※파이선 코딩 초보자를 위한 텐서플로우∙OpenCV 머신 러닝 2차 개정판 발행
http://blog.daum.net/ejleep1/1175
파이선 코딩 초보자를 위한 텐서플로우∙OpenCV 머신 러닝 2차 개정판 (하이퍼링크) 목차 pdf 파일
본서는 이미 2021년 11월 초부터 POD코너에서 주문 구입이 가능합니다. 참고로 책 목차에 따른 내용별 학습을 위한 코드는 이미 대부분 다음(Daum)블로그에 보관되어 있으며 아래에서 클릭하면 해당
blog.daum.net
이 예제는 첨부된 alexnet.ipynb를 다운받아 구글 드라이브에 옮겨 놓은 후 파일을 열어서 셀별로 실행하면서 내용을 읽어 보도록 하자.
2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 컨퍼런스에서 발표된 Alexnet은 흑백 이미지를 대상으로 하였던 LeNet에서 비해 고해상도의 컬러 이미지로 오브젝트 취급 법위를 확장하였으며 Classification 범위 내지는종류도 1000 종으로 확장하였다. 120만개의 이미지를 1000종으로 분류하는 ImageNet의 알고리듬 바탕이 되었던 것이 아닌가 한다. 여기서 사용된 기법을 정리해 보면 MNIST 텐서플로우 처리에서 정밀도를 올리기 위해 사용했던 모든 기법들이 동원되었으며 플러스해서 Transfer Learning에서 사용하는 기법인 data augmentation 과 ReLU까지 사용 되었으며 옵티마이저는 Stochastic Gradient Descent인 SGD를 사용하였고 총 8개의 레이어를 사용하여 상위 5개 샘플 오차( top 5 error rate)기준으로 84.6%의 정밀도를 성취하였다. Top 5 error rate 값을 사용하는 이유는 매번 연산 마다 랜덤성으로 인해 출력 결과가 변동이 된다. 하지만 전체 클라스 확률의 합은 1.0인데 최종 fully connected 레이어에서 softmax 에 의해 예측된 클라스별 확률분포 값 중 큰 값 5개 중에서 최대 값이 타겟 라벨 값과 일치하는 경우의 인식률을 의미한다. Nvidia Geforce GTX 580 GPU 2개를 사용하였으며 6일간 학습을 시켰다고 한다.

컬러 색상의 227X227 이미지 입력으로 이루어지는 AlexNet의 아키텍츄어를 살펴보자. MAX POOL 알고리듬에 3X3 커늘에 스트라이딩 값 2를 적용하는 바 이는 오버래핑을 허용하는 알고리듬이다. 위 AlexNet의 아키텍츄어는 다음과 같이 보다 입체적으로 표현할 수 있다. 윗 그림에서 사용한 이미지 해상도는 227X227X3임에 반해 아랫 그림은 위 AlexNet 을 기반으로 보다 효율적으로 개선한 VGG16 네트워크의 아키텍처이다. 표준 해상도가 224X224X3으로 다소 차이가 있음에 유의하면서 단지 AlexNet의 입체적 흐름만 관찰해 보기 바란다.
전체적으로 크기를 줄여나가는 Convolution 레이어들과 마지막 부분의 Fully Connected Layer 구조로 이루어짐을 알 수 있다. Fully Connected Layer 는 우리가 잘 아는 hidden layer 를 포함하는 딥 러닝 레이어로서 마지막에 시스템의 주어진 classification class 수에 해당하는 라벨 값을 학습 시킬 수 있도록 softmax 명령이 사용된다.

