TRANSFER LEARNING FOR COMPUTER VISION TUTORIAL: PyTorch 홈페이지의 이 예제 블로그를 참조하여 해설하기로 한다.
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
메서드(method) train_model을 준비하자. LRscheduler(Learning Rate scheduler) 가 사용된다. 학습횟수가 커질수록 learning rate 값이 조절되된다.
device에 데이터 입력 과정과 아울러 optimizer.zero_grad() 명령에 의한 기울기 값 초기화로 부터 시작하여 PyTorch 특유의 backpropagation 포함 학습 알고리듬이 준비된다. 만약 Transfer Learning 이라면 특정 모델의 사전 학습된 가중치 값 설정이 따라야 한다.
함수 train_model 의 인수들에 model이 포함되어 있으며 반복 학습과정에 나타나는데 이 model은 이하의 코딩 과정에서 import 한 models에서 가장 정밀도가 뛰어나다고 알려진 ResNet18을 불러 model로 삼기로 한다.
| 4 | def train_model(model, criterion, optimizer, scheduler, num_epochs=25): since = time.time() best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print(f'Epoch {epoch}/{num_epochs - 1}') print('-' * 10) for phase in ['train', 'val']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode ● ● ● optimizer.zero_grad() model.load_state_dict(best_model_wts) # load best model weights return model |
앞서 특정한 model을 사용하여 학습 후 6개의 테스트 이미지 인식결과를 이미지와 함께 출력해보자.
| 5 | def visualize_model(model, num_images=6): was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() ● ● ● |
특정 model 명을 resnet18로 지정하여 model명을 model_ft 로 두자.
model_ft을 상속하는 fc는 fully connected layer를 의미한다.
model_ft.fc 출력 결과는 다음과 같다.
’Linear(in_features=512, out_features=2, bias=True)‘
그 의미는 fully connected layer에 입력되는 특징(features)의 수는 512개이며, 최종적으로 1,000종의 class 중 2개 즉 벌과 개미가 Transfer Learning 된다는 의미이다. 나머지 998개는 그대로 둔다는 의미이다.
| 6 | model_ft = models.resnet18(pretrained=True) num_ftrs = model_ft.fc.in_features # Here the size of each output sample is set to 2. # It can be generalized to nn.Linear(num_ftrs, len(class_names)). model_ft.fc = nn.Linear(num_ftrs, 2) model_ft = model_ft.to(device) criterion = nn.CrossEntropyLoss() # Observe that all parameters are being optimized optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # Decay LR by a factor of 0.1 every 7 epochs exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) |
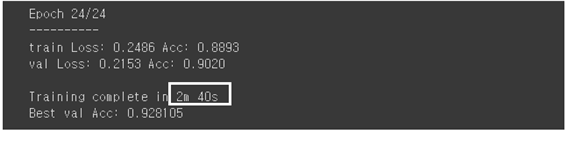
Transfer Learning 학습준비가 완료되었으므로 model을 학습시키자. 런타임 유형에 GPU 모드가 설정되었으므로 50분이 아닌 2분 40초 만에 92.8% 인식률로 연산이 종료된다. 예전 대비 GPU 연산 속도가 17배 정도로 빨라졌다.
| 7 | model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25) |
마지막으로
AlexNet에서 ImageNet이 제공하는 1000종의 이미지들에 대한 엄청난 컴퓨팅 연산 후 얻어지는 학습 결과물 즉 이진(binary)형태의 학습 가중치를 그대로 버릴 것이 아니라 binary 형태로 저장(pickling)하였다가 그대로 불러서 활용하도록 하자.
