본 블로그 내용은 다음 url 주소의 코드 해설을 참조 하였음
https://androidkt.com/how-to-visualize-feature-maps-in-convolutional-neural-networks-using-pytorch/
feature map 은 앞 레이어에 적용된 필터의 출력을 뜻하는 바 이미지의 국부적인 픽셀 또는 작은 수의 픽셀들의 정보에 대한 뉴론들의 활성화 결과로서 object 고유의 정보 포함 유무와 아울러 이미지 내의 위치 정보를 포함한다. 아울러 상당히 많은 수의 필터를 사용하기때문에 필터 수에 비례하는 다양한 특징들을 추출해 낼 수 있다. 그 다음 이어지는 단계에서는 이미 웬만한 특징들이 추출되었기때문에 이들을 flatten 과정을 통해서 1차원으로 처리한 후 Fully Connected Layer 를 통해 클라스 라벨값들에 대한 확률계산 방식으로 softmax 학습을 시킬 수가 있다. 특징 추출이 잘되었을수록 학습이 당연히 잘 될 것이다.
한편 feature map들을 보여주는 CNN 관련 문헌들의 상당 수가 구체적으로 feature map 의 특징을 극명하게 보여주지는 못하는 것 같다. 그 대안의 하나로서 feature 추출 코드를 뽑아내어 예제 이미지를 분석해 보는 것도 좋은 방법이 될 수 있을 것이다. 즉 자신이 해볼 수 있는 도구를 마련해서 사용하는 것을 뜻한다.
feature 추출 코드 준비에는 AlexNet이라든지 VGG16이라든지 꽤나 유명한 image classification 코드를 이용할 수 있으며 여기서는 VGG16을 사용하기로 한다. feature map 을 보기 위한 방법으로는 다음의 3가지를 들 수 있다.
(i) Conv2d 만을 단계적으로 적용하는 법
(ii) Conv2d+ReLU 조합을 단계적으로 적용하는 법
(iii) Conv2d+MaxPooling2d 조합을 단계적으로 적용하는 법
위 3가지 방법 중에서 (i)과 (ii)기법은 최종 출력물 즉 feature map 의 크기가 변하지 않는다. 특히 (ii)기법에서는 이미지의 밝기가 극히 어두워진다. 한편 (iii)기법에서는 밝기는 그대로 유지되지만 이미지 크기가 축소된다는 특징이 있다.
순서대로 feature map 을 생성 시켜 살펴보자.
(i)
1. 헤더 영역에서 필요한 라이브러리들을 import 하자.

2. VGG16은 2012년 AlexNet에 이어 2013년 출현한 알고리듬이다.
사전학습된 결과 VGG((feature): Sequential((0):Conv2d(.... 를 불러오는 것을 볼 수 있다.

3. feature map 분석을 위한 이미지를 가져다 transform 하여 pytorch 텐서를 준비하고 아울러 그 결과물을 numpy array 처리하여 출력해 보자. 반드시 numpy array 처리해야 이미지를 출력해 볼 수 있음에 유의하자.
준비하는 이미지는 그림과 같이 다양한 edge들을 포함하도록 만드는 것이 좋다. 컨볼루션 , 활성화, MaxPooling 작업 후 어떤 edge 들이 추출되어 남아 있는지 확인해 보기 위해서다.

위 224x224 테스트용 이미지를 다음 그림에서 이미지 복사 하도록 하자. 일부러 특정한 형태의 edge 요소들을 많이 넣어 보았다. modelVGG 가 ImageNet 의 1000 종의 클라스로 학습이 되었기때문에 선과 간단한 모양의 도형으로 이루어진 테스트용 이미지의 특징 추출에는 아무런 문제가 없다.

modelVGG를 실행하여 Sequential 구조를 살펴보자.

