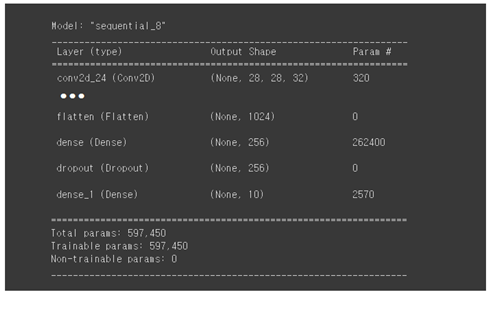
Colab에서 Untitled0.ipynb를 연 후 kerascnnmnist.ipynb 로 파일명을 부여한 후 저장하자. tensorflow를 호출하여 약어 tf 로 정의하고 버전을 출력해 보자. 아래 코드를 Colabs에서 실행하기 전에 반드시 런타임 유형 변경에서 반드시 하드웨어 가속기 GPU를 설정하도록 하자. 그러히치 않으면 실행은 가능하지만 10배 가량의 상당한 연산 시간이 소요됨에 유의하자. tensorflow.keras를 상속하는 datasets, layers, modles, losses 라이브러리를 선언한다. 이들은 tensorflow.keras에서 제공하는 메서드(method)들이다. 이 선언을 사용하면 tf.keras.layers.⦁⦁⦁를 간단하게 layers.⦁⦁⦁로 쓸 수 있는 장점..