1. 컨볼루션 네트워크(CNN, Convolutional Neural Network)

위 그림은 1981년 노벨 의학상을 수상하게 되었던 하버드 의대의 후벨(Hubel) 박사의 1959년도에 실시된 고양이 시각피질(visual cortex) 반응 실험 연구내용이다. 즉 고양이의 시각피질에 전극을 꽂은 상태에서 흰색 배경의 흑백 TV에서 기울어진 검정색 막대 모양을 병진 또는 회전시키면서 자극을 주게되면 일어나는 전기적 반응을 오디오로 들으면서 기록하였다.
이와같이 동물이나 인간의 시지각 현상을 신경망화 한 모델이 바로 CNN 이며 1990년대 말에 이르러서여 LeCun 교수의 LeNet을 통해 MNIST 수기문자 판독을 위한 알고리듬으로 사용되어 그 뛰어난 특성이 알려졌다.

CNN 은 레이어 별로 점차 많은 수의 디지털 필터를 사용하면서 Pooling 작업에 의해 특징 맵(feature map)의 크기를 줄여 나간다. 마지막 단계에서 이들을 일차원적으로 flatten 하여 완전연결계층(fully connected layer)에서 딥러닝을 통해 학습이 이루어진다.
디지털 필터링 과정에서는 이미지 픽셀 해상도 대비 적정 규모의 커늘을 사용하여 이산적으로 스트라딩 시키는 과정을 통해서 이미지 내의 모든 픽셀들의 값을 주변 및 자체 픽셀 값들의 웨이팅 된 값들로 연산이 이루어진 후 활성화 함수를 적용하고 Pooling 작업에 의해 특징 맵의 크기를 줄인다. 물론 첫 시작단계에서 초기 웨이트 값은 무작위 수로 적용하여 옵티마이저에 의한 손실함수를 최소화 할 수 있도록 학습을 통해 웨이트 값이 결정된다.
참조: 1990년대 말 CNN 응용의 길을 튼 LeCUN 교수의 LeNet-5 CNN 모델을 실습해보자.
https://ejleep1.tistory.com/1561
2. AlexNet, VGG16, ResNet
1998년 LeNet 발명 이후로 10 여년간 MNIST에 관한 알고리듬 벤치마킹이 활발히 이루어진 이후 20212년 스탠포드대에서 주최한 ILSVRC 컨퍼런스에서 AlexNet 이 우승한 이 후 CNN을 기반으로 하는 Image Classification 분야가 급속히 발전하였다.
LeNet 에 있어서 인식(지)의 목표는 이미지에 포함된 하나의 객체가 무엇인지 알아내는 비교적 간단한 문제였지만 AlexNet 이후로부터는 이미지에 포함된 여러 이미지들이 무엇인가를 인식하는 인간과 거의 비슷한 인식능력을 시험하는 단계로 발전하였다.
LeNet-5는 CNN을 개척한 LeCUN 이 제시한 컨볼루션 뉴럴 네트워크이다. 32X32 이미지는 1024 비트 즉 1K 비트급 이미지로서 일 단계 Convolution 처리 과정의 첫 번째 Convolution에서 6개의 5X5 필터를 사용하여 28X28 이미지로 크기를 축소한 후 두 번째로 Subsampling 즉 Max-Pooling 작업을 통해 6개의 더욱 축소된 14X14 이미지를 추출한다.
1998년 당시에는 없었지만 2010년 이후 지금은 Convolution 처리 후 반드시 활성화 (Activation) 처리를 하게끔 변모하였다. 일 단계 Convolution 작업 이후 동일한 방법으로 이 단계 처리를 한 후에 Fully Connected 충과 인터페이스 한다. Fully Connected 란 Depth를 가지는 딥러닝 레이어 구조에서 Width를 최종적으로 주어진 Class 라벨 수만큼으로 줄이는 처리 과정으로 이해하도록 하자.
| 32X32(1024)→6X28X28(4704)→6X14X14(1176) →16X10X10(1600)→16X5X5(400) |
Convolution 작업의 중요한 역할은 edge 요소를 포함한 이미지의 특징(features)을 잘 유지 보존하는 선까지 픽셀 수를 줄여 특징맵 (feature map)을 작성한다.
특징 추출 작업이 완료되면 400 픽셀에서 다시 120, 84 를 거쳐 최종적으로 10개의 Class로 분류 작업을 실행한다. 대표적인 예제가 MNIST와 CIFAR10 이다.
LeNet 은 흑백 이미지 CNN 이었으나 2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 컨퍼런스에서 발표된 AlexNet은 120만 개의 이미지를 1000 종으로 분류하는 고해상도의 컬러 이미지 ImageNet 전체를 제대로 학습할 수 있었던 최초의 알고리듬이 되었다. Stochastic Gradient Descent 인 SGD 옵티마이저를 사용하였으며 총 8단의 레이어를 사용하여 상위 Top 5 error rate 기준 84.6% 의 정밀도를 성취하였다.

