시작하기 전에 일단 결과 영상을 감상 후 코드 작업을 진행하자.
2022년 9월 중순 어느새 자율주행차량 시법운행이 폭발적으로 늘어나고 있다. 이미 샌프란시스코에는 GM 차에 구글 waymo 시스템 자율차량을 비롯하여 로보택시 시범운영이 이루어지고 있다. 물론 중간에 퍼져버린다든지 사고도 많지만 아무튼 자율주행의 시대가 도래했음은 분명한 것 같다.
제네시스 G90 에 장착된 ADAS 시스템도 보다 발전하여 레벨 3 내지는 레벨 4를 넘보는 듯하다.
참조: 라이다 달린 신형 G90 나온다!
https://www.youtube.com/watch?v=N5a3h1RJxsc&t=183s
2021년 5월에 김한용 MOCAR의 자동차 블로그에서도 인텔이 17조원에 인수했다고 하는 이스라엘의 모빌아이사의 상용화 제품인 40 만원선의 ADAS 시스템을 부착하여 성능 입증을 위한 영상도 소개 되고 있다.
참조: 회사차에 모빌아이 6K를 장착 ...
https://www.youtube.com/watch?v=WI-YYhKgOq4&t=689s
테슬라든 현대차든 모빌아이든 당신이 코드를 만지는 프로그래머라면 자율주행의 레벨 2에서 레벨 5까지 감에 있어 반드시 거쳐야 하는 코딩 단계는 어다쯤일까? 한번 진다해 볼 필요가 있다.
현재의 블로그에서도 단편적일 수 밖에 없는 수많은 코드 작업들이 소개되었으나 한번쯤 캡스톤 코딩 디자인이라고 할만한 파이선 코딩을 시도해봐야 할 시점이 아닌가한다.
그래서 그 주제를 ADAS 기능 구현을 목표로 하였다. 물론 편의 상의 이유겠지만 상당수의 오픈소스들이 리눅스나 우분투 기준으로 소개되고 있으나 일단 여기서는 윈도우즈10 의 아나콘다 스파이더에서 주행 동영상을 사용하여 코드 작업을 진행하기로 한다. 적어도 레벨 2를 넘어가려면 카메라 캠에 잡히는 영상에 포함된 객체들이 자율주행의 안전을 보장하기 위해서는 100% 완벽하게 인지가 되어야 한다. 자율주행 차량의 주행속도는 60 km/h 이하면 충분할 것이다.
그정도로 완벽한 객체 인지를 위해서 오픈소스 YoLoV3 를 사용하도록 하자. YoLoV3 는 마이크로 소프트의 COCO Dataset 을 사용하여 80종의 객체들에 대해 학습되었다. 도로상에서 목격할 수있는 웬만한 아이템들은 다 포함되어 있다.
하지만 자율주행을 위해서는 가이드레일 이라든지 더 많은 객체들이 포함되어 학습되어야 할 것이다.
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis','snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
캠스톤 코딩 디자인에서 YoLoV3 를 택하는 이유는 무엇인가? 생각해 볼 필요가 있다. 본 블로그에서도 YoLoV3 설치하기위한 내용들이 있다.
참조: 윈도우즈 10 아나콘다에 YoLoV3를 설치하자.
https://blog.daum.net/ejleep1/1210
참조: 윈도우즈 10 아나콘다 YoLoV3 초간단 설치
https://blog.daum.net/ejleep1/1211
YoLoV3 는 파이선 오픈소스로서 코드가 공개되어 있다. 따라서 필요에 따라 커스터마이징 목적으로 코드 수정이 가능하다. YoLoV3 알고리듬 수정은 난이도가 지극히 높지만 자율주행을 목표로 비젼 코드를 작성하여 삽입하는 정도는 그다지 어려울 것이 없어 보인다.
인터넷에서 조사해본 바에 의하면 몇 종류의 Jupyter 코드들이 있으며 단편적으로는 Canny 필터링이라든지 Hough 변환을 경험해 볼 수 있다. 하나의 이미지를 대상으로 할 수도 있으며 또는 동영상을 대상으로 Canny 와 Hough 변환 기법을 적용할 수는 있었으나 실시간 영상 시청을 위해서는 아직은 개선의 여지가 많은 코드들이라 판단된다.
동영상 처리에 관한 문제점들이 마음에 들지 않아 추가로 검색 작업을 하여 찾은 사이트가 바로 아래이다.
참조: Hough Transform with OpenCV
https://learnopencv.com/hough-transform-with-opencv-c-python/
다음 Github url 주소에서 코드를 다운받아 실행해 보자.
https://github.com/spmallick/learnopencv/tree/master/Hough-Transform
블로그 내용을 읽어 보았을 때 파이선 코드에 과연 제대로 실행이 될까하는 의구심이 들 정도로 좀 허술한 면이 있어 이메일로 원본 코드를 받아서 실행해 본 결과 아주 클린한 느낌을 받았다. 아래 블로그 내용을 참조하자.
참조: OpenCV Hough Tramsform 에 의한 차선 작도
https://blog.daum.net/ejleep1/1381
앞서 지적했던 문제들이 해결 되었으며 이번 캡스톤 코딩 디자인 프로젝트에 적용해 본 결과 성공적이었다.
이미 코딩아트의 블로그를 보고 YoLoV3 를 다운받아 성공적으로 설치했다고 가정하고 해설을 진행 하자.
아나콘다 가상환경에서 YoLoV3 의 video.py 를 열어서 편집하도록 하자.
video.py 가 저장되어 있는 폴더 내에 utils 도 함께 들어 있다는 점에 유의하자.
video.py 실행 시에 utils 가 실행되므로 load_class_names,... resize_image 까지의 함수들이 실행되어 사용이 가능해진다. 아울러 Hough Transform 작업을 하기 위한 파라메터 지정에서 라디안 계산을 위해 π값을 불러 써야 하므로 ㅑㅡㅔimport numpy as np 라이브러리 설정이 한 줄 추가 되어야 한다.

