자연어 처리는 컴퓨터 사이언스 및 언어학 또는 통계학 과의 학문간 제휴 영역에 해당한다.
언어학에서 모든 단어를 포함하는 사전(dictionary)이 있고, 한편 학습 대상 단어 위주로만 편집한 단어장(corpus) 가 있을 수 있다. 한편 인공지능을 만들기 위한 학습해야 할 텍스트가 너무 많아서 단어장 규모가 방대해지는 문제가 있어, 그 해결책을 찾아 보도록 하자.
John Firth 교수가 언급했던 “the company a word keeps!“에 주목하자. 특정 단어의 사전적 의미보다는 인접한 단어들의 배치에 의해 ‘context’ 즉 문장의 ‘맥락’을 형성한다는 것이다. 이 맥락을 해석해 보기 위해서 간단한 문장을 대상으로 단어장(corpus)과 단어별 색인, 색인별 단어를 얻어낼 수 있도록 preprocess() 함수를 작성하여 맥락분석을 위한 동시발생행렬을 구성해 보기로 한다. 사용하는 텍스트 문장은 대소문자 및 마침표가 있는 짧은 문장을 사용하자.
아래 한글과 Colab 의 따옴표 ‘ ’ 체계가 다르므로 복사 시 반드시 수정해야 한다.
| 1 | text = “You say goodbye and I say hello.“ text = text.lower() #소문자 처리 text = text.replace(‘.’, ‘ ,’) # 콤마에 블랭크 추가처리 text ---------------------------------------------------------------------------- 'you say goodbye and i say hello .' |
| 2 | words = text.split() # 문장에서 단어를 분리하여 리스트 데이터 작성 words # 리스트 데이터 구조로 출력 -------------------------------------------------------------------------------- ['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.'] |
리스트 데이터 각 단어별로 dictionary에 없으면
word_to-id의 크기에 해당하는 숫자를 new_id로 설정한다.
word_to_id[word] 즉 해당 단어에 해당하는 new_id 숫자 부여한다.
반대로 id_to_word[new_id] 숫자에 해당하는 단어 부여하여 dictionary 데이터 구조를 완성한다.
| 3 | word_to_id = {} # 단어와 숫자 매칭을 위해 dictionary 사용 id_to_word = {} # 단어와 숫자 매칭을 위해 dictionary 사용 for word in words: if word not in word_to_id: new_id = len(word_to_id) word_to_id[word] = new_id id_to_word[new_id] = word |
| 4 | print(word_to_id) print(word_to_id[‘hello.’]) ---------------------------------------------------------------------------------------- {'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6} 5 |
완성된 dictionary를 출력해 보자.
아래 한글과 Colab 의 따옴표 ‘ ’ 체계가 다르므로 복사 시 반드시 수정해야 한다.
| 5 | print(id_to_word) print(id_to_word[1]) print(id_to_word[2]) ---------------------------------------------------------------------------- {0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6: '.'} say goodbye |
각 단어별 id 숫자를 따내어 리스트 데이터 구조인 corpus를 완성하여 출력하자.
NumPy 어레이로 처리하였으므로 어레이 안의 리스트 데이터 형태로 출력된다.
| 6 | import numpy as np corpus = [word_to_id[w] for w in words] corpus = np.array(corpus) corpus ------------------------------------------------ array([0, 1, 2, 3, 4, 1, 5, 6]) |
1번부터 5번까지의 코드를 모아서 text를 인수로 받는 함수 preprocess를 구성하자. 이 함수 사용을 위해서는 헤더영역에 numpy를 선언해야 함에 주의하자.
| 7 | def preprocess(text): text = text.lower() #소문자 처리 text = text.replace('.’, ','') # 콤마에 블랭크 추가처리 words = text.split() # 단어를 문장에서 개별로 분리 word_to_id = {} # 단어와 숫자 매칭을 위해 dictionary 사용 id_to_word = {} # 단어와 숫자 매칭을 위해 dictionary 사용 for word in words: if word not in word_to_id: new_id = len(word_to_id) word_to_id[word] = new_id id_to_word[new_id] = word corpus = [word_to_id[w] for w in words] return corpus, word_to_id, id_to_word |
다시 text = “You say goodbye and I say hello.“를 사용하여
단어장(corpus)을 만든 후 동시발생 행렬(co-occurance matrix)을 구성해 보자.
