9-6 YOLO(You Once Look Only) Lane Detection
http://ejleep1.tistory.com/1395
한편 컴퓨팅 속도 차원에서 타 알고리듬과는 비교할 수 없을 정도로 빠른 YOLO 알고리듬에 대해서 살펴 보기로 한다. 처음부터 속도를 중시했기 때문에 어쩌면 상업적인 자율주행을 목표로 개발이 이루어져 왔을 수도 있다.
YOLOv3 를 사용하여 여러 종류의 짐승들을 포함하고 있는 이미지를 object detection 해보자. 탐지(Detection) 결과를 요약해 보면 말 3마리, 개 5마리는 정확하게 Bounding Box로 검출이 되었고 작은 크기의 고양이들은 놓친 결과를 보여준다. 물론 YOLOv3 가 나름 괜찮은 object detector 이긴 하지만 object들의 크기에 따라 missing 하는 object들이 있음을 알 수 있다.
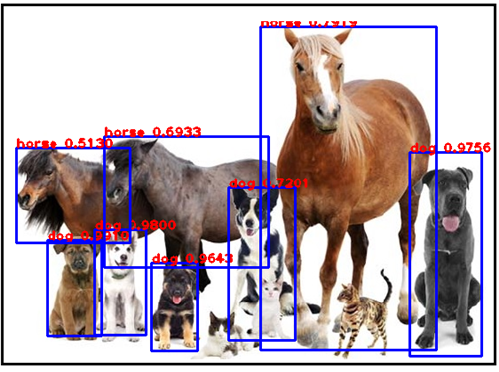
물론 YOLO 보다 우수한 Fast RCNN, Faster RCNN 과 같은 알고리듬들이 개발되었으나 여전히 컴퓨팅 부담이 상당히 커 자율주행 차량 컴퓨터에서 사용하기는 부담이 있을 수 있으므로 자율주행 연구 차원에서 YOLOv3를 설치한 후 도로교통 비데오를 사용하여 객체를 탐지해 보자. 더 나아가 OpenCV 비젼 코드를 추가하여 차선 식별 작업을 살펴보기로 한다.
9-7 YOLOv3 설치
참조: 윈도우즈10 아나콘다에 YoLoV3를 설치하자
http://ejleep1.tistory.com/1210
2022년 최신 아나콘다에 YoLo 버전 3.0 을 설치해보자. 윈도우즈10 – 아나콘다 시스템에서 여타의 라이브러리처럼 YoLo는 가상환경의 Open Terminal 에서 "pip install yolov3" 와 같은 간단한 command line 방식으로 설치가 되지 않기에 다소 까다롭다고 볼 수 있다.
YoLoV3 는 다음과 같이 80종의 객체로 구성된 마이크로소프트의 COCO dataset 을 사용하여 학습된 모델이다.

수년 동안 image classification 코드를 다루면서 자주 등장하는 YoLo(You Look Only Once)가 자주 시선을 끌었던 것이 사실이지만 사실 그 설치 방법이 쉽지 않아 매번 설치하는 족족 실패했던 것이 사실이다. 하지만 image classification 머신러닝의 발전 흐름을 살펴보면 주방향이 FCN 이라든지 R-CNN이라든지 Semantic Segmentation 으로 흐르고 있기때문에 실행속도는 빠르긴 하지만 그 주된 흐름을 YoLo가 쫓아가지 못하는 것으로 보이지만 그래도 R-CNN 알고리듬을 배우기에는 필수적으로 적합한 코드라는 생각이 들기도 한다.
우선 머신러닝 코드 개발을 위한 tensorflow 가상환경을 하나 만들도록 하자. 그 방법은 Anaconda Navigator 의 Environments를 클릭하여 열고 들어간 후에 하단의 Create 버튼을 눌러 팝업창이 뜨면 가상환경명 즉 예를 들자면 "tensorflow"를 입력하고 python 버전을 선택하면 된다. 아울러 가상환경 명칭 버튼 끝부분의 세모 버튼을 눌러 나타나는 메뉴에서 Open Terminal 을 선택 오픈 후에 tensorflow 를 설치하도록 하자. 현재 tensorflow 버전은 2.7 이다.
pip install tensorflow
그 다음은 python과 연동하여 OpenCV를 설치한다. tensorflow 와 OpencV는 YoLo 버전3을 실행시키는데 깊은 연관이 있다.
pip install opencv-python
추가로 머신러닝 코드 작성에 필수적인 라이브러리 7가지를 한방에 설치하자. 물론 이들이 다 YoLo 버전3을 실행시키는데 필요한 것은 아니다. tensorflow 와는 달리 설치 시간이 그다지 걸리지 않는다.
pip install numpy matplotlib pandas scipy scikit-learn cython keras
numpy 는 수치계산, matplotlib 는 그래프 작성, pandas 는 csv 데이터 입출력, scipy 는 과학기술, scikit-learn 은 머신러닝, cython 은 C 와 python연계, keras는 tensorflow 를 지원한다.
