텐서플로우는 2.x 버전에서는 초기의 1.x 버전에서 사용했던 그래프 파트와 실행 파트의 명확한 구분이 없어지고 일반적인 파이선 코드 특성을 보여준다.
이번 절에서는 1.15 버전의 MNIST 코드들이 진화되어 변형된 형태를 면밀하게 살펴보기로 하자. 라이브러리 TensorFlow 와 matplotlib.pyplot을 불러오자.
앞 절과의 차이점은 최종 인식률을 92.6%에서 98% 이상으로 높일 수 있도록 중간에 784->128로 압축하는 은닉층을 하나 부과하였다는 점이다. 출력 결과 버전 2.9.2를 확인할 수 있다.
| 1 | import tensorflow as tf print("TensorFlow version:", tf.__version__) import matplotlib.pyplot as plt |

2.x 버전 텐서플로우에서는 Keras 버전으로 업그레이드 된 MNIST 데이터 처리 class tf.keras.datasets.mnit가 사용되며 이미 내부적으로 정답 라벨이 one hot 코드화 되어 있다. Class 명인 mnist를 상속하는 메서드 load_data()를 사용하여 학습용 데이터와 테스트용 데이터를 튜플(tuple: 전체 데이터 묶음을 둘로 분리 시킨 데이터 묶음)로 불러와서 각각을 255로 나누어 정규화(normalization) 한다. 학습용은 60,000개, 검증용은 10,000개로 정해져 있는데 이는 텐서플로우 버전 1.15에서 MNIST 문제를 해보지 않았으면 잘 모를 수도 있는 부분일 것이다.
| 2 | mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 |
tf.keras.models.Sequential()로 명명된 class를 사용 모델 model을 설정한다.
입력 데이터 레이어 Flatten()을 사용 shape을 (28,28)에서 (784,)로 변경한다.
Dense()에서 Relu를 사용하면서 shape을 (784,)에서 (128,)로 압축한다.
Dropout(0.2)를 사용 학습 중에 20%를 무작위로 끓어 Overfitting을 줄인다.
Dense()에서 softmax를 사용하면서 shape을 (128,)에서 (10,)으로 압축한다.
model의 메서드 compile에서 옵티마이저를 adam으로, Cost 함수를 sparse_ categorical_ crossentroy로, metrics를 accuracy로 설정한다.
이 model 설정 단계가 1.15 버전의 graph 단계와 비슷해 보인다. 옵티마이저나 Cost 함수, metric를 설정하였지만 그 구체적인 정보는 담지 못하고 있으므로 따라오는 코드내용에 구체적인 내용을 담아야 할 것이다.
| 3 | model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) |
머신러닝 model의 Sequential 구조를 summary() 명령을 사용하여 정리해 보자.
| 4 | model.summary() __________________________________________________________ |
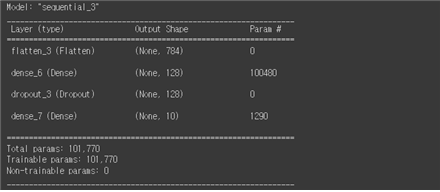
파라메터 수 100,480을 체크해 보자. 입력 데이터 X가 하나당 1X784 즉 784개의 성분을 가지므로 이에 해당하는 가중치 메트릭스 W0는 784X128이 되어야 한다. 즉 X⦁W의 연산 결과는 1X128 이 되며 아울러 편향 128개를 덧셈해야 한다. 이때 필요한 총 파라메터 수는 다음과 같이 계산된다.
| 784X128 + 128 = 100,352 + 128 = 100,480 |
1X128개로 중간 계산 결과에서 가중치 메트릭스 W1은 128X10이 되어야 하며 아울러 편향이 10개 필요하다. 이때 필요한 총 파라메터 수는 다음과 같이 계산된다.
| 128X10 + 10 = 1,290 |
| 5 | loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) |
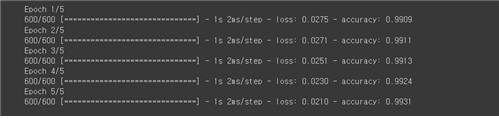
Cost 함수 부여까지 끝났으므로 아마도 여기까지가 graph에 해당하는 부분일 것이다. 그렇다면 model의 메서드 fit()을 사용하여 하이퍼 파라메터 epoch=5로 정의하여 학습을 시켜보자. epoch 란 용어는 한 주기를 뜻한다고 보면 된다. 출력 결과를 살펴보면 1 epoch 별로 1875회씩 학습이 이루어짐을 알 수 있다.
60,000개의 학습 데이터를 1 epoch 별로 600회 학습 처리한다는 것은 1 batch_size 당 100개 데이터를 사용한다는 의미이다. 아울러 5회 학습이란 앞 단계에서의 가중치와 Cost 함수을 이어받으면서 추가로 4회 학습을 더 이어나간다는 것이며 결과 인식률이 좀 더 높아질 수 있다. 학습에 대한 인식률이기 때문에 거의 1.0 즉 100%에 가까워야 하며, 실제로 검증 데이터 x_test에 대한 평가결과는 조금 낮게 나올 수 있음에 유의하자.
| 5 | progress = model.fit(x_train, y_train, epochs=5, batch_size=100) |

