1. Principal Component Analysis, 1901년
통계학의 Pearson 분포로 유명한 Karl Pearson 이 제시한 차원 감축(Dimension Reduction) 분류 이론인 PCA(Principal component analysis) 기법은 사실상 기계공학 분야에서도 재료역학의 평면응력 텐서 변환을 다루는 Mohr’s Circle 이론을 차용했음을 밝히고 있다. 가장 오래된 머신러닝 이론이기도 하다.

다음 그래프의 수많은 점 데이터는 (x, y) 좌표계에서 2차원 분포를 하고 있지만 선형 변환에 의해 (PC1, PC2) 조표계로 변화하면, PC1 축을 따른 변화량 또는 분산 값이 최대이며 반면에 PC2 축 기준으로는 변화량이 최소화되는 축이기도 하다. 따라서 주축 PC1을 기준으로 하는 일차원적 분포로 근사화 할 수 있을 것이며, 즉 2차원에서 1차원으로 차원수가 감소 되었다고 볼 수 있을 것이다.

2. Linear Discriminant Analysis, LDA, 1936년
영국의 바이오 통계학 교수였던 Fisher 교수가 1936년도에 논문으로 발표한 Irish Flowers Classification 문제는 바이오 통계 분류이론 분야의 고전적인 걸작으로 알려져 있다. 특히 차원 감축과 관련하여 머신러닝을 연구하는 사람이라면 누구나 다 Scikit_learn 라이브러리를 통해 LDA 를 접해 보았을 것이다. 다양한 classification 기법들이 연구 되었지만 Irish Flowers 데이터 세트를 통해 벤치마킹을 해보면 Fisher 교수의 LDA 가 보여주는 결과가 가장 뛰어남을 알 수 있다.
1936년도에 Irish flowers 데이터 세트 150개를 대상으로 연구해서 발표한 LDA 이론을 사용하여 얻어낸 가시적인 결과는 따로 없는 듯하다. 하지만 오늘날 그의 LDA 기법을 통해 차원 축소작업 후 결과를 비교해 보면 놀라지 않을 수 없었다는 지적을 해 두고자 한다. 컴퓨터는커녕 계산기도 없던 시대에 그렇게 뛰어난 알고리듬을 제시했다는 것이 믿어지지 않을 정도이다. 바이오 통계학 분야에서 많은 업적을 세운 Fisher 교수는 다윈이즘의 성공적인 후계자로 여겨진다.
※ 한편 LDA 에 사용되었던 Irish Flowers(붓꽃) 데이터세트는 하버드대 식물학자였던 Edgar Anderson 교수가 영국 연구휴가 기간 중 morphology 연구를 통해 얻어진 귀중한 자료임에 유의하자.
3. Hubel & Wiesel 고양이 시지각 연구: CNN 의 과학적 출발점
1959년에 이미 하버드 의과대학 연구소에서는 인간과 동물의 시각피질(Cortex)의 특성에 관한 연구가 시작되었으며 그 공로로 1981년 생리학 분야의 노벨 수상자가 되었다.
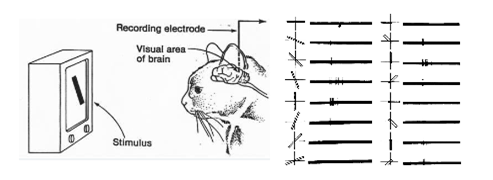
연구내용은 고양이 뇌 시각피질에 반응 전압을 측정하기 위한 전극을 꽂은 상태에서 흑백 TV 화면에 엣지형 바를 생성하여 병진, 회전 조작을 가하면서 고양의 시각피질의 반응 전압을 측정하였다.
이 최초의 연구로부터 현재의 Convolutionary Neural Network 즉 CNN 이 이 유래되어 본격적인 이미지 분류(image classification)가 가능해졌고 아울러 컴퓨터 비젼 기술도 탄생 되었다는 점이다. 특히 인텔의 컴퓨터 비젼 지원 라이브러리인 OpenCV에서 사용하는 Canny 필터나 Sobel 필터가 바로 이미지의 에지(edge) 의 형상과 움직임을 추적하는 대표적인 명령들이다. 아래 블로그에서 자율주행 차량의 차선 검출을 위한 Canny 필터 응용 사례를 참고하자.
참조: OpenCV Hough Transform에 의한 차선 작도 VII
http://ejleep1.tistory.com/1380
1998년 뉴욕주립대 LeCUN 교수가 수기문자판독(MNIST) 문제를 해결하기 위해서 창안한 LeNet 이 바로 CNN 기술의 구체화로 볼 수 있을 것이다.

