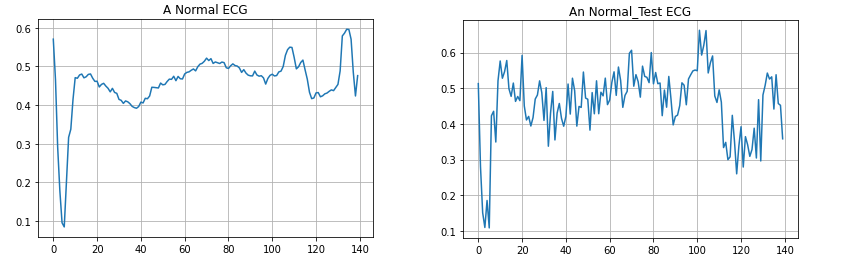
autoencoder 알고리듬은 학습 데이터에 포함되어 있는 노이즈 제거 특성임을 잘 알고 있다. autoencoding 알고리듬 활용을 위해서는 주어진 데이터를 학습용과 validation 용으로 split 한 다음 학습을 실시하여 autoencoder 를 생성하자. 학습된 autoencoder를 validation 데이터에 적용하면 일반적으로 90% 이상의 정확도 즉 Accuracy를 확인할 수 있다. 아울러 10%남짓 오차를 보여주는 validation 데이터에서 autoencoder로 학습된 validation 데이터와의 차이 즉 mae(mean absolute error) 분포를 조사해 볼 필요가 있다. 특히 학습과정에서 충분한 에포크(epoch) 수를 취하면 보다 정확도를 올려줄수 있는 aut..