※파이선 코딩 초보자를 위한 텐서플로우∙OpenCV 머신 러닝 2차 개정판 발행
http://blog.daum.net/ejleep1/1175
파이선 코딩 초보자를 위한 텐서플로우∙OpenCV 머신 러닝 2차 개정판 (하이퍼링크) 목차 pdf 파일
본서는 이미 2021년 11월 초부터 POD코너에서 주문 구입이 가능합니다. 참고로 책 목차에 따른 내용별 학습을 위한 코드는 이미 대부분 다음(Daum)블로그에 보관되어 있으며 아래에서 클릭하면 해당
blog.daum.net
본 블로그는 다음 사이트 내용을 참조하여 요약하였습니다.
PyTorch fro biginners: Semantic Segmentation using torchvision
https://learnopencv.com/pytorch-for-beginners-semantic-segmentation-using-torchvision/
1. PyTorch ResNet Semantic Segmentation
2012년 스탠포드 대학에서 주최되었던 ILSVRC 컨퍼런스에서 발표되었던 AlexNet 이후로 2016년 최고로 높은 인식률을 보여주었던 ResNet 모델이 Transfer Learning 분야에서 이미 많이 활용되었다. ResNet은 채용된 레이어 수 크기에 따라 ResNet50, ResNet101, ResNet152의 3종류가 있는데 비록 학습된 결과라고 해도 그 크기가 제법 큰 편이며 중간에 해당하는 ResNet50과 ResNet101이 Semantic Segmentation 예제에서 Transfer Learning 이 가능하게끔 불러 쓸 수 있도록 사용되고 있다. Transfer Learning 이라 함은 imagenet 을 대상으로 이미 상당한 컴퓨팅을 통해 학습된 성과물 즉 웨이트 데이터를 가지고 사용자가 특정 이미지 클래스에 해당하는 추가 이미지 데이터를 합하여 짧은 시간의 컴퓨팅을 통해 약간 수정된 웨이트 데이터를 얻어 test나 forcast에 사용함을 참조하자. 머신러닝을 연구하는 분이라면 반드시 알아야 하는 기법이다.
Semantic Segmentation은 이미지를 분석함에 있어서 한 이미지에 포함되어 있는 각각의 오브젝트 이미지 성분들을 인식할 수 있어야 한다. 예를 들면 하나의 이미지를 구성하는 오브젝트들로서 사람, 포장도로, 차량, 가로수, 빌딩, 구름 및 하늘이 있다면 개개의 오브젝트를 나타내는 픽셀들의 라벨 값을 정확히 인식해 내야 한다.