4. Multilayer Gradient Search 와 오차역전파법(back-propagation)
Widraw 교수에 의한 Cost 함수 도입 이래로 이 함수의 최소화를 달성하기 위한 수치해석 기법으로서 Gradient Search (Steeptest Descent) 기법이 연구되어 오늘날까지도 많이 사용되고 있다. 하지만 Rosenblatt 교수가 사고로 사망한 1973년 이전까지 단일 계층 퍼셉트론 및 신경망에 국한하여 연구되었고 이로 인해 비선형 문제로 분류되는 XOR 문제를 해결 할 수 없었다. 물론 그 당시에도 다층 레이어 도입에 의해 XOR 문제 해결이 가능하지 않겠느냐는 아이디어는 있었을 것이다.
하지만 바로 앞 에서도 언급되었지만 출력이 합성함수이기 때문에 다층 문제에서 Cost 함수의 (편)미분을 연산 처리할 수 있는 특별한 알고리듬이 요구되었다.
다음 그림을 참조하면서 일반적인 다층 신경망 구조를 살펴보자.
⓵ 입력층은 데이터세트로부터의 입력을 나타낸다.
⓶ 노드는 단위 뉴론으로서 가중된 입력값을 합산한 후 활성화 처리한다.
⓷ 은닉층의 수가 커질수록 Deep하며 은닉층의 노드 수가 많을수록 Wide 하다.
④ 은닉층(hidden layers) 의 Deep 한 규모와 Wide 한 규모는 네트워크 설계자가 결정하여 노드들과 네트워킹 한다.
⑤ 데이터를 입력 받아 뉴론에서 정의된 연산을 수행하기 위한 가중치는 거의 랜덤하게 초기화하여 사용한다. 드물게 0을 사용하는 경우가 있을 수 있다.


일때에 출력 Z에 대한 합성함수는 다음과 같이 나타낼 수 있으며, 이와 같은 다층 레이어 구조의 입력 출력 관계식에서 Gradient Search 기법을 사용하려면 각 중간 단계의 출력의 가중치에 대한 편미분을 계산해야 할 필요가 있다.
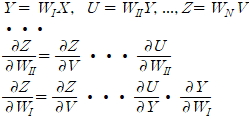
합성함수의 편미분 계산 알고리듬에 의하면 각 레이어 별 편미분들이 곱해지는 형태이므로 딥 레이어 구성에서는 결국 활성화 함수들의 여러번 누적해서 곱해져야 하기대문에 활성화 함수의 (편)미분 값이 극히 작을 경우 그 결과는 금방 0.0 이 되어버리기때문에 소위 말하는 “Vanishing Gradient” 문제가 발생한다.
Back-propagation 알고리듬 구현은 다소 복잡해보이는 측면도 있을 수 있기 때문에 한빛미디어에서 발간된 사이토 고키의 “Deep Learning from Scratch: 밑바닥부터 시작하는 딥러닝“ 옮김편을 참조하기 바란다.
머신러닝 연구에서 back-propagation 알고리듬의 이해는 필수적이기는 하지만 이미 TensorFlow 나 PyTorch 에서 지원이 되고 있기 때문에 커신러닝 코딩 작업에서는 스위치를 ON OFF 하는 개념으로 사용하면 된다는 점을 지적해 두겠다.
하지만 Rosenblatt 교수 사후 근 20년간 미국의 인공지능 분야 R&D 투자가 전혀 없는 동면기가 이어졌다. 전 세계적으로도 극소수만이 인공지능 즉 머신러닝을 연구하였다.즉 1986년까지 산발적인 연구들이 있었으나 Rumelhart, Hinton & Williams 의 연구를 기준으로 backpropagation 이란 용어와 알고리듬이 확산되었다. 그 중 당시 박사과정이었던 Geoffery Hinton 은 후일 캐나다의 터론토 대학에서 교편을 잡았으며, 2009년에 Bengio 교수와 함께 활성화 함수 ReLU 의 활용을 통해 Vanishing Gradient 문제를 해결하여 딥러닝 분야에 혁혁한 업적을 세웠다. 아울러 LeNet 의 발명자인 LeCUN 교수도 1980년대 말 박사후과정을 통해 토론토 대학을 거쳐 벨랩에서 MNIST 프로젝트를 성공적으로 수행하였다.
'인공지능 응용 공학' 카테고리의 다른 글
| 통계역학의 볼츠만 확률분포와 엔트로피, Cross Entropy (0) | 2022.11.08 |
|---|---|
| TensorFlow solution of x - 1.12345 = 0 (0) | 2022.11.05 |
| Wine 데이터와 PCA(Principal Component Analysis) 처리 (0) | 2022.11.02 |
| 인위적으로 생성한 2그룹 데이터를 이용한 퍼셉트론 예제 (0) | 2022.10.30 |
| 뉴론의 구조와 퍼셉트론, Shannon의 엔트로피, Cross Entropy? (0) | 2022.10.30 |