마지막으로 웹캠이나 비데오 파일 처리를 위해서 OpenCV를 설치하자.
pip install python_opencv
이로서 tensorflow 버전(2.9) YoLov3 를 설치하기 위한 준비가 되었다. 사실 이런한 준비는 굳이 YoLov3 를 설치하지 않더라도 머신러닝 코드 작성을 위한 가상환경 설정의 일환으로 빈번히 해야 하는 익숙한 작업일 것이다.
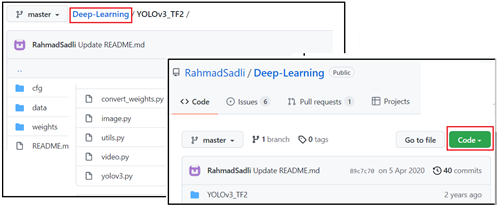
다음의 Github Repo url 주소에서 YoLo의 압축 zip 파일을 다운로드 받자.https://github.com/RahmadSadli/Deep-Learning/tree/master/YOLOv3_TF2
다운받은 Github 내용은 cfg, data, weights 폴더와 convert_weights.py, image.py, utils.py, video.py, yolov3.py 의 5개 핵심 파일을 포함한다.
① cfg 즉 configuration 에서는 학습(train) 및 테스트에서 필요한 파라메터 값들 설정이 이루어진다.
⓶ convert-weight 에서는 cfg 파일과 weight 값을 로딩하고 모델을 설정 후 YoLov3.py 에 포함되어 있는 YOLOv3NET 클라스 명령을 부른다.
⓷ utils.py 는 image.py 또는 video.py에 필요한 여러 함수들을 불러낸다. 즉 이미지 분석 시행을 위해서 image.py 나 video.py 를 실행하면 알아서 필요한 루틴들을 불러다 쓴다.
Github 에서 다운받기 위해서는 아래 그림에서처럼 Deep-Learning 버튼을 클릭하여 나타나는 팝업창에서 Code 버튼을 클릭하도록 하자. 다운받은 후 유의해야 할 점이 있는데 압축해제 후 폴더에 weights 폴더와 5개 핵심 파일이 없다는 점이다. weights 폴더는 YoLov3 의 사전학습(pretrained) 내용을 포함하며 YoLov3에서도 메모리 비중이 큰 부분으로서 별도록 다운받아 체우면 된다. 이 부분은 사용자가 직접 처리해야 하는 부분이다. 다운 받을 주소는 사용자가 임의로 정하되 경로만 정확히 알고 있으면 된다. 필자는 그냥 지워버릴 계획으로 다운로드 폴더에서 그대로 압축 해제하여 그 위치에서 작업을 해도 무방하다.
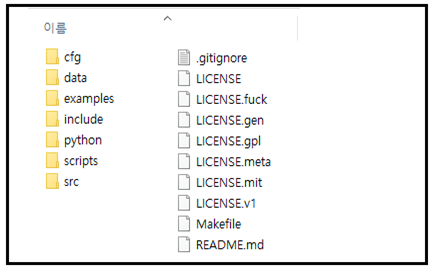
다운 받은 후 압축해제 하여 darknet-master->darknet-master에서 보면 아래와 같이 weights 폴더와 5개 핵심 파일이 없음을 알 수 있다. 아래에 step에 따라 순차적 처리 과정만 설명하기로 한다.
step 1. 3개의 파일을 다운 받아서 cfg폴더, data폴더, weights 폴더에 넣도록 되어 있는데 다운 받은 내용을 체크해 보면 yolov3.cfg와 coco.names 는 이미 들어 있다는 점에 유의하자. 단지 yolov3.weights 만 빠져 있으므로 이 파일만 별도로 다운 받은 후 별도로 폴더를 만들어 저장하면 된다.