Top 5 error rate 값 사용하는 이유는 매번 머신러닝 연산마다 초기치 설정의 랜덤성으로 인해 출력 결과에 변동이 있을 수 있다. 하지만 전체 클라스 확률의 합은 1.0 인데 최종 Fully Connected 레이어의 마지막 단의 softmax 에 의해 예측된 클라스별 라벨값의 확률분포 값 중 큰 순서로부터 정리된 값 5개 증 첫 번째가 타겟 라벨값과 일치하는 경우의 인식률을 의미한다. 학습에 걸린 시간은 터론토 대학교 GPU 컴퓨팅 소스를 몽땅 총동원해서 일 개월 이상 소요되었다고 한다.

AlexNet의 초기 인식률은 60% 전후 수준에 불과하였으나 이때부터 전 세계적인 Image Classification R&D 열풍이 일었으며 2013년 ILSVRC 컨퍼런스에서는 16 레이어로 구성되는 영국의 VGG16 architecture 가 두각을 나타내었고 2014년에 19 레이어의 VGG19 이 발표되었다.
VGGNet은 CNN 레이어 구조가 반복되는 단순한 구조를 가졌디. AlexNet 처럼 3X3 Convolution 작업에 상당히 많은 수의 필터를 사용하여 4개의 GPU 상에서 수 주간의 학습을 요한다. 특징 추출 능력이 뛰어난 반면에 사용하는 파라메터 수가 기하급수적으로 늘어나 1억4천8백만 개에 달한다.

AlexNet 과 비교할 때 VGG16 네트워크의 특징은 상대적으로 작은 컨볼루션 커늘 사이즈를 채택했다는 점이며 아울러 파라메터 수의 대폭 감축이 이루어진 아주 효율적인 네트워크로 평가된다. ImageNet을 대상으로 top-5 테스트 인식 정밀도 92.7% 를 기록했다.
아래 블로그에서 feature map 관찰기법을 살펴보고 아울러 AlexNet 과 VGG16 feature map 차이점을 관찰해보자.
참조: PyTorch VGG16 모델 활용 Feature Map 관찰기법
https://ejleep1.tistory.com/1202
그 이후에도 파라메터 수를 줄여 컴퓨팅 효율을 증가시키기 위한 차원에서 GoogleNet 을 비롯 MobileNet, SSD 가 제안되었다. 레이어 수가 무려 40개에 달할 정도로 길어진 GoogleNet의 특징을 살펴보자.

AlexNet 이후로 92% 인식률의 VGG를 거쳐 Inception 이라고도 불리우는 GoogleNet에 이르러서 인간 기준 인식률 95%의 문턱에 해당한다고 하는 94% 인식률에 도달함과 아울러 VGG의 파라메터 수 규모를 대폭 줄일 수 있도록 1X1 컨볼루션 필터 채용이 이루어졌다.
1X1을 사용하여 컨볼루션 작업을 하더라도 원 이미지의 크기에 변동이 없다는 특징과 함께 컴퓨팅 부담 경감이 가능하다는 이점이 있지만 대신에 레이어 수가 증가하게된다.