이어지는 아래의 # 처리된 내용들은 사용자 PC에 GPU가 없기때문에 배제하였다.

만약 GPU 사용을 원한다면 YoLoV4 Colab 용 리눅스 버전을 사용해야 한다. 이 버전은 오픈 소스가 아니므로 Vision 코드 추가가 곤란한 면이 있다.
아래 내용은 YoLoV3 를 규정하는 초기 설정 값들이다. 비젼코드 추가 작업과는 아무런 상관이 없으므로그대로 두자.

위 내용에 이어 Canny 필터링과 Hough 변환에 필요한 파라메터 값들을 설정하자. 처음에는 그대로 사용하고 차후 사용자가 준비한 영상에 대해서 문제가 있으면 조금 변경해 보는 것도 좋을 것이다.

함수 main()에서 비젼 처리를 위해 불러 사용해야할 함수 region of interest 이다. 반드시 보여 주어야 할 영역을 꼭지점들로 이루어진 vertices 데이터를 사용하여 영역을 정해 주고 cv2.fillPoly 로 경계선을 그은 다음 외부 영역은 검은색으로 덮어 보이지 않게 한다.

아래에서 함수 main() 의 내용을 살펴보자. YOLOv3 함수를 호출하여 모델을 준비하고 이어서 웨이트 값과 COCO Dataset 을 학습한 클라스 명, 그리고 동영상 화면의 윈도우명을 'YoLov3 detection:으로설정하자.
웹캠을 사용치 않으므로 cv2.VideoCapture(0) 을 # 처리하자.
테스트용 동영상 solidWhiteRight.mp4 는 끝부분에 첨부해 둔다.
width와 height 값을 읽어 frame_size 로 두자.
frame rate 는 Default 로 30으로 둔다.
아울러 YoLoV3 에 의한 객체 인지 박싱 결과와 비젼 처리결과를 합성하여 실시간 영상을 화면에서 구현함과 동시에 mp4로 저장하기 위해서 fourcc 를 설정하고 cv2.VideoWrite 명령을 실행하여 처리한기로 한다.
그 다음 위치에 YoLoV3 커늘 실행 이전에 비젼처리코드를 넣기로 하자.

영상을 계속 읽을 수있도록 무한루프인 while True: 를 실행하자. cv2.VideoCapture 명령 실행 후 영상처리 불리언 결과인 ret가 False 이면 break 중단 처리하고 이상이 없으면 그 다음 비젼 처리 과정을 시작한다.

비젼처리 과정은 앞서 언급했던 Jupyter 코드들을 종합해서 핵심만 뽑아서 작성했다. 단 영상 특성에 맞춰서 vertices 부분을 사용자가 조절해야 함에 유의하자. 실제로 자율주행 3단계를 준바할 경우에는 영상을 찍기 위한 차량의 중앙 상단 백미러 앞부분에 정확히 웹캠을 위치시킨 후 차량 후드 부분이 보이지 않도록 정확하게 조정해서 영상을 찍은 후 vertices 를 결정해야 한다.

