실습을 위해 turorialimages.zip 폴더를 다운 받아 압축을 해제한 후 바탕화면의 개인사용자 폴더에 images 폴더를 넣도록 하자.
아나콘다 Navigator 를 열고 Matplotlib 와 Numpy 라이브러리가 설치되어 있는 가상환경에서 Jupyter 를 launch 시킨 후 이 코드를 열도록 하자.
1. 8X8 픽셀 matrix 이미지 처리 실습: 픽셀의 이해
윈도우즈에서 그림판 소프트웨어를 사용하여 8X8 즉 64개의 사각형 점들로 이루어지는 dot.png 파일을 대상으로 간단한 파이선 언어에 익숙해지기 위한 실용적인 실습을 해보기로 하자.
다운로드 받은 tutorialimages.zip 파일의 압축을 풀도록 한다. 압축을 푼 폴더 내부의 images 폴더 안에 아래와 같은 데이터 파일들이 들어 있음을 확인한다.
그림판에서 dot.png를 불러오자. 크기가 작으므로 보기 메뉴에서 6번 정도 확대하면 아래와 같은 검은 색 점을 볼 수 있다.
위 그림판의 흰 면에서 검은 점 크기 기준 8X8 갯수의 이미지를 포함할 수 있다.
크기 조정 명령을 눌러 창이 뜨면 픽셀을 선택하고 가로 세로의 숫자를 확인하자.

검은색 점 옆에 팔레트 상의 초록색을 선택하여 검은 색 점 옆에 찍은 후 색편집 명령을 눌러 뜨는 창에서 빨강 녹색 파랑의 값이 34, 177, 76 인지 관찰해보자.


여기까지 점검이 되었으면 압축 해제한 tutorialimages.zip 의 images 폴더를 윈도우즈 바탕화면의 개인 사용자 폴더에 옮겨 놓고 다시 아나콘다의 Jupyter를 시작하도록 한다.
http://ejleep1.tistory.com/1346 에서 쥬피터 실행파일 pixel_image.ipynb 를 다운받아 바탕화면 개인사용자 폴더에 넣고 아나콘다 가상환경에서 Jupyter를 launch 시킨 후 실행시키자.
아울러 아래와 같이 파이선 코드를 작성 저장해서 실행시켜 보자. PIL은 Python Imaging Library의 약어이며 이미지를 생성하거나 불러서 로딩하거나 하는 역할을 한다. Python 자체의 라이브러리이므로 아나콘다 가상환경에서 별도로 설치할 필요가 없다.
Numpy는 과학기술 컴퓨팅 지원을 위한 모듈로서 어레이 처리 기능이 강력하다.
Matplotlib 는 이미 설치가 되어 있음에 유의하자.

이 파이선 코드를 실행하면 4X8 matrix 형태의 데이터가 8개 세트가 출력된다.
첫 번째 matrix 의 첫 줄 데이터 [0 0 0 255]를 살펴보자. RGB 컬러를 표시함에 있어서 256 색상 해상도를 사용한다. R G B 값이 [0 0 0 ] 이라함은 빛의 삼원색 합성에서 아무 빛도 없는 상태이므로 합성하면 검정색이 된다. 반대로 [255 255 255 ] 는 RGB각 각각 100% 일 때 합성하면 흰색이 된다는 뜻이다. 네 번째 숫자 A 또는 Alpha는 투명도(opaque)를 뜻한다. 0 이면 수채화 색처럼 투명이며 반대로 255 이면 불투명을 뜻한다.
첫 번째 4X8 matrix는 그림판의 첫 번째 줄을 구성한다. 총 8개의 matrix 라함은 8줄을 의미한다.
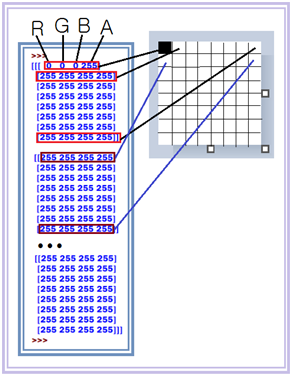
윈도우즈 그림판에서 dot.png 파일을 불러 검정색 사각 점 옆에 초록색 사각 점을 찍은 후에 matrix 가 어떻게 변화 되었는지 살펴보자. 초록색 사각 점의 RGB 데이터가 34, 176, 76 임에 유의하자.
이번에는 images 폴더 안에서 그림과 같이 dotndot.png 파일을 불러내자.

한편 아래의 Jupyter 파이선 코드를 실행시켜 보자.

첫 번째 matrix 의 두 번째 줄에서 34 177 76 즉 초록색 사각점에 대한 정보를 확인할 수 있으며 나머지 데이터는 아무런 변동이 없다.
2. matplottlib 라이브러리에 의한 8X8 픽셀 matrix 이미지 작도
픽셀 단위에서 그래픽 출력을 이미 관찰하였으므로 images 폴더에 위치한 numbers 폴더에 저장된 컬러 문자 사례를 아래의 파이선 코드를 사용하여 출력해보자.
입력 데이터는 np.asarray() 명령을 사용하여 어레이 형태로 변환된다. type(iar) 을 출력해 보면 np,ndarray(numpy n 차원 어레이) 로 임을 알 수 있다.
코드 옆의 출력 결과는 해 당 이미지의 첫 번째 열에 해당하는 데이터이다. [255 242 0 255]은 노란색을 나타내며 [63 72 204 255]는 청색(Blue)에 가까운 색을 나타낸다.