Transfer Learning은 CNN과 완전연결계층에 의해 얻어지는 사전학습 결과를 보다 효율적으로 재활용하는 실용적인 학습을 의미한다. 즉 120만개 1,000종의 이미지를 가지고 학습했다고 쳐도 특별한 이미지 종류들에 대해서 샘플이 부족한 경우가 있을 수 있다. 실례를 들자면 dog 이미지 중에 잘 알려진 서양 종자 개들은 포함되었으나 국내산 풍산개라든지 또는 눈이 보이지 않으면서 솜처럼 두리뭉실하게 생긴 삽살개 같은 이미지가 결여되어 있을 수 있다. 이런 경우에 dog 이미지에 한국산 dog 이미지를 일부 추가하여 학습시킬 경우 CNN 블록에서 얻어지는 학습 가중치 변동이 마이너하지만 당연히 있을 것이다. 하지만 랜덤한 초기값을 주어 다시 학습을 시켜야 한다면 여전히 많은 시간을 들여 엄청난 양의 연산을 다시 되풀이해야만 하지만, 만약에 dog 이미지를 추가하기 전의 가중치 값을 초기값으로 하여 재학습 연산을 수행한다면 추가되는 연산이 크게 줄어들 수 있을 것이다.
이러한 Transfer Learning을 실행하기 위한 2종류의 알고리듬을 살펴보자.
⓵ Finetunning the convnet
랜덤한 초기화를 지양하고 사전 학습된 네트워크 가중치로 추가연산을 위한 초기화를 실행한 후에 120만 플러스 알파한 수의 이미지 샘플 1,000종을 재학습하는 경우이다.
⓶ Convenet as fixed feature extractor
완전연결계층을 제외한 나머지 CNN 모듈의 가중치를 동결(freeze)한 상태에서 완전연결계층만 랜덤하게 초기화를 하여 재학습을 실행하는 경우이다. CNN 모듈이 동결된 상태이므로 추가된 이미지 입력에 대해 순전파 계산만 가능하고 CNN 모듈에서는 동결되었으므로 가중치 변화가 없기에 역전파 연산을 할 필요가 없어져 컴퓨팅 부담이 상당히 경감될 수 있다.
헤더 영역에 필요한 라이브러리들을 불러 오자.
| 1 | from __future__ import print_function, division import torch import torch.nn as nn import torch.optim as optim from torch.optim import lr_scheduler import torch.backends.cudnn as cudnn import numpy as np import torchvision from torchvision import datasets, models, transforms import matplotlib.pyplot as plt import time import os import copy cudnn.benchmark = True plt.ion() # interactive mode |
division=__truediv() in Python3, print_function:? PyTorch default library PyTorch default library 옵티마이저 library learning rate 조절 엔비디아 GPU 라이브러리 이미지 처리 default library TensorFlow 에서도 거의 동일 그래프 작성 library 시간 소요 측정 폴더 위치 맞추기 |
Transfer Learning PyTorch 예제인 bees and ants 즉 벌과 개미 45Mb 이미지를 data augmentation 기법을 적용하여 충분할 정도로 양을 부풀리자. PyTorch 나 TensorFlow 어느 라이브러리를 사용하든 동일하게 필요하다.
| 2 | data_transforms = { 'train': transforms.Compose([ ● ● ● transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ ● ● ● transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } |
PyTorch 홈페이지 예제에서 data_dir 의 위치는 Colab 사용 시 'data/hymenoptera_data'로부터 구글마운트 기법을 사용하여 ‘/content/data/MyDrive/hymenoptera_data’로 수정되어야 한다. ‘/content/data/MyDrive/‘은 구글에서 설정해둔 폴더 구조이다.
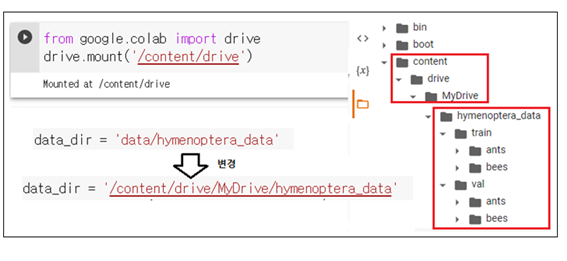
Colab 구글 드라이브에 마운팅한 이미지 데이터를 읽어들이기 위해서 아래와 같이 데이터 디렉토리 data_dir를 지정하자. 이 부분이 PyTorch 블로그 예제와 다른 점이다.
| 3 | data_dir = '/content/data/MyDrive/hymenoptera_data' image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']} dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in ['train', 'val']} dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']} class_names = image_datasets['train'].classes device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") |
함수 imshow()를 사용하여 4개의 이미지를 출력해보자.

