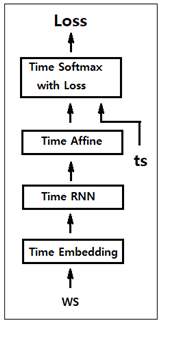
헤더 영역에 필요한 라이브러리들을 선언하자. 1 import os import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.constraints import maxnorm from keras.optimizers import Adam from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.utils import np_utils import numpy as np import time import matplotlib...