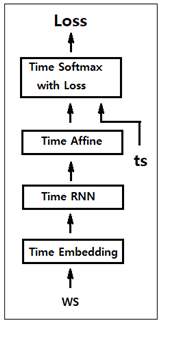
그림에서처럼 상류방향으로 4개의 Time 계층으로 이루어지는 SimpleRnnlm 클라스를 사용하여 PTB 데이터를 학습시키자. PTB 데이터 전체를 학습시키기에는 코드 효율이 너무 떨어지므로 앞부분 1000개만 사용해서 학습을 시켜보도록 한다.
정답 레이블에 입력 데이터를 한자리씩 민 데이터를 준 상태에서 Corpus 수를 제한하여 softmax를 적용한다. 원리적인 측면에서 알고리듬 이해에 도움을 줄 수 있는 예제이지 실전에서 사용하기에는 컴퓨팅 부담이 큰 알고리듬이다.
Time 계층의 입혁을 위해 batch_size = 2 를 사용하면 500개씩 배치를 형성하여 입력하도록 한다. batch =2 일 때 마지막 1000번째는 제외시키고 다시 첫 번쩨 데이터를 입력 처리하자.
Time 계층을 구성하는 단위 RNN 연산 구조를 나타내는 아래의 가중치 연산 매트릭스 구조를 참고하면서,
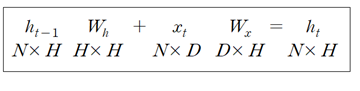
instance 연산을 위한 상류로부터의 중요 인수는 다음과 같이 설정한다.
⦁크기가 1000개인 corpus는 중복을 제외한 상태에서 단어들을 순차적으로 word_to_id를 사용하여 dictionary 형태로 배열된다.
⦁vocab_size는 corpus(단어장)에서 중복을 체크한 후의 단어장 크기 즉 418이 된다.
⦁wordvec_size는 Embedding 되는 매트릭스의 컬럼 수 D에 해당한다.
⦁hidden_size는 RNN의 은닉층 벡터의 원소 수 H에 해당한다.
⦁batch_size 는 2로 둔다.
⦁time_size는 Tme 계층의 BPTT를 감안 예를 들자면 5개로 펼치자.
⦁lr = 0.1
⦁max_epoch = 100
| 1 | # 하이퍼파라미터 설정 batch_size = 2 wordvec_size = 100 hidden_size = 100 # RNN의 은닉 상태 벡터의 원소 수 time_size = 5 # Truncated BPTT가 한 번에 펼치는 시간 크기 lr = 0.1 max_epoch = 100 |
PTB 데이터 세트의단어장(corpus) 크기는 929,589개이다. 이 중의 0.1%에 해당하는 1000개를 대상으로 학습을 시키자. 따라서 vocab_size = 418개가 된다.
| 2 | # 학습 데이터 읽기(전체 중 1000개만) corpus, word_to_id, id_to_word = ptb.load_data('train') corpus_size = 1000 corpus = corpus[:corpus_size] vocab_size = int(max(corpus) + 1) |
입력 데이터와 정답 레이블 데이터를 공급한다. 다음 단어를 예측할 수 있게끔 입출력에서 한 자리씩 밀린 형태로 처리한다.
| 3 | xs = corpus[:-1] # 입력, 출력에서 한자리씩 밀기 위하여 맨끝 하나는 제외 ts = corpus[1:] # 출력(정답 레이블), 하나씩 밀린 데이터 1번부터 시작 data_size = len(xs) |
전체 입력 데이터수를 Truncated BPTT 한 주기에 해당하는 batch_size*time_size 기준으로 나누자. 기타 변수들을 초기화하자. perplexity 데이터를 저장할 ppl_list는 리스트로 선언한다.
| 4 | # 학습 시 사용하는 변수 max_iters = data_size // (batch_size * time_size) time_idx = 0 ; total_loss = 0 ; loss_count = 0 ppl_list = [] |
모델 SimpleRnnlm 클라스와 optimizer 클라스는 별도로 이 실행 코드의 앞 셀에서 미리 실행시켜 두어야 한다. 옵티마이저는 SDG 로 설정한다.
| 5 | # 모델 생성 model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size) optimizer = SGD(lr) |
jump = corpus_size // batch_size = 1000//10 = 100 (floor division)
offsets = i*jump =[0, 100, 200, 300, 400, 500, 600, 700, 800, 900]
| 6 | # 미니배치의 각 샘플의 읽기 시작 위치를 계산 jump = corpus_size // batch_size offsets = [i * jump for i in range(batch_size)] |
(batch_size=2, time_size=5) 규격으로 입력 배치 데이터 batch_x를 empty() 명령으로 초기화 한다.
batch_x[i, t]에서 i 는 0에서 9까지의 정수이며 t는 타임스텝으로 0에서 4까지의 정수이다. batch_t[i, t]는 batch_x[i, t]와 동일한 형태이지만 여기에는 한 단어씩 어긋난 데이터가 들어 있음에 유의하자.
% data_size 연산은 불필요한 듯 보이지만 그렇치 않은 것은 max_epoch이 증가함에 따라 time_idx 값은 reset이 없어 data_size 보다 커지게 되므로 반드시 필요하다.
| 7 | for epoch in range(max_epoch): for iter in range(max_iters): batch_x = np.empty((batch_size, time_size), dtype='i') batch_t = np.empty((batch_size, time_size), dtype='i') for t in range(time_size): for i, offset in enumerate(offsets): batch_x[i, t] = xs[(offset + time_idx) % data_size] batch_t[i, t] = ts[(offset + time_idx) % data_size] time_idx += 1 |
batch_x, batch_t를 사용하여 모델(model)의 순전파를 계산하여 Cost 함수(loss)로 둔다. Cost 함수로부터 역전파 연산을 실행하고 다시 가중치를 업데이트하여 Cost 함수가 최소가 될 때까지 순전파, 역전파 및 perplrxity를 연산을 반복한다.
| 8 | # 기울기를 구하여 매개변수 갱신 loss = model.forward(batch_x, batch_t) model.backward() optimizer.update(model.params, model.grads) total_loss += loss loss_count += 1 # 에폭마다 퍼플렉서티 평가 ppl = np.exp(total_loss / loss_count) print('| 에폭 %d | 퍼플렉서티 %.2f' % (epoch+1, ppl)) ppl_list.append(float(ppl)) total_loss, loss_count = 0, 0 |

300 근방에서 시작된 ppl 값은 1.023608524955409에서 끝난다.
첨부된 Colab 파일 train_custom_loop.ipynb를 다운받아 실행해 보자.
※ "밑바닥부터 시작하는 딥러닝2편" 5장 SimpleRnnlm 학습 예제에서 jump 변수 계산식이 틀린듯하여 본문 내용에서 설명했던 bqtch_size = 2에 맞춰 수정했더니 위 그래프에서 처럼 결과가 더욱 깧끔하게 얻어졌음.
'인공지능 응용 공학' 카테고리의 다른 글
| 텍스트 생성(text generation) 알고리듬 (0) | 2023.02.03 |
|---|---|
| Rnnlm 클라스를 사용 PTB 데이터세트 전체를 대상으로 학습시켜보자. (0) | 2023.02.03 |
| word2vec 알고리듬 CBOW 모델의 PTB(Pen Treebank) 데이터 세트 적용 (0) | 2023.02.03 |
| negative sampling 알고리듬 (0) | 2023.02.03 |
| PMI (pointwise mutual information) 척도를 사용한 통계적 기법 개선 (0) | 2023.02.03 |