아래의 VGG16 구조에서 Convolution 출현 횟수를 세어 보면 총 13회 임을 알 수 있다. 이 13개의 Convolution 레이어를 사용하여 특정 이미지에 대한 feature map 을 작성해 보자. ReLU는 이미지 크기에 영향을 미치지 않으며 MaxPooling 은 적용 시 이미지 크기가 감소하게 된다.
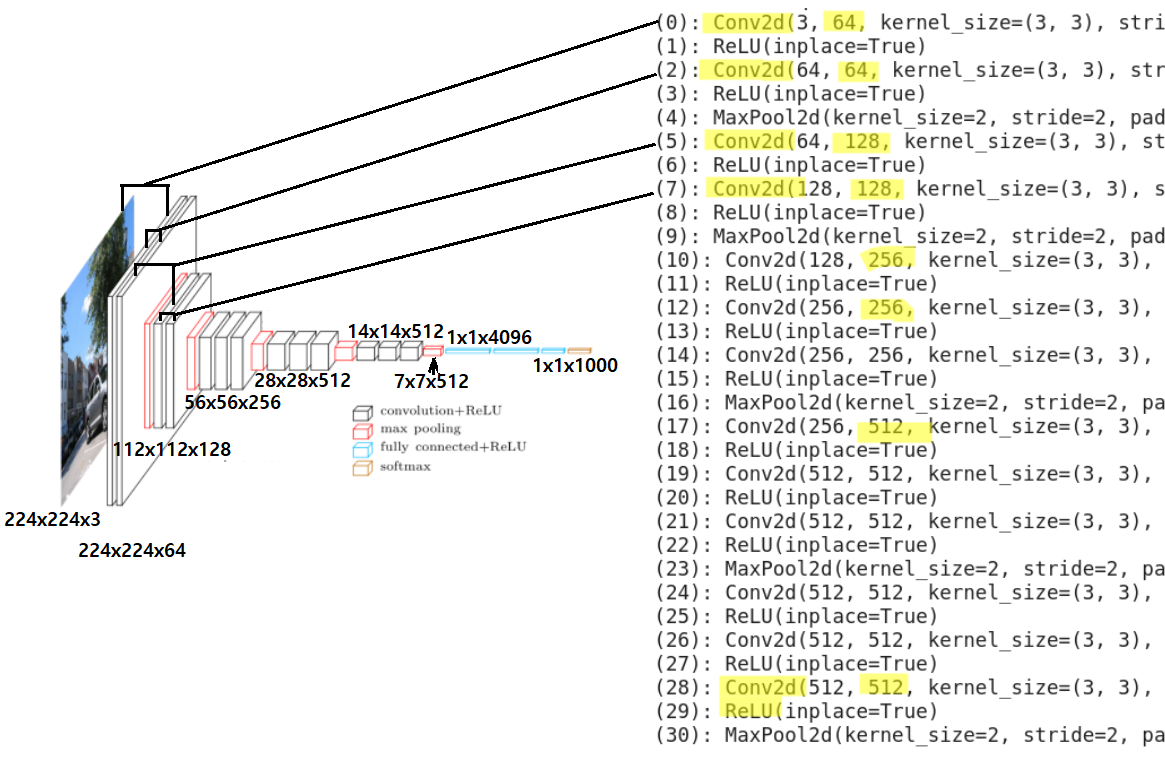
modelVGG 처리함에 있어서 children( )이란 명령이 나오는데 python 사전에서 설명을 찾아 볼 수 없어 아래와 같이 출력해 보니 VGG16 을 불러 온 결과 Parent 에서 앞부분을 뺀 나머지 알맹이만 추출하는 명령인 듯하다.