메서드(method) train_model을 준비하자. LRscheduler(Learning Rate scheduler) 가 사용된다. 학습횟수가 커질수록 learning rate 값이 조절되된다.
device에 데이터 입력 과정과 아울러 optimizer.zero_grad() 명령에 의한 기울기 값 초기화로 부터 시작하여 PyTorch 특유의 backpropagation 포함 학습 알고리듬이 준비된다. 만약 Transfer Learning 이라면 특정 모델의 사전 학습된 가중치 값 설정이 따라야 한다.
함수 train_model 의 인수들에 model이 포함되어 있으며 반복 학습과정에 나타나는데 이 model은 이하의 코딩 과정에서 import 한 models에서 가장 정밀도가 뛰어나다고 알려진 ResNet18을 불러 model로 삼기로 한다.
| 4 | def train_model(model, criterion, optimizer, scheduler, num_epochs=25): since = time.time() best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print(f'Epoch {epoch}/{num_epochs - 1}') print('-' * 10) for phase in ['train', 'val']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode ● ● ● optimizer.zero_grad() model.load_state_dict(best_model_wts) # load best model weights return model |
앞서 특정한 model을 사용하여 학습 후 6개의 테스트 이미지 인식결과를 이미지와 함께 출력해보자.
| 5 | def visualize_model(model, num_images=6): was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() ● ● ● |
특정 model 명을 resnet18로 지정하여 model명을 model_ft 로 두자.
model_ft을 상속하는 fc는 fully connected layer를 의미한다.
model_ft.fc 출력 결과는 다음과 같다.
’Linear(in_features=512, out_features=2, bias=True)‘
그 의미는 fully connected layer에 입력되는 특징(features)의 수는 512개이며, 최종적으로 1,000종의 class 중 2개 즉 벌과 개미가 Transfer Learning 된다는 의미이다. 나머지 998개는 그대로 둔다는 의미이다.
| 6 | model_ft = models.resnet18(pretrained=True) num_ftrs = model_ft.fc.in_features # Here the size of each output sample is set to 2. # It can be generalized to nn.Linear(num_ftrs, len(class_names)). model_ft.fc = nn.Linear(num_ftrs, 2) model_ft = model_ft.to(device) criterion = nn.CrossEntropyLoss() # Observe that all parameters are being optimized optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # Decay LR by a factor of 0.1 every 7 epochs exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) |
Transfer Learning 학습준비가 완료되었으므로 model을 학습시키자. 런타임 유형에 GPU 모드가 설정되었으므로 50분이 아닌 2분 40초 만에 92.8% 인식률로 연산이 종료된다. 예전 대비 GPU 연산 속도가 17배 정도로 빨라졌다.
| 7 | model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25) |
Transfer Learning Finetuning에 의해 가중치 조정dl 완료되었으므로 테스트 데이터를 사용하여 가시화된 결과를 살펴보자.
| 8 | visualize_model(model_ft) |

Transfer Learning 기법을 사용하여 아주 짧은 시간 안에 효율적으로 결과를 얻어낼 수 있었다.
'인공지능 응용 공학' 카테고리의 다른 글
| PMI (pointwise mutual information) 척도를 사용한 통계적 기법 개선 (0) | 2023.02.03 |
|---|---|
| 분포가설(distributional hypothesis)기반 통계적 자연어 처리 기법 (0) | 2023.02.01 |
| Colab Translation 코드 실습 (0) | 2023.01.28 |
| chatGPT로부터의 텐서플로우 선형회귀법 예제 (0) | 2023.01.28 |
| Colab에서 사전학습된 가중치를 사용 PyTorch에서 AlexNet을 실행해 보자. (2) | 2023.01.28 |