1, batch_size=batch_size, max_grad=max_grad) |
위 6항의 메서드 fit 명령들에 이어지는 실행 명령들을 살펴보자. epoch 별로 전체 데이터 N=13개 중 학습을 위한 12개 데이터와 1개의 validation 데이터를 numpy.random.permutation 명령을 사용 무작위로 섞는다.
학습 데이터 중 x[] 는 입력 데이터이며 t[] 는 정답 레이블 데이터이다.
max_iters = 4 이므로 iters = 0, 1, 2, 3 에 해당하는 미니배치 데이터를 준비하자. 3개의 데이터를 가지는 미니배치 별로 batch_x[] 와 batch_t[] 를 준비한다. 미니배치 4개를 준비하면 딱 떨어진다.
model(Seq2seq클라스)의 순전파 즉 model.forward 연산에 의해 Cost 함수 loss 를 수치적으로 계산하고 이어서 오차 역전파 연산을 수행한다.
| 8 | for epoch in range(max_epoch): idx = numpy.random.permutation( numpy.arange( data_size ) ) # 무작위 뒤섞기 x = x[idx] t = t[idx] for iters in range(max_iters): batch_x = x[iters*batch_size:(iters+1)*batch_size] batch_t = t[iters*batch_size:(iters+1)*batch_size] # 기울기 구해 매개변수 갱신 loss = model.forward(batch_x, batch_t) model.backward() |
loss 순전파 연산을 위해서 사용하는 model.forward 는 코드 seq2seq.py에서 Seq2seq 클라스에 포함된 메서드 __init__ 과 메서드 forward 를 사용하게 된다.
초기화 과정에서 함수 Encoder(V, D, H) 를 self.encoder 로 둔다.
아울러 메서드 forward에서는 디코딩을 위해 미니배치 데이터인 batch_t를 ts 로 받은 후 한자리씩 밀어서 디코더용 입력 ts[:, :-1] 과 정답 레이블 ts[:, 1:] 를 준비한다.
decorde_xs 와 연산된 h를 self.decorder 에 입력하여 디코딩을 실행한다.
| 9 | class Seq2seq(BaseModel): def __init__(self, vocab_size, wordvec_size, hidden_size): V, D, H = vocab_size, wordvec_size, hidden_size self.encoder = Encoder(V, D, H) self.decoder = Decoder(V, D, H) self.softmax = TimeSoftmaxWithLoss() ... def forward(self, xs, ts): decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:] h = self.encoder.forward(xs) score = self.decoder.forward(decoder_xs, h) loss = self.softmax.forward(score, decoder_ts) |
아래 관계식을 참조하면서 함수 Encoder(V, D, H)에서 이루어지는 초기화와 연산 내용을 살펴보자.
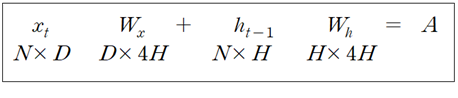
embed_W 의 shape 은 (V, D) 이며 모두 랜덤 수로 초기화 한다.
lstm_Wx 의 shape 은 (D, 4 * H) 이며 모두 랜덤 수로 초기화 한다.
lstm_Wh 의 shape 은 (H, 4 * H) 이며 모두 랜덤 수로 초기화 한다.
lstm_b 의 shape 은 (4 * H) 로서 모두 0(zeros) 으로 초기화 한다.
| 11 | class Encoder: def __init__(self, vocab_size, wordvec_size, hidden_size): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn embed_W = (rn(V, D) / 100).astype('f') lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') ... class Decoder: |
11항에서 초기화된 가중치 값들이 아래에서처럼 instance 변수들 self.embed 와 self.lstm 의 연산이 이루어지고 이들을 상속하여 self.embed.params 와 self.lstm.params 를 얻을 수 있다. 하지만 이 둘을 더 하여 self.params 로 둔다고 해서 덮어쓰기가 이루어지는 것이 아니라 각 단위별 shape 과 성분 값들을 그대로 유지하면서 단지 하나의 유닛으로 모으는 것이다. 이는 각각을 출력해 보면 알 수 있다.
| 12 | self.embed = TimeEmbedding(embed_W) self.lstm=TimeLSTM(lstm_Wx,lstm_Wh,lstm_b, stateful=False) self.params = self.embed.params + self.lstm.params |
다시 9항으로 돌아가 보면 Encoder 클라스에서는 TimeEmbedding 과 TimeLSTM 순전파 연산이 이루어진다. 반면에 Decorder 클라스에서는 TimeEmbedding, TimeLSTM, 그리고 Affine 순전파 연산을 실행시키게 될 것이다. 마지막으로 self.softmax 순전파 연산이 뒤따른다.
이러한 작업은 학습을 시키기 위한 8항의 메인코드에서 미니배치 단위로 옵티마이져가 가중치 업데이트 작업을 통해 더 이상 기울기 변화가 없을 정도로 수렴하게 되면 학습이 완료되어 멈추게 될 것이다.
12항에서 self.embed 는 가중치 embed_W를 인수로 받는 함수 TimeEmbedding 으로 선언되어 있다. 이 클라스는 encoder 의 순전파 연산 및 decoder 의 입력 수전파 연산에 공통으로 사용됨에 유의하자.
| 13 | class TimeEmbedding: def __init__(self, W): ... def forward(self, xs): N, T = xs.shape V, D = self.W.shape out = np.empty((N, T, D), dtype='f') self.layers = [] for t in range(T): layer = Embedding(self.W) out[:, t, :] = layer.forward(xs[:, t]) self.layers.append(layer) return out |
'인공지능 응용 공학' 카테고리의 다른 글
| 지적재산기반 인공지능응용 공학 목차 PDF 파일 (0) | 2023.02.22 |
|---|---|
| Attention RNN 모델 (0) | 2023.02.03 |
| 텍스트 생성(text generation) 알고리듬 (0) | 2023.02.03 |
| Rnnlm 클라스를 사용 PTB 데이터세트 전체를 대상으로 학습시켜보자. (0) | 2023.02.03 |
| Simple Rnnlm 클라스를 사용한 학습에 관해서 살펴보자 (0) | 2023.02.03 |