2015년 ILSVRC 승자인 ResNet은 가장 많은 수의 레이어를 채택하여 건너뛰는 형태의(skip connections) 알고리듬을 사용하여 인간의 인식률 한계로 알려진 95%를 돌파하여 96.43%를 달성하였다.
특히 ResNet은 반복적으로 152개에 달할 정도로 많은 수의 레이어를 사용하기 때문에 컴퓨팅 부담 또한 만만치 않으나 Batch Normalization 기법을 채택하여 파라메터 수를 대폭 경감시켰다. 이러한 기법은 MobileNet, SSD에서도 이미 사용되었다.

ResNet의 skip connection 알고리듬은 최근에 성공적인 RNN 레이어 구조로 알려진 GRU (Gated Recurrent Unit) 알고리듬과도 유사성이 대단히 큰 것으로 보인다. skip 알고리듬은 앞 레이어의 정보를 레이어 하나를 건너뛰어 전달하는데, 이는 역전파 연산에서 기울기 크기의 변동이 거의 없도록 억제하면서 그대로 전달해주는 특성이 있다. 상당히 높은 인식률을 보여준다는 점이 실증되었으며, ResNet 은 현재 Transfer Learning 예제 모델들에서 ResNet 학습 결과 중 가장 작은 모델로서 사전학습 (Pretrained) 된 ResNet18 이 많이 사용되고 있으며, 자율주행 차량에서도 시험적으로 사용되고 있다.
ResNet18 은 ResNet 중에서도 NVIDIA Tesla K80 GPU 4개를 사용하여 총 152개의 레이어를 사용 3주간의 학습에 의해서 얻어진 결과로서 정밀도가 괜찮아 작은 데모용으로 PyTorch의 torchvision 라이브러리에서 서비스되고 있다.
PyTorch에서는 ResNet18을 비롯하여 앞에서 언급했던 이미지 관련 네트워크의 가중치 학습 결과를 네트워크 명 +(Pretrained =True) 형태로 제공하고 있다. 학습에 엄청난 컴퓨팅 타임이 소요되는 것이 사실이지만 이미 학습한 결과 가중치 값들을 불러 쓴다는 것은 대단히 효율적인 코딩을 가능하게 한다는 점에 유의하자.
아래는 PyTorch에서 제공하는 사전학습 class 루틴 명단이며, 응용에 참고하자.

2. R-CNN, OpenCV Selctive Search
2012년 AlexNet으로부터 시작하여 2017년까지 ResNet 까지 ImageNet 을 대상으로 한 CNN architecture 들이 개발되었다. 한편 자율주행을 위한 카메라나 라이다 센서에 포착된 이미지를 완벽하게 분석하기 위한 보다 정교한 Image Classification 알고리듬들도 연구되었다. 그중 대표적으로 2014년 발표된 R-CNN (Regions with CNN) 알고리듬을 살펴보기로 하자.
Image Classification 작업에 있어 하나의 이미지를 CNN architecture를 사용하여 일괄적으로 한번 레이어를 적용하는 것이 아니라 하나의 이미지를 뭔가 객체를 포함하고 있을 가능성이 높은 크고 작은 영역들(Regions)로 일일이 찢어 proposal을 제시하고 CNN을 적용하여 객체를 인식하는 알고리듬이다. 물론 컴퓨팅 부담이 만만치 않으므로 그 문제를 해결하기 위해서 더 우수한 알고리듬들이 연구되었던 것도 사실이다.
R-CNN에서는 분류(classification)를 위해 수많은 영역들을 실행할 것이 아니라 선택적인 검색을 통해 2,000개의 영역들에 한해서 분류작업을 실행한다. 이러한 필터링 작업에 의해서 일반적인 객체 탐지 알고리듬보다 훨씬 빠른 성능을 보여 줄 수 있다.
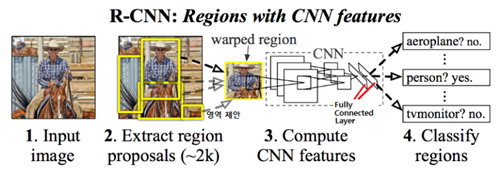
R-CNN 알고리듬을 다음과 같이 간략하게 요약해 보자.
1. Selctive Search를 통해 2000 개의 영역제안 이미지를 도출한다. Selctive Search 는 OpenCV 에 해당 명령어가 있다.
2. 각각의 제안된 영역별로 Ground Truth Data에 대한 IOU(Intersection over Union)를 계산하고 영역제안들에 라벨 값
을 부여한다. 이작업도 Selective Search 과정에서 내부적으로 계산된다.
3. 각 영역제안별로 CNN 및 Fully Connected 네트워크를 적용하여 각 영역 제안들에 대한
클라스 확률을 계산한다.
※ grounf truth data 란?
이미지 내에 포함된 객체들의 정답 라벨 데이터를 뜻하며 Obkect Detection 학습 시에 ground truth data 즉 object를 에워 싼 도형이 직사각형일 경우 대각선 꼭지점 좌표 위치 데이터를 의미한다. 만약 ground truth data 가 부정확하면 이를 근거로 계산되는 IOU 를 비롯하여 이미지 분석을 위한 파생 데이터들의 정밀도가 떨어지게 된다.
아래 사례들은 실제로 OpenCV 의 Selective Search에 의해 얻을 수 있는 영역 제안 사례이다. 중요한 객체들을 놓칠수도 있으나 2차적으로 anchor box를 사용하는 IOU 처리를 하면 웬만한 객체들은 다 체크할 수 있으므로 그다지 문제될 것은 없다.