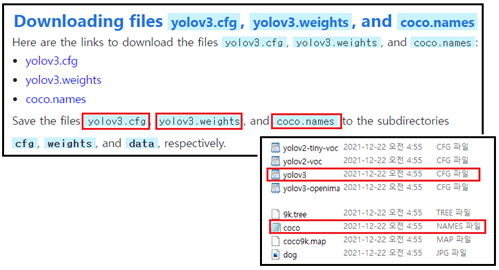
yolov3.weights 를 다운로드하기 위해서 아래 url 주소의 영문 블로그 ( The beginner’s fuide to implementing YoLov3 in TensorFlow 2.0:part-2 https://machinelearningspace.com/yolov3-tensorflow-2-part-2/)를 오픈하고 다음 부분을 찾아서 yolov3.weights 를 클릭하자. 다운로드 시간이 10분 이상 꽤 걸림에 유의하자. 한번 클릭하였음에도 동일한 파일이 동시에 2개가 다운되는데 폴더에서 크기를 확인해 보아 동일하면 하나만 취하면 된다.
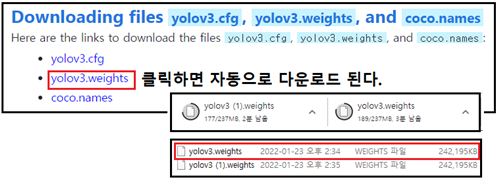
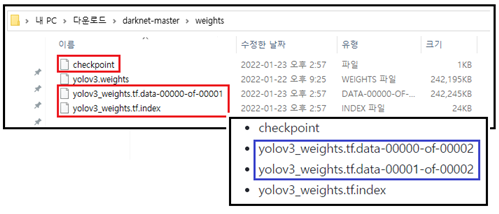
step 2. cfg, dat 폴더가 들어 있는 darknet-master 폴내 안에 weights 명의 폴더를 새로 만들어 앞서 다운 받은 yolov3.weights 를 압축 해제한 내용물들을 넣도록 한다. 폴더에 다음과 같은 내용물이 들어 있을 것이다.
yolov3.py 를 준비하도록 하자. 영문 블로그 part-2 의 내용을 스크롤 해 내려가 보면 거의 끝부분에 제법 긴 전체 코드(complete code)가 나타나니 이 부분을 전체 copy 하자.

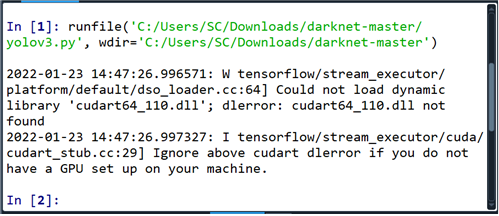
한편 아나콘다 가상환경인 tensorflow 에서 편집기 spyder 를 열어 신규파일(New File) 을 열어 yolov3.py를 생성한 후 copy한 내용을 paste 하고 저장 후 실행하자. 아무런 에러 없이 다음과 같은 메세지가 뜨면 성공이다. 이로서 yolov3.py 설치가 성공적으로 끝났으며 darknet-master 폴더에서 확인이 가능할 것이다.
step 4. 아래 url 주소의 영문 블로그
( The beginner’s fuide to implementing YoLov3 in TensorFlow 2.0: part-3 https://machinelearningspace.com/yolov3-tensorflow-2-part-3/ )를 오픈하고 다음 부분을 찾아서 convert_weights.py를 설치하도록 하자.
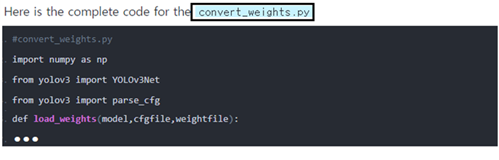
요령은 step 3 처럼 블로그 후반의 전체 코드를 copy 하여 역시 아나콘다 tensorflow 가상환경에서 신규파일을 열어 convert_weights.py 로 명명 후 paste 하고 저장 후 실행시키도록 하자. 다음 결과를 관찰할 수 있을 것이다.
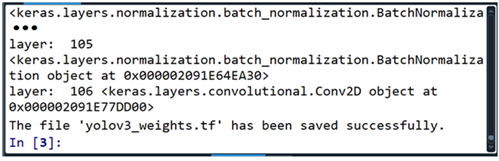
darknet-master -> weights 폴더에 다음과 같이 추가된 내용물이 들어 있을 것이다. 이 파일들 앞의 prefix에 tf.이 들어 있는 것으로 보아 weights 들이 tensorflow 양식으로 변환된 듯하다. 하지만 원 저자의 블로그 결과(푸른색 박스)와 다소 차이가 있음을 지적해 둔다.
step 6. 영문 블로그 part 4
(https://machinelearningspace.com/yolov3-tensorflow-2-part-4/) 로 넘어가서 나머지 핵심 파일들을 아나콘다 가상환경 tensorflow에서 copy & paste 하여 준비하도록 하자. 그 요령은 step 5 에서와 거의 동일하다.