그밖에 특기할만한 알고리듬으로서 다단 뉴럴 네트워크 적용에 따른 큰 수의 생성과 gradient 값의 굽속한 감쇠를 방지하기 위한 ReLU에 이은 batch normalization (해설참조:https://blog.daum.net/ejleep1/1206)과 data augmentation을 들 수 있다.
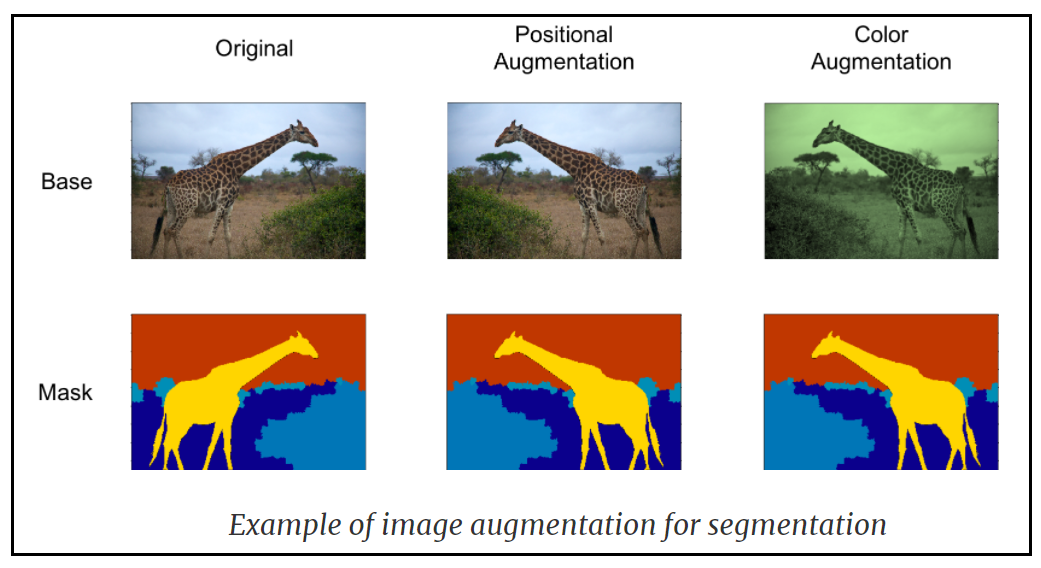
data augmentation은 아래 그림과 같이 제한된 수의 이미지 데이터로부터 기하학적인 대칭 조건들이나 색상변화등을 적용하여 이미지를 뒤집든지 또는 회전시켜 이미지 데이터 수를 늘리는 기법으로 PyTorch를 비롯한 이미지 데이터 준비과정에서 흔히 이루어지는 작업을 뜻한다.
alexnet 의 구체적인 아키텍처 repo 를 살펴보자.

AlexNet에서 사용된 총 파라메터 수 즉 웨이트 수를 조사해보자. Convolution 작업에는 웨이트 값 도입이 필여하지만 MAXPool 작업은 단순한 대수계산이므로 웨이트 값들이 필요하지 아노다. 도합 62,378,344개가 필요하다.

AlexNet의 학습 규모가 커 상당한 컴퓨팅 부담이 있으므로 즉 pretrain=True 조건하에서 사전 학습된 웨이트 값들을 그대로 이용하여 image classificatin을 해보자. pretrain=True 조건으로 불러 쓸 수 있는 사전 학습 웨이트 값들은 아마도 파이선 pickling 기법으로 저장된 binary 코드일 것이다.
구글 Colaboratory에서 PyTorch를 사용하려면 우선 torch와 torchvision을 설치할 필요가 있다. 일반적인 PyTorch 코딩을 위해 torch가 필요하나 굳이 설치하지 않아도 Colab에 이미 설치되어 있는 듯하다. No named module 'torch' 와 같은 에러가 만약 발생한다면 !pip install torch 를 실행해 주면 된다.
아울러, 특히 image classification 작업을 위해서는 다음과 같이 torchvision 설치 작업이 필요하다.
!pip install torchvision
models, torch를 불러들인다. 디렉토리 명령에 따른 출력 결과를 보면 사용할 수 있는 사전학습 모델이 매우 많음을 알 수 있다. AlexNet과 alexnet 이 있는데 대문자 Alexnet은 파이선 class AlexNet이며 소문자 alexnet은 class AlexNet으로부터 instance 값을 리턴해 주는 편의함수를 뜻한다. 마찬가지로 densenet121, densenet161, densenet169, densenet201 모두는 all are instances of DenseNet class의 instance 들이지만 각각 서로 다른 레이어 수 즉 121,161,169 그리고 201를 가짐에 유의하자.

instance alexnet을 불러 출력해 보자.

다음은 ALexNet에서 사용되는 Conv2D의 파라메터 사용법이다. in_channels는 RGB 색상 이미지 227X227X3을 적용할 경우 그 값이 3이 된다. out_channels는 디지털 필터 수를 뜻한다. 초기 AlexNet에서는 필터 수가 96이었지만 여기서는 (2/3)로 축소된 64개가 사용되며 제 2단에서도 역시 (2/3)로 축소됨에 유의하자. 이러한 해상도 축소는 인식률(recognition rate) 저하의 원인 될 수도 있다. 아울러 11X11 커늘 즉 kernel_size=(11,11)이 사용 되고 stride=(4,4)라면 (227-11)/4 + 1로부터 가로 세로 총 55회 스트라이딩이 가능하다. 한편 padding=(2,2)를 감안하면 가로 세로 각각 총 56회 스트라이딩이 가능해진다. padding은 와곽에 0의 값을 추가하여 striding 값을 맞춰주는 작업이므로 결과의 정밀도와는 그다지 상관이 없을 것이다.
a = Conv2d(in_channels, out_channels, kernel_size=(n, n), stride, padding, bias)

분석을 위한 이미지를 다음과 같이 transforms 처리하자. 이 과정은 어느 이미지를 사용하여 classification 작업을 하더라도 공통적으로 요구되는 과정이다. 단지 256X256 으로 할 것인지 아니면 800X800 으로 할 것인지 사용자가 선택할 필요가 있다.