아래 그림의 얼룩말들을 Selective Search 로 찾아낸다면 2단계로 각 얼룩말의 bounding box 들에 대해서 가로 세로 비율을 적절히 조절한 anchor box를 사용하여 빠뜨렸던 객체들이 있다면 찾아낼 수 있는 알고리듬이다. Faster R-CNN 에서 제안되었다,
주로 사용되는 Aspect Ratio 는 0.5, 1.0, 2.0, 이다.

https://ejleep1.tistory.com/1216
아래 url 첫 번째 동영상은 selective search 가 어떻게 이루어지는지 보여준다.
참조: Custom Object Detection Using Keras and OpenCV
RCNN을 중심으로 파생된 image classification 작업은 영역 제안을 도출 작업과 그 이후의 작업으로 2단계 처리됨을 알 수 있다. 반면에 YOLO (You Only Look Once) 모델에서는 한 번에 처리하기 위해서 적절한 크기의 메시(mesh)를 사용한 그리드 구성 환경에서 이미지 객체가 탐색되는 즉시 영역 제안을 하지 않고 직접 앵커박스 기법을 적용하여 추가 이미지들까지 탐색하는 스피디한 기법이 제안되었다. 특히 YOLO 버전3 코드는 오픈 소스로 공개되어 사용자가 직접 학습시킬 수도 있으며 아니면 COCO 데이터 세트에서 사전학습된 결과를 사용해도 된다. 윈도우즈 10 아나콘다에서 실시간 실행이 가능하다. 아울러 코드 구조가 단순해 응용목적으로 OpenCV 코딩에 끌어다 쓸 수 있는 장점이 있다.
더욱 성능이 개량된 YOLO 버전 4 도 오픈되었으나 버전 3 에 비해 사용법이 좀 더 복잡해 보인다. Colab 에서 GPU를 지원받아 실행할 수 있지만 영상 파일로 결과를 얻어낸 후 재생해서 봐야 하는 아쉬운 점이 있다.
'자율주행' 카테고리의 다른 글
| 9장 자율주행을 위한 이미지 머신러닝 III (0) | 2022.10.21 |
|---|---|
| 9장 자율주행을 위한 이미지 머신러닝 II (0) | 2022.10.21 |
| 7장 Mathworks 자율주행 MATLAB 코딩 (IV)고속도로 차선변경 (0) | 2022.10.21 |
| 7-4 HD 라이브 맵 레이어 구성 (0) | 2022.10.13 |
| 7장 MathWorks 자율주행 MATLAB 코딩 III(HD 맵) (0) | 2022.09.28 |