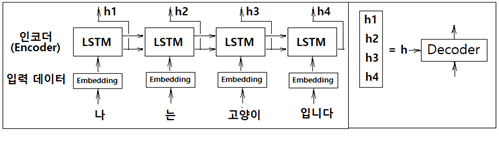
seq2seq RNN 모델에서 인코더 알고리듬을 개량해 보자. 앞서 기술된 인코더 구조에서는 마지막 LSTM 셀로부터 출력되는 은닉층 정보 h 가 디코더의 LSTM 첫 번째 셀에 전달하는 단순한 구조를 보여주었다.
개선 이전의 인코더에서는 문장 전체를 쪼개서 각각의 LSTM 셀에 입력하여 은닉층 연산 후 펼쳐진 마지막 LSTM 셀에서 출력되는 은닉층 정보 h 를 디코더에 입력했었다. 개선 후에는 인코더 각각의 LSTM 셀로부터 출력되는 은닉층 정보를 모은 h 를 디코더에 입력하는 방법이다. 이렇게 하면 인코더 sequence 의 ‘고정길이’라는 제약을 벗어날 수 있다. 즉 마지막 LSTM 하나의 셀에서 결과를 넘기는 것에 비해 입력데이터 수에 해당하는 만큼의 은닉층 정보 전체를 전달하므로 고정된 길이의 벡터라는 제약을 벗어날 수 있다는 뜻이다.
현재의 LSTM에 대한 입력 방향은 왼쪽에서 오른쪽으로 설정되어 있지만 방향성에 의한 치우침으로 인해 벡터 h 형성에 불균형이 초래할 수도 있으므로 양방향 (bidirectional) 알고리듬을 사용하여 해소할 수도 있다.
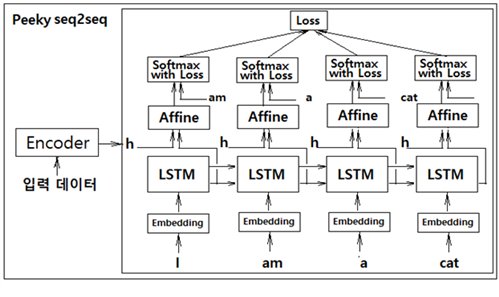
두 번째 개선안은 인코더로부터의 은닉층 정보 h 를 디코더의 LSTM 레이어에 입력하는 방법 개선안이다. 즉 첫 번째 개선안에 따라 출력하여 준비한 은닉층 정보 h 를 디코더의 첫 번째 LSTM 레이어에 직접 입력하는 것이 아니라 아래 그림에서처럼 디코더 각각의 LSTM 레이어와 이어지는 Affine 레이어의 입력에 합산(concatenation)하여 디코더 전체에서 활용하도록 하는 것이다. 이와같이 은닉층 정보 h 를 Affine 레이어에서 공유 처리함으로 인해 번역의 경우 효율이 상당히 개선될 수 있다. 다음 그림에서의 이러한 기법을 Peeky seq2seq 알고리듬이라고 한다.
Peeky seq2seq 알고리듬의 번역 성능을 더욱 높이기 위해서는 인코더에서 준비하는 은닉층 정보의 모음 hs 에서 예를 들자면 ‘나=I’, ‘고양이=cat’ 과 같은 명백한 관계에 주목(attention)할 필요가 있으며 이 정보를 디코더에 어떤 방식으로 넘겨주느냐는 문제로 귀착된다.
인코더의 마지막 LSTM 셀로부터의 은닉층 정보는 이 예제에서는 h4 에 해당한다. 이 결과물은 그대로 디코더의 첫 번째 LSTM 셀에 입력하도록 하자. 아울러 인코더 각각의 LSTM 셀의 은닉층 정보 h1, h2, h3, h4 를 모아 둔 hs 는 디코더 각각의 LSTM 셀에서의 은닉층 정보 출력과 함께 연산 레이어에 입력하자. 이 연산 레이어는 인코더 은닉층 정보 hs 와 각각의 LSTM 셀에서의 은닉층 정보 출력과 상관관계가 높도록 어떤 연산 즉 attention 레이어를 수행해야 할 것이다. 자연어 처리에 있어서 대부분의 레이어는 순전파 Affine 레이어와 그 편미분에 의한 역전파 레이어로 구성되지만 attention 레이어는 디코더 입력과의 연관성을 추출 하기 위한 다소 특별한 알고리듬 도입이 필요하다.
