퍼셉트론이나 지금의 신경망이나 단위 구조는 동일하다. 다수의 입력에 대해서 출력은 최소 “1” 과 “-1”( 또는 “0”)을 식별할 수 있는 이진 출력이 가능하다. 경우에 따라서는 분류(classification) 목적에 따라 그 이상의 라벨 값들을 가질 수 있다. 예를 들너 MNIST 수기문자판독문제는 “ ~9”까지의 10개, 그리고ImageNet 은 1000개의 라벨 값을 가진다.
2개의 변수로 표현되는 입력 데이터로는 평면 좌표계를 들 수 있다. 이런 입력 데이터에 대한 단위 신경망은 다음과 같이 나타낼 수 있다. 이진분류 시 출력 y 가 “1” 과 “-1”( 또는 “0”)인지 식별할 수 있어야 할 것이다.
아래의 퍼셉트론 예제는 인위적으로 생성한 golden eagle 과 horned owl 2종류의 데이터 그룹을 대상으로 하며 라이브러리는 수학지원 numpy 와 그래픽지원matplotlib 를 사용하도록 한다.
일단 각 그룹별 x 좌표는 날개 길이, y 좌표는 조류의 무게로 하여 각각 5개의 데이터를 만들도록 하자. 파이선 numpy 라이브러리의 random.randint()를 사용하여 170~230 사이의 랜덤한 정수를 5개 생성시켜 100으로 나눈 값을 golde eagle의 날개 길이 데이터로 , 60~100 사이 랜덤 정수 데이터는 horned owl 날개 길이 데이터로 삼자.
조류들의 중량은 좀 다른 계산식을 사용하여 golden eagle 이 horned owl 보다 훨씬 무겁도록 식을 조작하여 생성한다.

이 두 데이터를 concatenate 하면 5개씩 데이터가 연이어진 합계 10개의 데이터가 된다. 즉 X 데이터는 좌표 (bird_wingspans, bird_weights) 형태로 10개의 데이터가 준비된다. 아울러 라벨값은 goldeeagel 5개는 np.zeros(5) 명령을 사용하여 “0”으로 horned owl 은 np.ones(5)를 사용하여 “1”로 처리한다.

현재 해설하는 코드를 아나콘다에서 실행 후 셸(Shell)에서 출력해 보면 다음과 같다.

matplotlib 로 출력해 보자. 이 데이터들에 대해서 퍼셉트론이 할 수 있는 인공지능의 역할은 무엇일까 잘 생각해 보자. 만약 “어떤 조류의 날개 길이와 중량이 별 모양으로 주어져 있으면 과연 이 조류는 어느 종류에 속할까?” 하는 문제이다. 이 문제에 답하려면 양쪽의 데이터를 근거로 golden eagle 과 horned owl 의 영역을 식별할 수 있도록 선을 하나 결정해서 그어야 할 것이다. 이 선을 decision boundary 또는 hyperplane 이라고 한다. 즉 별표 샘플의 위치가 이 선 위냐 아니면 밑이냐에 따라서 종류가 결정되는 것이다.

따라서 퍼셉트론이 인공지능이라면 주어진 데이터를 사용하여 hyperplane을 정확하게 설정할 수 있어야 할 것이다.
※ 라벨값 암호화 설정과 One Hot Code
이진 분류(binary classification) 예제에서 입력 데이터에 대한 단위 신경망의 출력은 판별이 가능하도록 라벨값을 “1” 과 “-1”( 또는 “0”)로 설정된다. 따라서 학습과정에서는 주어진 학습데이터인 라벨값에 맞춰 Cost 함수의 Gradient Search 기법을 성공적으로 적용하면 학습 결과 가중치값이 결정된다.
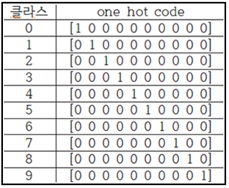
2종류 이상의 분류를 위한 종류수가 많아지게 되면 머신러닝 작업 적절한 암호화 표기 체제가 필요하게 되며, 대표적인 사례가 One Hot 코드이다. MNIST 예제에서는 0~9 까지의 10종류 수기문자를 분류해야 하며 위 표와 같은 One Hot Code 가 사용된다. 10종류의 서로 독립적인 클라스를 표현하기 위해서는 10 비트의 데이터 리스트를 사용하며 각 숫자 클라스별로 0 이 아닌 1 의 위치가 1회씩 사용되어 10 비트의 합은 항상 1.0 이 된다.
각 수기 숫자별로 6,000 개씩 60,000 개의 학습 데이터를 사용하여 가중치를 학습시킨 후 임의의 학습데이터를 뽑아 적용해 보면 당연히 거의 100% 에 가까운 인식률을 보여주게 된다. 하지만 동일한 품질의 validation data 10,000 개를 적용해 보면 거의 유사한 결과를 주긴하지만 아무래도 “1”에 해당하는 특정 비트값이 1.0 보다 작은 분포를 보여주게 되므로 파이선의 argmax 명령을 사용하여 계산된 10 비트의 값 중에서 가장 큰 비트를 찾아 이를 이미 알고 있는 라벨값과 비교 후 일치하면 인식성공으로 처리하게 된다.
머신러닝 많은 분야에서 이 기법이 채택되고 있으나 자연어 처리과정으로 넘어가게되면 다루어야 할 어휘 수가 백만을 넘어서게 되므로 On Hot Code 체계도 심한 컴퓨팅 부담의 원인이 되고 있다.
※
다음 그림은 퍼셉트론 네트워크 구조를 나타낸다. 입력항 xi 가 가중치 wi 를 적용한 후 편향 값을 반영하여 y 가 연산되며 y 에 대해 문턱값 처리 후 출력이 일어난다.

