Colab에서 Untitled0.ipynb를 연 후 kerascnnmnist.ipynb 로 파일명을 부여한 후 저장하자.
tensorflow를 호출하여 약어 tf 로 정의하고 버전을 출력해 보자.
아래 코드를 Colabs에서 실행하기 전에 반드시 런타임 유형 변경에서 반드시 하드웨어 가속기 GPU를 설정하도록 하자. 그러히치 않으면 실행은 가능하지만 10배 가량의 상당한 연산 시간이 소요됨에 유의하자.
tensorflow.keras를 상속하는 datasets, layers, modles, losses 라이브러리를 선언한다. 이들은 tensorflow.keras에서 제공하는 메서드(method)들이다. 이 선언을 사용하면 tf.keras.layers.⦁⦁⦁를 간단하게 layers.⦁⦁⦁로 쓸 수 있는 장점이 있다. 아울러 그래프 작도를 위해 matplotlib.pyplot을 약어 plt로 두자.
| 1 | import tensorflow as tf print("TensorFlow version:", tf.__version__) from tensorflow.keras import datasets, layers, models, losses import matplotlib.pyplot as plt |
메서드 load_data()를 사용 60,000개의 학습데이터와 10,000개의 검증용 테스트 데이터를 업로딩 하여 255.0으로 나누어 정규화 하자.
| 2 | (x_train, y_train), (x_test, y_test) = datasets.mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 |
Sequential() 내부에 신경망을 다 넣을 수도 있으나 한편 models.Sequential() 선언 후 model을 상속하여 메서드 add를 사용 편리하게 업데이트 할 수 있다.
데이터 세트를 읽은 후 이들의 shape을 관찰해보자. 28X28 크기인 60,000개의 학습 데이터, 60,000개의 정답 라벨값, 28X28 크기인 10,000개의 검증용 테스트 데이터로 구성된다.
| 3 | print(x_train.shape) print(y_train.shape) print(x_test.shape) |
(60000, 28, 28) (60000,) (10000, 28, 28) |
Conv2D에서 파라메터 명을 생략하는 Default 사용법에 유의하자.
shape (28,28,1) 은 28X28 사이즈로 1은 채널수로서 흑백 이미지면 1이고 컬러면 3이 된다.
마지막 신경망 층이 아니므로 활성화 함수는 relu를 사용하자.
경계를 따라서 0을 넣어 padding 하여, 스트라이딩 작업 후 크기가 변함없이 즉 same 으로 28X28이 되어야 한다.
파라메터 수는 다음같이 계산된다. 320 = 9(필터의 성분수)X32(필터수) + 32(편향수)
pooling 후 이미지 크기는 28X28에서 14X14로 줄어든다.
2번째 은닉층에서의 필터수는 64개로 2배 증가시킨다. 2번째 Conv2D에서는 padding 에 대한 언급이 없으므로 Default인 padding=’valid’ 로 처리되어, 14X14가 12X12 로 처리된다.
3번째 은닉층 필터수는 128개이며, 처리결과는 결국 4X4 가 된다.
| 4 | model = models.Sequential() model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D(pool_size=(2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.summary() |
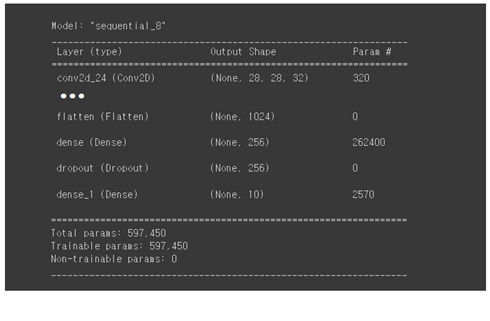
필터수가 256개이면서 shape이 (2,2)인 신경망을 Flatten() 명령을 사용하여 일차원 신경망 shape(1024,) 로 변환하자.
Dense를 사용하여 1024->256->10으로 줄인다. 10은 MNIST 문자의 종류수이다.
Dropout을 적용하여 Overfitting을 방지한다.
model.summary()를 실행하면 업데이트 된 전체 신경망 구조를 볼 수 있다.
| 5 | model.add(layers.Flatten()) model.add(layers.Dense(256, activation='relu')) model.add(layers.Dropout(0.2)) model.add(layers.Dense(10)) model.summary() |
아래 그림에서 업데이트 된 신경망 부분을 살펴보자.
신경망이 완료되었으면 옵티마이저와 Cost 함수 그리고 인식률 척도 metric을 설정하자.
여기까지가 텐서플로우 버전 1.15로 치면 graph 단계에 해당한다고 보면 된다.
| 6 | model.compile(optimizer='adam', loss=losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) |
하이퍼 파라메터 epochs = 5 로 학습을 시키자.
| 7 | history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test)) |
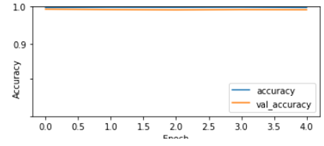
학습 결과 인식률이 거의 1.0에 가까운 0.9919가 얻어진다.

학습 결과 인식률 수렴 상황을 그래프로 작도해 보자.
학습 결과 가중치를 사용하여 검증용 데이터에 적용 후 그래프에 함께 표현해 보자.아무래도 검증용이 학습용 보다는 인식률이 미세하게 낮다.
| 8 | plt.plot(history.history['accuracy'], label='accuracy') plt.plot(history.history['val_accuracy'], label = 'val_accuracy') plt.xlabel('Epoch'); plt.ylabel('Accuracy'); plt.ylim([0.5, 1]) plt.legend(loc='lower right') test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2) |
'인공지능 응용 공학' 카테고리의 다른 글
| AlexNet Architecture 요약 (1) | 2023.01.23 |
|---|---|
| Colab에서 CNN을 사용한 CIFAR10 이미지 인식 Keras 코드 작성 (0) | 2023.01.23 |
| 인공지능 응용 공학 Image Classification (0) | 2023.01.20 |
| 구글 Colab에서 TensorFlow 버전 2.92를 사용한 MNIST 예제 (0) | 2023.01.18 |
| 구글 Colab에서 TensorFlow 버전 1.15를 사용한 MNIST 예제 (0) | 2023.01.11 |