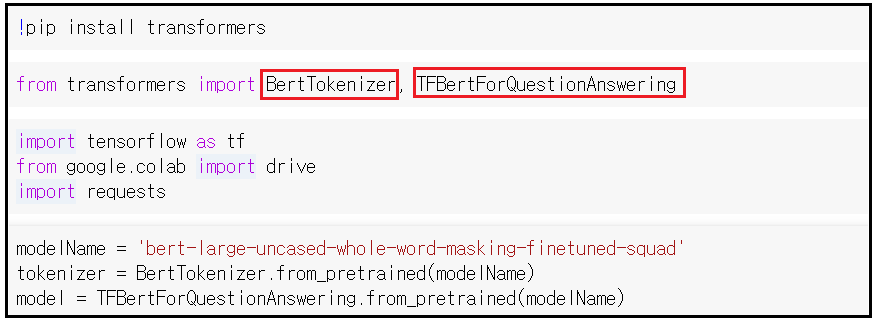
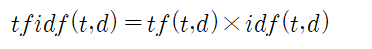영화리뷰 데이타 세트가 준비되었으면 준비된 텍스트의 집합체를 어떻게 개별 단위의 토큰으로 쪼갤 것인지 하는 문제를 생각해 보자. 문서를 토큰화 하는 방법은 앞장에서 처리했던 클리닝한 문서 데이타(cleaned documents)를 대상으로 여백을 중심으로 단어를 쪼개는 것이다. 그러한 목적을 달성하기 위한 함수도 작성해야 하지만 아울러 아나콘다 TensorFlow 가상환경에 PyPrind에서 처럼 귀찮지만 라이브러리를 설치해야 한다는 점이다. 이미 경험이 있으면 아래 내용을 일독 후 10분 이내에 처리할 정도의 코딩 실력을 갖추도록 하자. 토큰화 관점에서 또 다른 유용한 기법으로서 word stemming 알고리듬이 있는데 이는 단어의 변환 과정애서 어근(root)을 찾아 내는 것이다. 원조 어근 알고리..