여러 요소가 포함된 이미지를 대상으로 하는 CNN 과정에서 Fully Connected Layer 전 단계 즉 특장 추출 (Feature Extraction) 단계까지만 적용하게 되면 원래의 이미지로부터 최소화된 크기의 간신히 이미지를 식별할 수 있을 정도의 작은 특징벡터가 얻어진다. 일반 CNN에서는 ImageNet에서 설정되어 있는 1000개의 클라스에 맞출 수 있도록 Fully Connected Layer를 사용하여 최종 확률이 계산되어 인식 결과가 얻어진다고 보면 된다. 하지만 Semantic Segmentation 에서는 원 이미지의 중요한 정보를 보존하는 최소화 된 크기의 특징 벡터에서 출발하여 다시 원래 이미지 사이즈 크기까지의 출력을 얻어낼 수 있도록 CNN 과정을 역으로 디코딩(decoding) 학습하게 된다. 이와 같이 이미지 크기를 최소한으로 줄였다가 다시 원래 크기로 되돌리는 과정을 Autoencoder 기법이라고도 함을 참조하자.
물론 엔코딩 디코딩 과정에서의 학습을 위한 클라스의 수는 아무리 컴퓨팅 능력이 개선되었다고는 하지만 단지 이미지 하나를 대상으로 1000 종류 모두를 대상으로 학습하기는 어려우므로 ImageNet의 1000 종류 모두가 아니고 필요에 따라 2019년에는 21 종류 정도에 한하고 있으나 지금 2022년 초인 지금은 훨씬 늘어났을지도 모르겠다.
한편 연산과정에서 픽셀 단위로 주어진 제한된 클라스 종류 수에 해당하는 라벨 값들을 인식해야 하므로 계산량이 어마어마하게 커짐으로 인해 반드시 GPU 연산이 필요하게 된다. 따라서 사용자 컴퓨터에 고성능 GPU 가 없다면 이래에 기술되는 예제처럼 반드시 구글 Colabo에서 GPU를 사용하여 처리하도록 할 것이다. 참고로 구글 GPU 는 크롬 사용자라면 꽁짜로 제공됨에도 유의하자.
PyTorch에서의 Transfer Learning 예제에 따르면 Fine Tuning 과 Fixed Feature Extraction 두 종류 학습방법이 있다. Semantic Segmentation에서는 더 이상 추가로 학습을 하지 않는 상태의 Fixed Feature Extraction을 사용하는 듯하다. Fixed Feature Extraction 기법을 사용한다 함은 AlexNet 이나 ResNet과 같이 상당히 많은 시간이 소요되는 네트워크 학습 결과를 Transfer Learning 해온 상태에서 더 이상의 추가 학습을 시키지 않으면서 직접 Semantic Segmentation 작업을 실행한다는 의미이다.
ResNet101 학습결과를 사용하는 Segmentation 코드를 구글 Colabo에서 GPU를 사용하면서 실행해 보자. ResNet52 도 이미 PyTorch Transfer Learning 예제에서 사용한 적이 있으나 TorchVision을 라이브러리로 사용하는 Segmentation 작업에서는 101 만이 준비되어 있는 듯하다.
크롬 NDRIVE에서 내드라이브->더 보기-> Colaboratory 하여 Untitled0.ipynb 를 생성 후 semantic_example.ipynb 로 파일명을 부여하자.

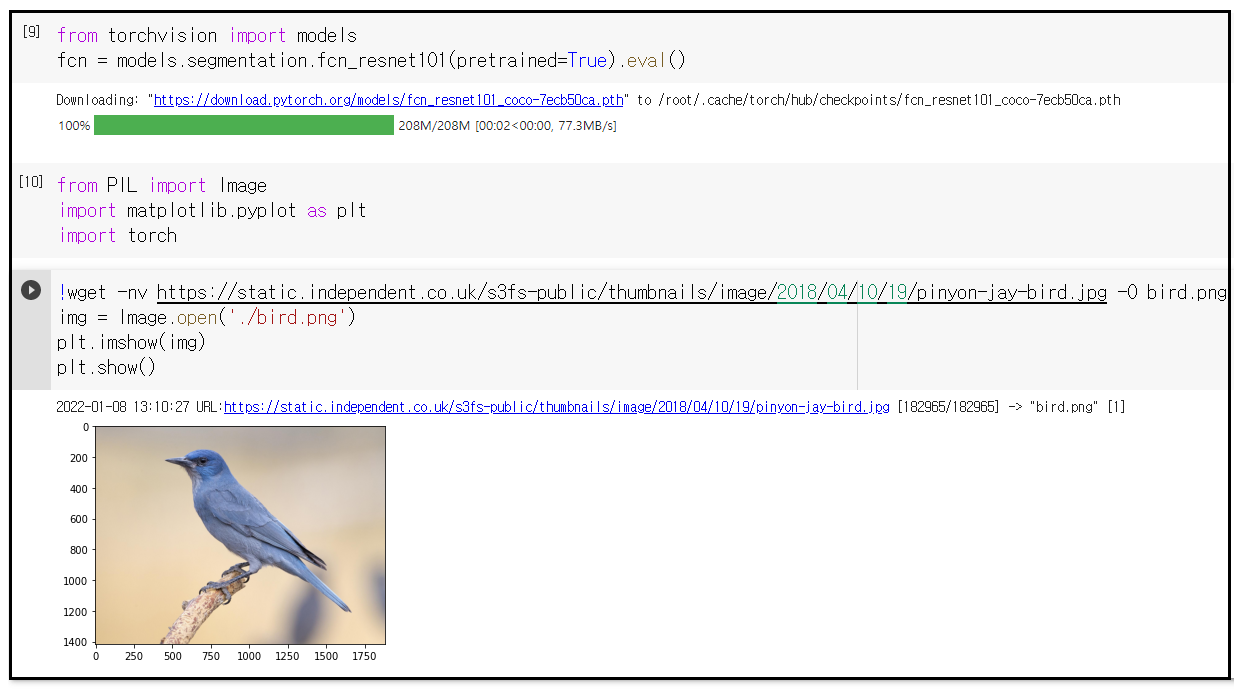
이 예제 코드를 실행하기 위해서는 우선 나무에 않아 있는 새의 이미지 파일을 구글 Colabo에 업로딩 하자. 다음은 구글 Colaboratory 사용자 폴더에 저장되어 있는 bird.png 파일을 업로딩하는 과정이다. 구글 Colaboratory 도 해를 거듭할 수록 조금씩 사용법에 변화가 있는 듯하다.
처음에 파일을 담고 있는 폴더를 차자아서 클릳하면 sample_data 폴더를 볼 수 있으며 그 왼쪽 위에 업로딩 아이콘을 찾을 수 있을 것이다. 업로딩 아이콘을 클릭하여 파일탐색기가 나타나면 정해 두었던 bir.png 파일을 선택하면 sample_data 폴더 바로 밑에 저장됨을 확인할 수 있다.

