은닉층과 크기가 (100, 1000000)인 Wout과의 매트릭스 곱셈 연산을 통해 softmax 처리가 가능하도록 하기 위해서는 엄청난 규모의 컴퓨팅이 요구된다. 따라서 그런 과중한 연산을 줄일 수 있도록 학습 과정에서 softmax를 사용하는 다중분류에서 Sigmoid 우도(likelyhood) 함수를 사용하는 이진 분류방식으로 처리하도록 알고리듬을 수정하자.
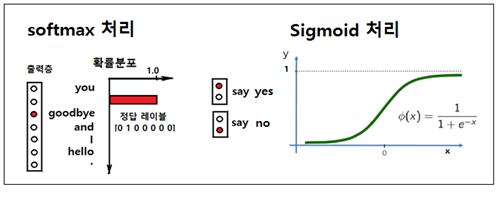
즉 입력이 {you, goodbye}이면 학습은 {say}인가? 아닌가? 로 처리하도록 한다. 즉 긍정적 정답 레이블인 {say} 하나가 있을 수 있지만 동시에 {say}가 아닌 부정적인 정답 레이블들에 대해서도 다할 수는 없지만 일정 수만큼 학습 처리해야 한다. 예를 들자면 {hello}, {.}, {and}, {I}들로서 이들은 라벨 값 ”0“으로 처리되어야 할 것이다.
만약 단어 수가 엄청 많아지게 되면 부정적인 사례 수도 마찬가지로 증가하므로 이때는 단어장을 통계적으로 분석하여 자주 사용되는 상위권의 부정적 정답 레이블들을 대상으로 무작위하게 소수 사례만 선택하여 처리해야 컴퓨팅 부담이 줄어들 수 있다. 그렇지 않고 부정적인 사례 모두를 다하려 한다면 softmax 와 마찬가지로 컴퓨팅 부담 문제가 발생한다.
한편 통계적 출현 빈도수가 아주 작은 단어들은 무작위 처리 시에 선택될 확률이 값이 너무 낮으므로 각 단어별 확률값에 대하여 1.0 보다 작은 지수승 연산을 적용하여 인위적으로 출현 빈도수가 낮은 단어들의 출현 확률을 좀 높여주는 작업이 필요할 수도 있다. 다음 확률 계산식을 참조하자. 여기서 0.75승은 사용자가 1.0 이하 범위에서 임의로 설정할 수 있다.
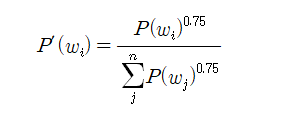
참조: ”4.2.5 네가티브 샘플링, Deep Learning from Scratch ⓶: 밑바닥부터 시작하는 딥러닝2“, pp.168 ~ 176., 사이토 고키 지음, 한빛미디어.
앞 절의 내용을 참고하여 text 문장을 입력하고 corpus를 출력하자. 이어서 class UnigramSampler의 초기화 메서드__init__ 각 확률별로 지수승을 계산한 후 정규화 한다.
| 1 | class UnigramSampler: def __init__(self, corpus, power, sample_size): self.sample_size = sample_size self.vocab_size = None self.word_p = None counts = collections.Counter() #각 단어 id별 출현회수 카운트 for word_id in corpus: counts[word_id] += 1 #단어 중복 출현 시마다 +1 증가 vocab_size = len(counts) self.vocab_size = vocab_size self.word_p = np.zeros(vocab_size) #0.0으로 초기화 for i in range(vocab_size): self.word_p[i] = counts[i] # 카운트수를 확률에 입력 self.word_p = np.power(self.word_p, power)#각확률에 지수승 self.word_p /= np.sum(self.word_p)#정규화 |
class UnigramSampler의 메서드 get_negative_sample에 target 데이터를 압력하고 target 해당 데이터의 확률은 0.0. 으노 두고 나머지 대상들에 한해서 출현 횟수 별 확률을 계산한다. 계산된 확률을 근거로 sample_size에 해당하는 만큼의 실제 부정적 샘플의 단어 id를 선택 출력한다.
| 2 | def get_negative_sample(self, target): batch_size = target.shape[0] negative_sample = np.zeros((batch_size, self.sample_size), dtype=np.int32) for i in range(batch_size): p = self.word_p.copy() target_idx = target[i] p[target_idx] = 0 #target 해당 샘플의 확류은 0.0으로 두자. p /= p.sum() negative_sample[i, :] = np.random.choice(self.vocab_size, size=self.sample_size, replace=False, p=p) return negative_sample |
np.random.choice() 명령을 사용하게 되면 무작위 샘플을 허게 되면 동률의 확률을 가지는 단어들이 여럿인 경우 매번 실행 시 마다 결과가 달라질 수도 있다.
부정적 단어의 샘플 수 sample_size 선정은 프로그래머가 임의로 선정할 수밖에 없지만 구체적인 단어 선정은 계산된 확률에 따른다.
negative sampling 에 따른 해당 샘플에 대한 정답 레이블은 ”0“으로 처리하도록 한다. 최종 Cost 함수는 정답 레이블 ”1“dp 대응하는 Cost 함수와 나머지 negative sample들에 대해 ”0“의 정답 레이블 처리된 Cost 함수들을 합산하여 구성할 수 있다.
첨부된 Colab 파일을 다운받아 실행해보자.
'인공지능 응용 공학' 카테고리의 다른 글
| Simple Rnnlm 클라스를 사용한 학습에 관해서 살펴보자 (0) | 2023.02.03 |
|---|---|
| word2vec 알고리듬 CBOW 모델의 PTB(Pen Treebank) 데이터 세트 적용 (0) | 2023.02.03 |
| PMI (pointwise mutual information) 척도를 사용한 통계적 기법 개선 (0) | 2023.02.03 |
| 분포가설(distributional hypothesis)기반 통계적 자연어 처리 기법 (0) | 2023.02.01 |
| Colab PyTorch 'Bees and Ants' Transfer Learning (0) | 2023.01.28 |