
이진 분류(binary classification) 예제에서 입력 데이터에 대한 단위 신경망의 출력은 판별이 가능하도록 라벨값을 “1” 과 “-1”( 또는 “0”)로 설정된다. 따라서 학습과정에서는 주어진 학습데이터인 라벨값에 맞춰 Cost 함수의 Gradient Search 기법을 성공적으로 적용하면 학습 결과 가중치(weight)가 결정된다. 2종류 이상의 분류(classification)를 위한 종류 수가 많아지게 되면 머신러닝 작업을 위한 적절한 암호화 표기 체제가 필요하게 되며, 그 대표적인 사례가 one hot 코드이다.
MNIST 예제에서는 0~9까지의 10종류 수기문자를 분류해야 하며 위 표와 같은 one hot 코드가 사용된다. 10 종류의 서로 독립적인 클라스를 표현하기 위해서는 10 비트의 리스트 데이터로 사용하며 각 숫자 클라스 별로 0 이 아닌 1 의 위치가 1회씩 사용되어 10 비트의 합은 항상 1.0 이 된다.
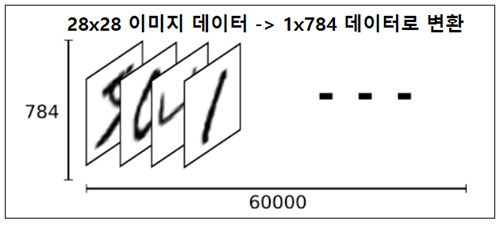
MNIST 문제에서 각 수기 숫자별로 6,000개씩 합계 60,000개의 데이터를 사용하여 가중치를 학습시킨다. 수기문자 하나 하나는 아래 그림처럼 28x28 매트릭스 데이터로 0~255 사이의 숫자를 사용하여 표현이 가능하다. 머신러닝 처리를 위해서는 28x28 매트릭스를 1열로 된 1x784 메트릭스 X로 변환할 필요가 있다.

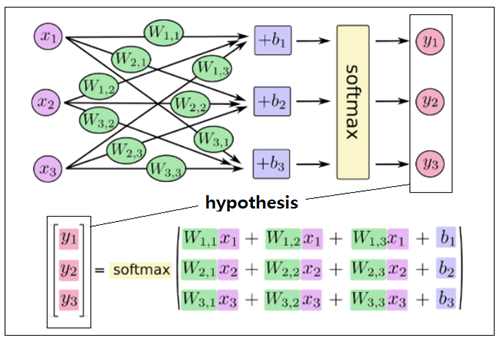
1x784 입력 데이터 X를 784x784 크기의 가중치 매트릭스 W와 1x784 편향(바이어스) b를 사용하여 변환시켜 1x10 hypothesis를 연산하고
softmax 를 적용하여 1x10 확률을 계산하고 정답 라벨과 비교한다..
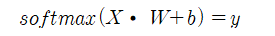
※ 함수 softmax 는 파이선이 아닌 Tensorflow에서의 함수명이기도 하지만 많은 경우에 동일한 함수명을 사용하여 프로그래밍 한다.
편향을 포함한 가중치 학습은 랜덤 수로 초기화된 값을 부여하여 연산을 실행하는데 당연히 정답 라벨에 해당하는 one hot 코드와 일치하지 않는다. 즉 오차가 발생한다. 이 오차를 줄이기 위해 경사하강법을 적용하자. 즉 현재의 가중치에서 Cost 함수의 편향 및 가중치에 대한 편미분에 의해서 기울기를 계산 후 learning rate를 곱하여 뺀 업데이트된 신규 편향 및 가중치를 사용하여 hypothesis y를 다시 계산한다, 경사하강법은 Cost 함수의 최소값에 도달하게 되어 기울기 값들이 거의 0.0 에 근접하여 변화가 없어지면 종결된다. 아울러 경사하강법을 적용하는 레이어가 다층으로 확장되면 오차역전파법(back-propagation)에 의한 체계적인 연산이 필요하게 된다.
충분한 학습이 이루어진 후 임의의 학습데이터를 뽑아 적용해 보면 당연히 거의 100%에 가까운 인식률을 보여주게 된다. 하지만 동일한 품질의 validation data 10,000 개를 적용해 보면 거의 유사한 결과를 주긴 하지만 아무래도 “1”에 해당하는 특정 비트값이 1.0 보다 작은 분포를 보여주게 되므로 파이선의 argmax 명령을 사용하여 계산된 10 비트의 값 중에서 가장 큰 비트를 찾아 이미 알고 있는 정답 라벨값과 비교 후 일치하면 인식 성공으로 처리하게 된다.
'인공지능 응용 공학' 카테고리의 다른 글
| 구글 Colab 노트북 사용법 (0) | 2023.01.11 |
|---|---|
| 다층신경망(multilayer neural network) 확장 (0) | 2023.01.11 |
| 텐서플로우 다변수 선형회귀법 예제: Antique Grand farther’s clock (0) | 2023.01.03 |
| 텐서플로우 선형회귀법 예제 (1) | 2023.01.03 |
| Information Bit Number 및 Entropy 계산 (0) | 2022.11.08 |