Cost 함수 부여까지 끝났으므로 아마도 여기까지가 graph에 해당하는 부분일 것이다. 그렇다면 model의 메서드 fit()을 사용하여 하이퍼 파라메터 epoch=5로 정의하여 학습을 시켜보자. epoch란 용어는 한 주기를 뜻한다고 보면 된다. 출력 결과를 살펴보면 1 epoch 별로 600회씩 학습이 이루어짐을 알 수 있다. 60,000개의 학습 데이터를 1 epoch 별로 600회 학습 처리한다는 것은 1 batch_size 당 100개 데이터를 사용한다는 의미이다. 아울러 5회 학습이란 앞 단계에서의 가중치와 Cost 함수을 이어받으면서 추가로 4회 학습을 더 이어나간다는 것이며 결과 인식률이 좀 더 높아질 수 있다. 학습에 대한 인식률이기 때문에 거의 1.0 즉 100%에 가까워야 하며, 실제로 검증 데이터 x_test에 대한 평가결과는 조금 낮게 나올 수 있음에 유의하자.
| 6 | progress = model.fit(x_train, y_train, epochs=5, batch_size=100) |
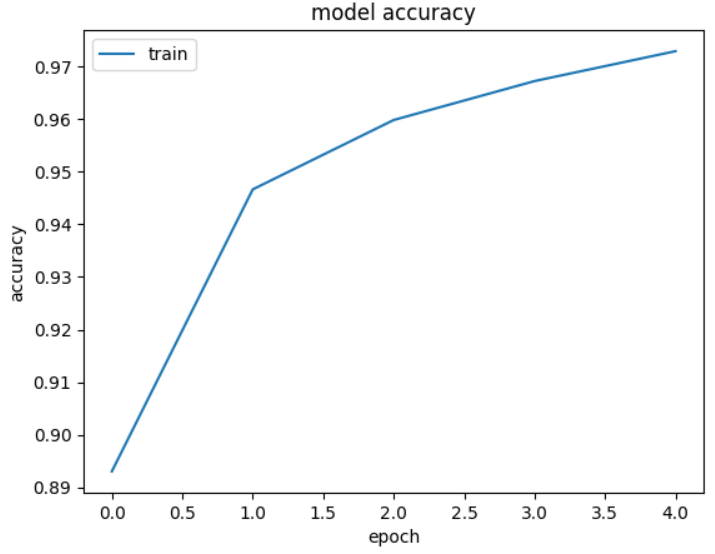
학습이 완료되었으면 학습 경과에 따른 인식률이 1.0에 가까워지는 추세를 그래프를 통해 확인해 보자.
| 7 | plt.plot(progress.history['accuracy']) plt.title('model accuracy') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(['train'], loc='upper left') plt.show() |
학습이 완료되었으면 마지막으로 검증 데이터 x_test를 넣어서 인식률을 확인해 보자. 파라메터 verbose = 0 이면 결과만 출력되며 1 이면 스텝별 소요시간, 2 이면 스텝별 에포크 별 소요시간 정보가 출력된다.
결과를 보면 Cost 함수 최소값 0.0733이며 인식률은 98.08% 이다.
| 8 | model.evaluate(x_test, y_test, verbose=2) 313/313 [==============================] - 1s 2ms/step - loss: 0.0733 - accuracy: 0.9808 |
| 3-4사이 3.5 |
predictions = model(x_train[:1]).numpy() print(predictions.shape) print(predictions) |

이어서 softmax()에 predictions을 입력하여 1회 계산을 시행해 본다.
| 3.7 | tf.nn.softmax(predictions).numpy() |

Cost 함수인 loss_fn을 구체적으로 정의한 후에도 함수를 계산해 보자.
| 4-5사이 | loss_fn(y_train[:1], predictions).numpy() |

첨부한 파일을 다운로드 받아 실행해보자.
그 외에도 텐서플로우 keras 관련된 버전으로 작성한 코드 mnist212.ipynb 도 다운받아 실행해 보고 비교해 보자. TensorFlow 버전은 계속해서 업데이트 됨에 유의하자.
학습과제: Colab MNIST292 예제 코드 은닉층 추가 수정
3-10절의 MNIST292 예제를 은닉층(hidden layer)을 하나 추가하여 코드를 수정후 Colab에서 실행시켜 보자. 784->128->10에서 784->256->64->10 구조로 은닉층을 수정하자.
| 8 | model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(256, activation='relu'), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) |
tf.keras.layers 접두어가 너무 다고 느끼면 헤딩에서 다음과 같이 정리해 보자.
| 9 | import tensorflow as tf from tensorflow import keras from tensorflow.keras.models import Sequential print("TensorFlow version:", tf.__version__) import matplotlib.pyplot as plt from tensorflow.keras.layers import Flatten, Dense, Dropout |
Sequential에서 명령들을 살펴보자.
| 10 | model = Sequential([ Flatten(input_shape=(28, 28)), Dense(128, activation='relu'), Dropout(0.2), Dense(10, activation='softmax') ]) |
첨부파일을 다운받아 실행해 보자.
'인공지능 응용 공학' 카테고리의 다른 글
| Colab에서 CNN을 사용한 Keras MNIST 코드 작성 (0) | 2023.01.22 |
|---|---|
| 인공지능 응용 공학 Image Classification (0) | 2023.01.20 |
| 구글 Colab에서 TensorFlow 버전 1.15를 사용한 MNIST 예제 (0) | 2023.01.11 |
| 구글 Colab 노트북 사용법 (0) | 2023.01.11 |
| 다층신경망(multilayer neural network) 확장 (0) | 2023.01.11 |