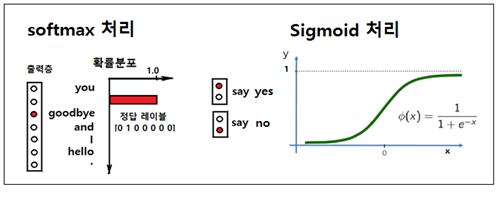
은닉층과 크기가 (100, 1000000)인 Wout과의 매트릭스 곱셈 연산을 통해 softmax 처리가 가능하도록 하기 위해서는 엄청난 규모의 컴퓨팅이 요구된다. 따라서 그런 과중한 연산을 줄일 수 있도록 학습 과정에서 softmax를 사용하는 다중분류에서 Sigmoid 우도(likelyhood) 함수를 사용하는 이진 분류방식으로 처리하도록 알고리듬을 수정하자. 즉 입력이 {you, goodbye}이면 학습은 {say}인가? 아닌가? 로 처리하도록 한다. 즉 긍정적 정답 레이블인 {say} 하나가 있을 수 있지만 동시에 {say}가 아닌 부정적인 정답 레이블들에 대해서도 다할 수는 없지만 일정 수만큼 학습 처리해야 한다. 예를 들자면 {hello}, {.}, {and}, {I}들로서 이들은 라벨 값 ”..