구글 Colaboratory 좌측에 폴더를 클릭하면 화샇표 “↑” 기호가 들어 있는 업로드 아이콘을 볼 수 있다. 이 아이콘을 클릭하여 네 PC의 사용자 폴더 탐색기가 나타나면 미리 저장해 두었던 dog.jpg 그림 파일을 탐색하여 그림 파일을 NDRIVE 상의 sample_data 폴더 바로 밑에 직접 업로드 한 후 읽어서 이미지를 출력하도록 한다.
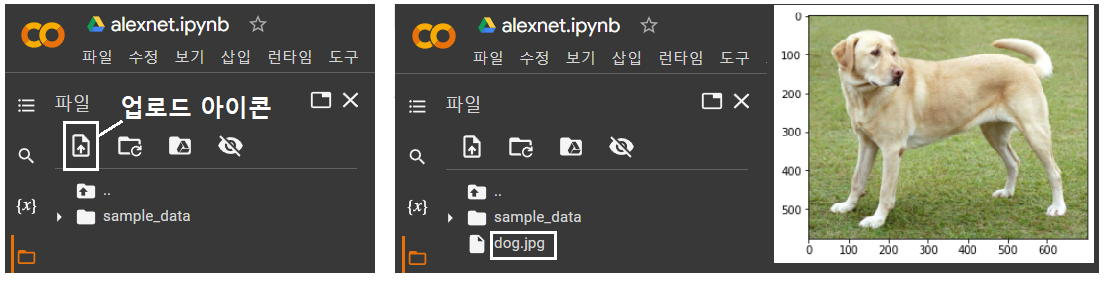
개 이미지를 출력해 보자.

이미지를 resizing , croping 및 normalizing 에 의해 torch 텐서로 변형(transform)하고 shape 값을 출력해보면 [3, 224,224] 임을 알 수 있다. 여기에 unsqueeze 명을 통해 shape 값을 변경하도록 한다.

이 단계에서 transform 된 상태에서 다음과 같이 중간에 몇 개의 명령을 넣어 이미지 상태를 한번 출력해 보자. 좌우상하 여백이 다소 잘려나간 결과를 보여준다. 텐서 상태에서 이미지 출력이 불가하므로 detach( ).numpy( ) 명령 처리를 하면 imshow( ) 명령을 사용할 수 있다. 참고하기 바란다. 요 내용은 첨부파일에 없으므로 사용자가 직접 입력해서 실행해보아야 한다.

model.eval() 명령은 학습단계에서 overfitting 방지를 위해 적용했던 dropout 과 batch normalization 을 중지시킨 후 원래의 네트워크를 대상으로 테스트에 들어 가야 한다는 의미이다. 준비된 데이터 batch_t를 사용하여 alexnet을 실행하여 샘플 이미지 데이터의 label 값을 출력하도록 한다.

계산이 완료된 샘플 이미지 데이터의 label 값을 텍스트로 출력할 수 있도록 alexnet 의 1000가지 라벨 값 사전에 해당하는 json 파일을 다운받아 출력해보자.

softmax에 의해 확률적으로 계산된 샘플이미지의 라벨 값을 앞서 다운로딩한 json 데이터를 사용하여 인식 확률이 높은 순으로 출력해 보자. Labrador _retriever 라는 종의 개가 가장 큰 인식 확률 54.7129를 보여준다.

첨부된 alexnet.ipynb를 다운 받아서 구글 드라이브에서 열어 런타임 유형에서 GPU를 설정하여 실행해 보자. 단 중간에 이미지 파일을 sample_folder 바로 밑에 업로딩 해야 함에 유의하자.
alexnet을 대체하여 예를 들자면 resnet101을 적용해보고 최종 라벨 값 확률을 살펴보자. alexnet.eval() 명령부터 resnet101.eval() 로 변경하여 그 이하에서 관련 명령을 몇 번 손보면 된다. 계산 결과 라벨명은 일치하였으며 확률 값은 다소 낮은 44.1889로 계산되었다.

'Image Classification' 카테고리의 다른 글
| 윈도우즈10 아나콘다 YoLoV3 초간단 설치 (0) | 2022.01.24 |
|---|---|
| 윈도우즈10 아나콘다에 YoLoV3 를 설치하자. (0) | 2022.01.21 |
| 컴퓨팅 부하 경감을 위한 SeparableConv2D (0) | 2022.01.20 |
| PyTorch VGG16 모델 활용 Feature Map 관찰기법 (0) | 2022.01.15 |
| 리메이크:PyTorch ResNet Semantic Segmentation 예제 (0) | 2022.01.08 |