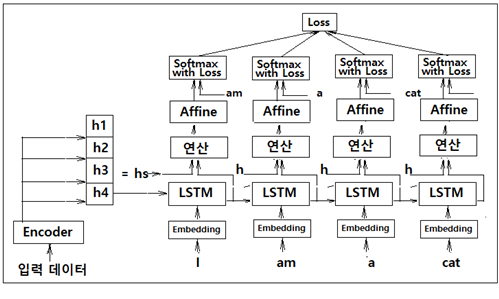
인코더의 각 LSTM 셀로부터 얻어지는 은닉층 개별 정보 hi(h1, h2, h3, h4)는 위 그림과 같이 은닉층 사이즈 크기로 출력이 될 것이며 아무래도 각 LSTM 셀의 상류 레이어 상에서 각 입력 데이터의 특성을 가장 많이 반영하게 될 것이다.
인코더로부터의 모든 은닉층 정보 hs의 성분 각각에 대해 각 단어의 중요도를 나타낸다고 볼 수 있는 적절한 확률 가중치 a 를 곱하자. a 는 각 성분이 0.0 ~1,0 사이 값을 가지며 합이 확률분포처럼 1.0 이 된다고 가정한다. 곱셈 후 axis=0 을 기준으로 합산하여 압력 데이터 수만큼의 성분을 갖는 벡터 C 를 얻는다.
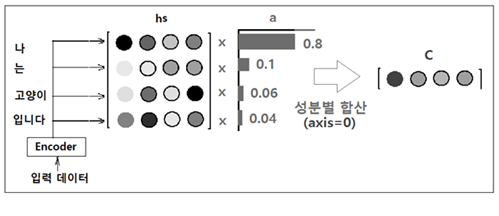
이 그림에서 a 의 첫 번째 중요도 성분이 0.8 이라고 하는 것은 입력 데이터 “나‘에 대응하는 가중치가 0.8 로서 벡터 C 에 가장 많이 반영되었다는 의미이다.
디코더의 LSTM 은닉층의 출력을 h 라 할 때 과연 이 h 가 hs 의 각 단어 벡터와 얼마나 유사한지 평가하기 위해 dot 연산에 의해 스코어 s를 계산 후 softmax를 사용 정규화하여 가중치 벡터 a로 두자.
웨이트 a 벡터와 hs 를 아마디르 곱셈 연산하여 최종적으로 C 벡터를 생성하는 이 알고리듬을 Attention이라 한다.
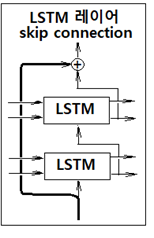
Attention 레이어의 설치는 앞서 설명한 간단한 구조 외에도 다양하게 변형된 패턴을 사용하여 상류 방향으로 여러층의 LSTM 셀을 추가할 수 있다. 특히 다층 LSTM셀 추가에 따라 기울기의 소실 또는 폭발 문제를 야기할 수 있기때문에 skip 레이어를 설치하기도 한다.
레이어 하나를 건너뛰면서 정보를 전달하기 때문에 역전파에서 + 연산 노드는 기울기 데이터를 그대로 흘려 전달하기 때문에 기울기 소실이나 폭발의 우려를 최소화 할 수 있는 이점이 있디. 이 skip 레이어는 ResNet 처럼 레이어 수가 엄청나게 많을 경우에 중간에 많이 적용하여 기울기 문제 완화에 큰 효과를 볼 수 있다.
'인공지능 응용 공학' 카테고리의 다른 글
| 지적재산기반 인공지능응용 공학 목차 PDF 파일 (0) | 2023.03.05 |
|---|---|
| 지적재산기반 인공지능응용 공학 목차 PDF 파일 (0) | 2023.02.22 |
| seq2seq RNN (0) | 2023.02.03 |
| 텍스트 생성(text generation) 알고리듬 (0) | 2023.02.03 |
| Rnnlm 클라스를 사용 PTB 데이터세트 전체를 대상으로 학습시켜보자. (0) | 2023.02.03 |