utils.py 는 R-CNN 에서 나오는 non maximum suppression 알고리듬 구현에 필요한 알고리듬을 담고 있다. 굳이 실행하지 않아도 다음 스텝의 image.py 또는 video.py를 실행하면 자동으로 실행됨에 유의하자.
step 7. image.py는 data 폴더에서 그림 파일을 읽어 들여 YoLov3를 실행하는 코드이다. 따라서 part-4 의 차량으로 빼빽히 들어찬 이미지를 다운로드하여 data 폴더에 "test.jpg"로 저장하도록 하자.

PC화면에서 우측 상단의 크롬 맞춤 및 설정제어 탭 버튼을 눌러 메뉴가 나타나면 다운로드를 클릭하자.

다시 추가설정 버튼을 누르면"다운로드 폴더 열기" 버튼을 볼 수 있다. 클릭 후 data 폴더를 찾아서" test.jpg" 로 저장하자.
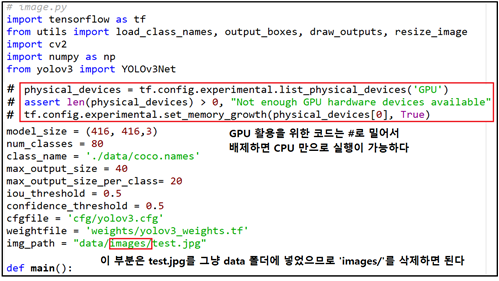
image.py 를 copy & paste 하여 실행시키면 다음과 같이 GPU 에러 메세지가 발생한다. 가상환경 tensorflow 설치 시에 GPU 가 필요 없는 tensorflow를 설치하였음을 기억하자. 물론 필자의 PC 에도 GPU 가 없어 필요 시 구글 Colab 을 사용하는 실정이다. 이 단계에서 에러를 처리할 수 읶는 방안을 강구 하자. 따라서 이 GPU 부분에 해당하는 코드를 삭제하거나 #로 밀어 버리도록 하자.
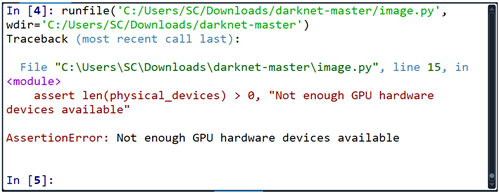
image.py 에서 다음과 같이 간단히 수정하여 저장하도록 하자.
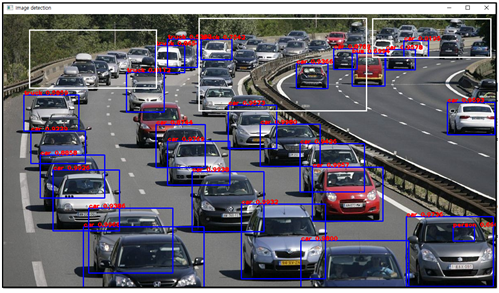
이미지에 포함된 엄청난 차량의 수에 비례하여 제법 많은 양의 컨볼루션 처리가 잠시 이루어짐을 확인할 수 있다.

YoLov3의 처리 결과를 보면 가까운 부분은 거의 완벽하게 푸른색 박스로 object detection을 수행했으나 필자가 흰 박스 친 먼 거리의 차량들 일부는 object detection 에 실패했음을 알 수 있다. 가까워지면 detection 이 될 것이다. 이 정도면 대단히 만족스러운 수준이다.
step 8. video.py는 OpenCV에서 보통 분당 30 fps(frames/초) 로 이미지를 카메라를 사용하여 처리할 때 YoLov3 가 처리하는 루틴이다. 일반 사용자 PC에 웹캠이 설치되어 있고 가상환경에 OpenCV 가 설치되어 있다. 아울러 GPU 부분 코드 3 줄을 #로 밀어버린 상태라면 실행에 아무런 문제가 없을 것이다.
'자율주행' 카테고리의 다른 글
| 11 알고리듬 특허 (0) | 2022.10.21 |
|---|---|
| 9장 자율주행을 위한 이미지 머신러닝 III (0) | 2022.10.21 |
| Image Classification & Object Detection (0) | 2022.10.21 |
| 7장 Mathworks 자율주행 MATLAB 코딩 (IV)고속도로 차선변경 (0) | 2022.10.21 |
| 7-4 HD 라이브 맵 레이어 구성 (0) | 2022.10.13 |