생체 내에서는 다수의 뉴론들이 엮여있는 것처럼 이러한 단위 뉴론 구조를 어떻게 복합적으로 직병렬 연결할 것인지 고려해보자.
아래 그림에서는 입력데이터가 복합적으로 처리되는 신경망 사례를 나타낸다. 하나의 입력 데이터는 1X2 리스트 데이터로 표현될 수 있으며 이에 상응하는 가중치 매트릭스는 2X1 리스트 데이터 구조로 주어질 수 있음에 유의하자.
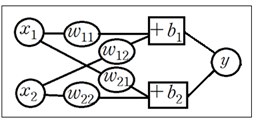
실제로 MNIST 수기문자 판독을 위한 단일 레이어 머신러닝 코드 작성 시 하나의 문자 28X28=784 이미지 데이터는 1X784 리스트 데이터로 표현되며 이에 상응하는 가중치 매트릭스는 784X10 리스트 데이터 구조로 사용됨에 유의하자.
단일 레이어 신경망을 아래와 같이 2단 구조로 확장해 보자. 2단에서는 bias(바이어스, 편향) 항을 무시하였다. 필요하다면 1단과 유사하게 도입하면 된다. 레이어 수를 늘릴수록 가중치와 바이어스 항이 상당히 많이 늘어남을 알 수 있다.
이 신경망 구조에서는 다음과 같이 입력, 가중치, 편향을 사용하여 출력이 정의 된다.