그 이유는 아무튼 Canny 와 ROI 와 Hough 처리를 한다고해도 객체들간의 특징 점들을 연결하는 수평선에 가까운 노이즈들이 지나치게 많이 검출되기때문에 이런 부분을 감추기 위해서 필수적이다.
ROI 는 앞서 기술된 region of interest 함수를 불러 사용한다.
Hough 처리에 얻어진 직선 데이터들을 작도하여 비전 처리 과정이 종료되면 이 결과를 대상으로 YoLoV3 알고리듬에 의한 처리를 시작한다.
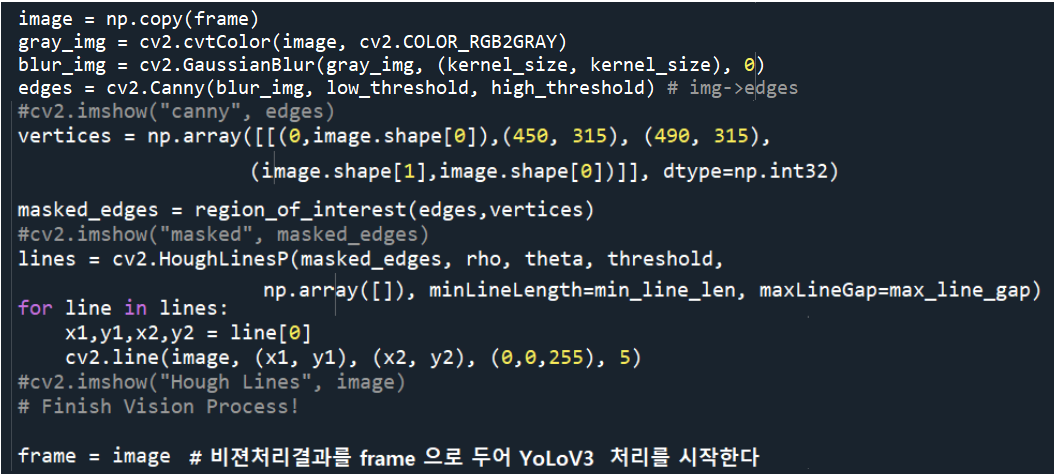
resizing 작업을 통해서 YoLoV3 알고리듬으로 객체들을 탐지하고 박싱, 스코어, 클라스 종류, 수량, 클라스 명칭 처리를 실행하여 한 frame 처리를 완료한다.
fourcc 설정에 따라 cv2.VideoWriter 명령에 따라 out.write 명령을 사용하여 저장하자.
일단 실행 결과 저장된 영상을 체크해 보면 길이가 fps = 30 일떄 8초로 대단히 짧은 데 이는 fps 를 30 으로 고정했기때문이다. fps = 10 이면 18초, fps = 5 이면 44초로 늘어난다. 실제로는 GPU 없이 느린 속도로 실행되는 것 같지만 중간중간 실시간으로 계산된 fps 값이 대단히 작다는 점이 원인인것 같다. 참고하길 바란다.

마지막 부분은 전형적인 OpenCV 코드와 유사하다. 함수 main() 이 종료되면 main 코드에서 실행시킨다.

실제 자율주행 차량에서는 비젼 처리 결과에 따라 제어문을 넣어서 경고음 처리라든지 아니면 운전대 조향 제어를 해야 할 것이다. 윈도우즈 PC가 아닌 젯슨나노라든지 또는 라즈베리 파이 보드를 사용한다면 OS가 Ubuntu 나 Rasbean 이므로 GPIO 라이브러리 및 하드웨어 인터페이스가 지원되며 이를 통해 스피커나 액츄에이터나 모터를 제어 할 수 있을 것이다.
Teslar 또는 MobileEyeQ 의 자율주행 칩도 젯슨나노 보드와 유사하게 GPIO 인터페이스 가 가능하도록 제작되었을 것이다.
이로서 자율주행 레벨 2 ~3 단계를 오갈 수 있는 demo 코드 작성을 마치도록 한다.
코드가 그리 길지 앟기때문에 내용을 읽고 직접 타이핑하여 성공시키길 바란다.
첨부된 동영상을 입력으로 사용하길 바란다.
'자율주행' 카테고리의 다른 글
| 7장 MathWorks 자율주행 MATLAB 코딩 II (0) | 2022.09.28 |
|---|---|
| 7장 MathWorks 자율주행 MATLAB 코딩 I (0) | 2022.09.28 |
| LiDAR(Light Detection And Ranging Sensor) 객체감지 및 위치 측정 (0) | 2022.09.21 |
| Colab 에서 YoLoV4 를 실행해 보자. (0) | 2022.09.18 |
| OpenCV Hough Transform에 의한 차선 작도 VIII (0) | 2022.09.16 |