지정된 단어의 좌우 위치에 해당하는 단어를 ‘1’로 나타내기로 하자. 좌우에 위치하는 단어를 1개만 지정하는 경우에 파라메터 window size = 1로 두기로 하자. 아래 표는 직접 동시발생행렬을 작성한 사례이다.
| you | say | goodbye | and | i | hello | . | |
| you | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| say | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| goodbye | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| and | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| i | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| hello | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| . | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
동시발생행렬 함수 코드를 구성하자. 인수는 corpus와 window_size이다. 동시발생행렬 co_matrix를 0으로 최기화 하자.
| 8 | def create_co_matrix(corpus, window_size=1): corpus_size = len(corpus) # 0으로 co_matrix 초기화 co_matrix = np.zeros((corpus_size, corpus_size), dtype=np.int32) |
아래의 for loop range에서 (1, window_size + 1) 범위는 결국 1 뿐이다. 따라서 left_idx와 right_idx는 idx=0 일때 –1과 +1이 되므로 첫 번째 단어 you 처리 시 오른쪽만 체크하게된다. 아울러 idx가 enumerate(corpus)의 최대값에 해당하면 마지막 단어 ‘.’을 처리할 때에 왼쪽만 체크하게 된다.
| 9 | for idx, word_id in enumerate(corpus): for I in range(1, window_size + 1) left_idx = idx – I right_idx = idx + 1 if left_idx >= 0: left_word_id = corpus[left_idx] co_matrix[word_id, left_word_id] += 1 if right_idx < corpus_size: right_word_id = corpus[right_idx] co_matrix[word_id, right_word_id] += 1 return co_matrix |
corpus 와 vocab_size =7을 인수로 하여 동시발생행렬 함수 create_co_matrix를 부르고 결과를 출력해보자.
| 10 | print('corpus=', corpus) comatrix = create_co_matrix(corpus,vocab_size=7) print(comatrix) ---------------------------------------------------- corpus= [0 1 2 3 4 1 5 6] [[0 1 0 0 0 0 0] [1 0 1 0 1 1 0] [0 1 0 1 0 0 0] [0 0 1 0 1 0 0] [0 1 0 1 0 0 0] [0 1 0 0 0 0 1] [0 0 0 0 0 1 0]] |
앞에서처럼 동시발생 행렬이 얻어지면 이로부터 각 단어의 특징 벡터들이 얻어진다고 볼 수 있다. 각 단어의 특징 벡터 2개를 선택하여 내적을 계산하면 단어 간의 코사인 유사도(cosine similarity)를 측정할 수 있다.
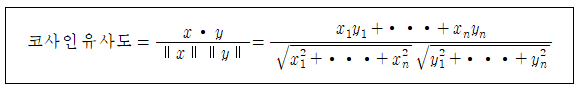
코사인 유사도는 아래의 함수 cos_similarity()를 사용하여 계산이 가능하다. 각 단어별로 정규화된 벡터로 변환 후 np.dot() 명령을 사용하여 이들 사이의 내적을 계산하도록 한다.
| 11 | def cos_similarity(x, y, eps=1e-8): '''코사인 유사도 산출 :param x: 벡터, :param y: 벡터, :param eps: '0으로 나누기'를 방지하기 위한 작은 값 ''' nx = x / (np.sqrt(np.sum(x ** 2)) + eps) ny = y / (np.sqrt(np.sum(y ** 2)) + eps) return np.dot(nx, ny) |
이미 preprocess()와 co_matix() 함수가 완성되었으므로 주어진 text에 대하여 ”you“와 ”i“의 코사인 유사도를 계산해 보자.
| 12 | vocab_size = len(word_to_id) print(corpus) print(vocab_size) C = create_co_matrix(corpus, vocab_size) c0 = C[word_to_id['you']] # "you"의 단어 벡터 c1 = C[word_to_id['i']] # "i"의 단어 벡터 print(c0) print(c1) print(cos_similarity(c0, c1)) --------------------------------------------- [0 1 2 3 4 1 5 6] 7 [0 1 0 0 0 0 0] [0 1 0 1 0 0 0] 0.7071067691154799 |
| you | |
| goodbye | 0.707 |
| i | 0.707 |
| hello | 0.707 |
| say | 0.0 |
| and | 0.0 |
동시발생 행렬을 참조하여 ‘you’와 각 단어와의 유사도를 계산해 보자.
‘i’와 ‘you’ 모두 인칭 대명사이므로 유사하다고 볼 수 있다. 반면에 ‘you’도 ‘say’ 옆에 위치하지만 ‘goodbye’와 ‘hello’도 ‘say’ 와 인접해 위치하므로 의미보다는 위치적으로 동급이라 유사도 값이 높다. 하지만 ‘goodbye’ 와 ‘hello’의 코사인 유사도가 높다는 것은 직관적으로 이해하기는 어렵다. 단어장의 크기가 보다 확대된다면 이 기법의 특징을 더욱 정확한 이해가 가능할 것이다.
첨부된 Colab preprocess.ipynb 파일을 다운받아 실행시켜보자.
'인공지능 응용 공학' 카테고리의 다른 글
| negative sampling 알고리듬 (0) | 2023.02.03 |
|---|---|
| PMI (pointwise mutual information) 척도를 사용한 통계적 기법 개선 (0) | 2023.02.03 |
| Colab PyTorch 'Bees and Ants' Transfer Learning (0) | 2023.01.28 |
| Colab Translation 코드 실습 (0) | 2023.01.28 |
| chatGPT로부터의 텐서플로우 선형회귀법 예제 (0) | 2023.01.28 |