이어서 첫 번째 셀이서 command line 명령들을 실행하도록 한다. 다음 두 줄을 복사하여 실행하자. 결과를 보니 2년 전과 메세지가 조금 다른 듯하다. fcn 이란 변수명은 fully convolutional network 에서 유래되었다. pretrained=True 조건은 이미 학습된 결과를 사용하겠다는 의미이다. 즉 segmentation. fcn_resnet101(pretrained=True)는 resnet101 학습 결과를 활용하여 segmentation 이미지 처리를 한다는 뜻이며,
from torchvision import models
fcn = models.segmentation.fcn_resnet101(pretrained=True).eval()

헤더 영역에서 라이브러리들을 추가로 설치하자. 준비된 새 이미지(bird.png) 를 불러 온다.(이 명령 형식은 http url 주소에 co.uk 가 있는 것으로 보아 원 저자의 서버에서 불러 오는 형식일 것임) 하지만 !wget... 이 없으면 sample 폴더 밑에 사용자가 직접 준비한 bird.png 를 불러 올 수 있게 된다.
from PIL import Image
import matplotlib.pyplot as plt
import torch
!wget -nv https://static.independent.co.uk/s3fs-public/thumbnails/image/2018/04/10/19/pinyon-jay-bird.jpg -O bird.png
{kind=link}
img = Image.open(‘./bird.png’)
plt.imshow(img)
plt.show()
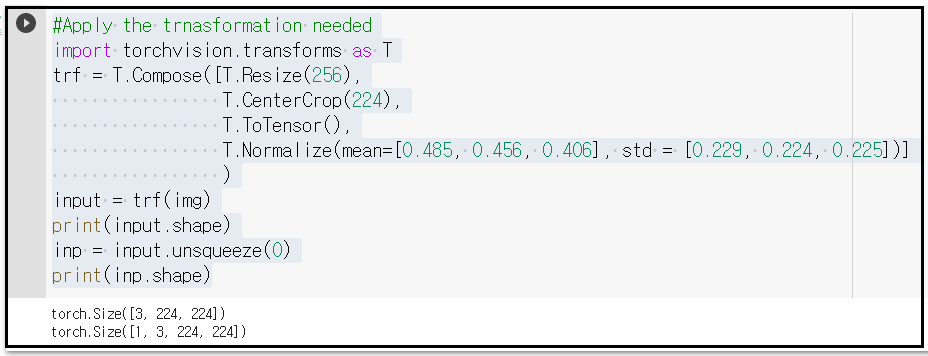
오픈한 이미지 파일을 PyTorch 가 처리할 수 있도록 변형(transform) 시키도록 하자. Resize, CenterCrop 명령이 사용된다. 처리된 이미지는 Tensor 즉 TorchTensor 로 처리한다. 아울러 ImageNet에서 주어지는 평균값과 표준 편차를 사용하여 표준화 하도록 한다.
이와같이 처리한 결과물 input의 shape 값을 살펴보면 TorchTensor로서 [3, 224, 224] 임을 알 수 있다. 3은 RGB 컬러의 3을 뜻하면 224는 PyTorch 이미지 처리 시 표준적인 크기 이다.
input을 unsqueeze(0)시키면 shape 의 차원이 하나 늘어나는데 이 차원은 batch size로 할당 된다. 현재는 하나의 이미지를 처리하므로 batch size = 1 인 셈이다.
#Apply the trnasformation needed
import torchvision.transforms as T