위 코드에서 처리된 conv_layers 를 출력해 보면 다음과 같이 모조리 Convolution 레이어들만으로 구성된 것을 학인할 수 있다. 즉 feature map 을 얻어내는데 activation 과 MaxPolling 은 feature 와 관련성이 적으므로 배제시킨 듯하다. 아울러 convolution layer 적용에서 stride=(1,1)이므로 적절한 수의 padding 을 더해 주면 convolution 실행 후의 이미지는 원래 이미지와 같은 크기를 가지게 된다. 이는 image classification 알고리듬 자체와는 차이가 날 수 있겠지만 feature 만을 필터를 사용하여 뽑아내어 보겠다는 점에서는 아무런 문제가 될 것이 없을 것이다.
[Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))]
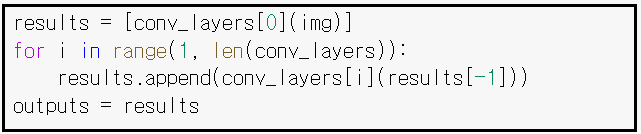
conv_layers의 0 을 설정하여 img 를 입력하여 첫번째 results 를 list 구조로 데이터화 하자.
그 다음 1에서부터 len(conv_layer) 까지 맨 마지막 하나 전 results 에 대하여 순차적으로 conv_layers[i] 를 적용하여 append 후 최종적으로 13개의 내용물을 가진 outputs 로 저장한다.
레이어 별로 결과를 출력하자.

feature map 처리된 마지막 결과에서 살아남은 feature들을 관찰해 보자. 물론 Layer1 부터 Layer13 까지 서서히 변화하는 내용을 세밀하게 관찰헤 보아야 할 것이다.

원 이미지와 feature map 중에 하나를 비교해 보자. 일정 부분 살아 남았음을 알 수 있다. 주로 경계쪽에 위치한 도형들이 많이 사라진 듯 하다. VGG16 모델의 특징이 아닐까 한다. 그래도 아직 미 출력된 부분이 있으므로 거기에는 빠진 정보들이 들어 있을 것으로 기대된다.

아래의 castle 이미지를 시험해 보자. AlexNet 보다는 VGG16 의 해상도가 좋아 보인다.


첨부된 파일을 사용자가 준비한 이미지를가지고 테스트해 보자.
{kind=link}
(ii) 지금까지의 출력 13회의 Conv2D 를 적용한 결과이다. 여기에 활성화 함수 ReLU 효과를 추가해보자. 이미지는 기하학적 특징이 강한 edge.jpg 를 사용하자. 레이어를 뽑아내는 코드를 다음과 같이 수정하여 실행하자. 출력 결과를 보면 Conv2D 이어 ReLU 가 들어있음을 알 수 있다. ReLU 는 MaxPooling 과는 달리 이미지 크기에 영향을 미치지 않지만 한번씩 활성화에 따라 밝기가 어두워지게 된다. 하지만 기하학적 특징들이 남아 있는지 조사하기엔 충분하다.

수정된 첨부 파일을 다운받아 실행 시켜 보자.
실행 결과 끝부분을 관찰해 보자. 좀 어둡긴 해도 기하학작 특징들이 손상되지 않고 살아있음을 확인할 수 있다. 결론적으로 feature map 특징들을 확인하기 위해서 굳이 ReLU를 넣을 필요는 없을 듯 하다.

(iii) 아래에서 처럼 layer에서 nn.MaxPool2d 를 찾아내어 append 작업을 하자. 총 13회의 Conv2d 와 3화의 MaxPool2d 가 있다.

Layer1으로부터 Layer11까지 어느 정도 특징 들의 윤곽이 잘 보이지만 이미지 픽셀수가 줄어듬에 따라 해상도 영향이 나타나기 시작한다.

그 이 후 이미지 변화를 보면 특징들이 점차 흐려져 인간의 시력으로는 파악이 어렵지만 기계적으로는 많은 수의 특징을 사용하므로 머신러닝에 의한 학습이 가능할 것이다.

한편 ReLU 적용 시 이미지가 어두워지지만 머신러닝 코드에서는 어두워진다는 것이 그다지 문제가 되지는 않을 것이다.
'Image Classification' 카테고리의 다른 글
| 윈도우즈10 아나콘다 YoLoV3 초간단 설치 (0) | 2022.01.24 |
|---|---|
| 윈도우즈10 아나콘다에 YoLoV3 를 설치하자. (0) | 2022.01.21 |
| 컴퓨팅 부하 경감을 위한 SeparableConv2D (0) | 2022.01.20 |
| 리메이크:PyTorch ResNet Semantic Segmentation 예제 (0) | 2022.01.08 |
| Google Colab에 의한 PyTorch AlexNet Image Classification (0) | 2022.01.08 |