가장 핵심적인 클라스 Perceptron 은 다음과 같이 구성된다.
class Perceptron(object): 에서 object 는 메인 프로그램에서 learn_rate=0.1 과 iterations=50 에 해당한다.
ppn = Perceptron(learn_rate = 0.1, iterations = 50)
이와같이 파라메터 값을 부여하여 클라스 Perceptron 을 실행하면 인스턴스 ppn 이 연산된다.
__init__ 은 클라스의 인스턴스(instance)를 한번 연산할 때 변수들의 초기화를 담당한다.
메인에서 제공한 파라메터 변수명에 self. 처리를 해야 클라스 내에서 사용이 가능하다.
※ 인스턴스란 파라메터 오브젝트들을 인수로 하여 클라스 루틴을 호출할 때 얻어지는결과물이다.
클라스 Perceptron 은 다음과 같은 클라스 내에 정의되는 함수 즉 메서드(method)를 가진다.
메서드들은 필요시 메인 프로그램에서 class 루틴명을 상속하여 사용할 수 있다.
def fit(self,X,y,biased_X=False):
def _net_input(self, X):
def predict(self, X, biased_X=False):
def _add_bias(self, X):
def _initialise_weights(self, X):
class 루틴 내에서 사용하는 self 변수는 클라스 내부에 한하여 자체적으로 constructor에 의해 생성되는 즉 init 에 의해 생성되는 파라메터 변수들을 주고 받는데 필수적으로 사용된다. 메서드 괄호 내에 인수 self 를 적어 놓으면 모든 self.... 변수들이 메서드 내에서도 통용된다는 의미이다.
메서드 initialize_weights 애서는 self 파라메터들을 넘겨받아 변수 X.shape[1] =2 에해당하는 2개씩의 가중치를 랜덤하게 생성한다.
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
class Perceptron(object):
""" Perceptron for demonstrating a binary classifier """
def __init__(self, learn_rate = 0.01, iterations = 100):
self.learn_rate = learn_rate
self.iterations = iterations
def fit(self, X, y, biased_X = False):
""" Fit training data to our model """
X = self._add_bias(X)
self._initialise_weights(X)
self.errors = []
for cycle in range(self.iterations):
trg_error = 0
for x_i, output in zip(X, y):
output_pred = self.predict(x_i, biased_X=True)
trg_update = self.learn_rate * (output - output_pred)
self.weights += trg_update * x_i
trg_error += int(trg_update != 0.0)
self.errors.append(trg_error)
return self
def _net_input(self, X):
""" Net input function (weighted sum) """
return np.dot(X, self.weights)
def predict(self, X, biased_X=False):
""" Make predictions for the given data, X, using unit step function """
if not biased_X:
X = self._add_bias(X)
return np.where(self._net_input(X) >= 0.0, 1, 0)
def _add_bias(self, X):
""" Add a bias column of 1's to our data, X """
bias = np.ones((X.shape[0], 1))
biased_X = np.hstack((bias, X))
return biased_X
def _initialise_weights(self, X):
""" Initialise weigths - normal distribution sample with standard dev 0.01 """
random_gen = np.random.RandomState(1)
self.weights = random_gen.normal(loc = 0.0, scale = 0.01, size = X.shape[1])
return self
def plot_decision_regions(X, y, classifier, resolution=0.1):
#setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape )
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
#plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=cl,
edgecolor='black')
# data generation __________________________________________________________________________
bird_wingspans = np.concatenate([np.random.randint(170, 230, size = 50)/100.0,
np.random.randint(60, 100, size = 50)/100.0])
bird_weights = np.concatenate([(11 - 10)*np.random.randn(50)+10, np.abs(np.random.randn(50))+1])
# combine X vectors into a 2-dimensional array with 100 rows and 2 columns
X = np.vstack((bird_wingspans, bird_weights)).T
# create labels for our input data - first 50 are Golden Eagles (binary 0), last 50 are Horned Owls (binary 1)
y = np.concatenate([np.zeros(50), np.ones(50)])
# confirm shapes of generated data
print("The shape of our input matrix, X, is: {0}.".format(X.shape))
print("The shape of our output vector, y, is: {0}.".format(y.shape))
# plot our data on a scatter graph using matplotlib
# first 50 samples = Golden Eagle - plot both input features (columns 0 and 1 of X)
plt.scatter(X[:50, 0], X[:50, 1], color='r', marker='o', label='Golden Eagle')
# last 50 samples = Horned Owls
plt.scatter(X[50:, 0], X[50:, 1], color='b', marker='x', label = "Horned Owl")
plt.title("Bird Classification Sample Data")
plt.xlabel("Wingspan (metres)")
plt.ylabel("Weight (kilograms)")
plt.legend(loc = 'upper left')
plt.xlim([0, 2.5])
plt.ylim([0, 14])
plt.show()
#_____________________________________________________________________________
# create a perceptron classifier and train on our data
ppn = Perceptron(learn_rate = 0.1, iterations = 50)
ppn.fit(X, y)
# plot our misclassification error after each iteration of training
plt.plot(range(1, len(ppn.errors) + 1), ppn.errors, marker = 'x')
plt.title("Visualisation of errors")
plt.xlabel('Epochs')
plt.ylabel('Errors')
plt.show()
plot_decision_regions(X, y, classifier=ppn, resolution=0.01)
plt.xlabel('Wingspan length [cm]')
plt.ylabel('Weight [kilograms]')
plt.legend(loc='upper left')
plt.show()
'인공지능 응용 공학' 카테고리의 다른 글
| 신경망(Neural Network) 연구의 역사 (0) | 2022.11.02 |
|---|---|
| Wine 데이터와 PCA(Principal Component Analysis) 처리 (0) | 2022.11.02 |
| 뉴론의 구조와 퍼셉트론, Shannon의 엔트로피, Cross Entropy? (0) | 2022.10.30 |
| Iris flower data를 이용한 Rosenblatt 퍼셉트론 파이선 코딩 (3) | 2022.10.29 |
| Rosenblatt N = 2 Perceptron Weight Update 알고리듬 Processing 코딩 (0) | 2022.10.27 |