괄호 안의 output.squeeze().dim=0 처리 후 oi=torch.argmax 명령을 실행하게 되면 [224,224] TorchTensor가 얻어진다. om=oi.detatch().numpy() 명령 처리를 하면 shape이 (224,224) 어레이 형태가 된다.

마지막으로 바로 위 결과에서 om이 가지고 있는 unique 한 정보를 출력해 보면 [0 3]임을 알 수 있다. 아래의 decode _ segmap 루틴에 의하면 0은 배경을 뜻하며 3은 새를 의미한다. 즉 즉 21개 Class를 대상으로 한 Segmentation 확률이 결정되어 얻어졌다는 뜻이다. 이와 같은 처리를 통해 각 픽셀이 하나의 클라스에 해당하는 2차원 이미지를 얻게된다. 이 2차원 이미지를 가지고 마지막으로 해야 할 작업은 각 클라스의 라벨값에 따라 해당하는 RGB 색상으로 변환시켜 시각화 된 segmentation map 으로 바꾸는 일이다. 다음과 같이 segmentation map 을 얻을 수 있도록 디코딩 루틴을 실행하자.
#내부의 오브젝트들을 살펴보면 0번 배경부터 20번 tv/monitor까지임을 알 수 있다.

최종 RGB 디코딩 처리된 이미지를 출력하자. 색상뿐만 아니라 디코딩되어 원래 형상 크기 기준으로 Resizing 된 이미지가 출력된다

앞의 예제에 연속하여 말 이미지 예제를 추가해 보자. 앞선 셀 명령들을 모아서 다음과 같이 함수화 하자.


2. PyTorch Semantic Segmentation using DeepLab
DeepLab은 구글뇌(Google Brain)에서 나온 세만틱 세그멘테이션 아키텍쳐이다. 그 사용 방법이 fcn 과 유사하므로 간단히 알아 보기로 하자. 거의 동일한 결과가 얻어진다.
dlab = models.segmentation.deeplabv3_resnet101(pretrained=1).eval()
segment(fcn, './horse.png')

아래에 첨부된 semantic_example.ipynb 파일을 다운받아 구글 드라이브에 옮겨 넣고 연 후 각 셀들을 실행시키면서 본문 내용을 읽어 보도록 하자.
Under construction ...
'Image Classification' 카테고리의 다른 글
| 윈도우즈10 아나콘다 YoLoV3 초간단 설치 (0) | 2022.01.24 |
|---|---|
| 윈도우즈10 아나콘다에 YoLoV3 를 설치하자. (0) | 2022.01.21 |
| 컴퓨팅 부하 경감을 위한 SeparableConv2D (0) | 2022.01.20 |
| PyTorch VGG16 모델 활용 Feature Map 관찰기법 (0) | 2022.01.15 |
| Google Colab에 의한 PyTorch AlexNet Image Classification (0) | 2022.01.08 |