3. 8X8 픽셀 matrix 이미지 Threshold 처리 실습
4개의 그래픽 이미지를 한 번에 출력하는 루틴을 살펴보자. 픽셀의 threshold(문턱값) 처리를 위해 imageArray 를 인수로 하는 함수 def threshold() 루틴을 도입하였다. 인수로 넘겨 받는 imageArray 는 연산을 통해 그 원내용이 변경될 수도 있으므로 차후의 사용을 위해서 imageArray를 한 벌 복사하여 newAr에 저장한다. balanceAr 은 리스트 데이터 구조를 가지며 선두에 그 크기를 모르는 상태에서 선언한다.

넘겨받은 인수 imageArray 는 그 크기 규격을 알 수 있다. 이로부터 각 열에 해당하는 eachRow 를 추출하여 픽셀 값들을 합산하여 평균값(mean)을 구한다. 이 값이 생성될 때마다 크기가 미정인 상태의 리스트 변수 balanceAr 에 첨부(append) 저장 한다. 루프 작업이 끝나야 리스트 변수 balanceAr 의 형상(shape)이 확정된다.
4개의 이미지 파일들을 불러와 어레이로 두자.
matplotlib 의 subplot2grid 명령을 사용하여 4개의 그래프를 함께 매트릭스 형식으로 처리하자.

이미 복제해 두었던 newAr 의 eachPix의 평균값을 대상으로 balance 값보다 큰지 작은지를 판별한다. balance 값 보다 클 경우는 RGBA 값을 각각 255로 설정한다. A 값은 원래 255 였으므로 아무런 변동이 없다. 반면에 balance 값 보다 작을 경우는 RGB 값을 각각 0으로 설정한다. 단 A 값은 원래 255 였으므로 아무런 변동이 없다.
이렇게 처리 후 imageArray 에 해당하는 newAr를 반환한다.
def threshold() 이 후의 메인 코드에서 문자 png 파일을 불러 출력하는 과정에서 threshold() 처리를 하면 이미지가 흑백으로 처리된다. 아래의 코드 예제는 첫 번째 이미지를 처리하는 코드이다. 원래 이 예제에서 첫 번째 이미지는 흑백이었으므로 출력 결과에 아무런 변화가 없다.

threshold 처리된 결과를 살펴보면 이미지가 나타내려는 상징이 그대로 살아 있음을 알 수 있다. 즉 threshold 알고리듬에 의해 처리된 이미지를 대상으로 컬러로 인한 channel 수 증가에 따른 컴퓨팅 부담을 줄이면서 image classification 작업을 수행해도 거의 동일한 결과를 얻을 수 있기에 OpenCV 응용 코딩에서 흔히 사용된다.
현재의 inhouse 코드 사례와는 달리 OpenCV 명령 사용에 있어서 픽셀 색상 처리과정을 살펴보자.
※ 과제: 이미지 픽셀 처리를 위한 OpenCV 와 Matplotlib 비교
OpenCV 의 BGR, RGB, Gray 및 matplotlib 의 RGB format 비교
http://ejleep1.tistory.com/1555
4. 문자인식을 위한 텍스트 파일 처리 및 저장
이미지화된 문자를 인식 처리하기 위해서는 즉 학습을 시키기 위한 기본적인 데이터가 필요하다. 앞에서 이미 다운받았던 tutorialimages.zip 파일의 images 폴더 속에 포함된 numbers 디렉토리에 0에서 9까지의 문자 이미지 데이터가 아래와 같이 png 파일 형태로 수록이 되어 있다. 저장된 위치 경로는 바탕화면 개인 사용자폴더에 images 폴더를 설치하였다.
데이터 수록 순서는 0.1∼0.9, 1.1∼1.9, ⚫⚫⚫, 9.1∼9.9 까지 이다. 소수점 값이 다르면 같은 글자라도 픽셀 위치가 다르다.
이 png 데이터별로 파일명 위에 보이는 작은 숫자는 이미지임에 유의한다. 이 이미지를 보기 원한다면 윈도우즈에서는 그림판 소프트웨어를 사용하자.
숫자를 포함하는 문자 이미지 학습이나 인식을 위해서는 비교를 하기 위한 기본
4. 문자인식을 위한 텍스트 파일 처리 및 저장
이미지화된 문자를 인식 처리하기 위해서는 즉 학습을 시키기 위한 기본적인 데이터가 필요하다. 앞에서 이미 다운받았던 tutorialimages.zip 파일의 images 폴더 속에 포함된 numbers 디렉토리에 0에서 9까지의 문자 이미지 데이터가 아래와 같이 png 파일 형태로 수록이 되어 있다. 저장된 위치 경로는 바탕화면 개인 사용자폴더에 images 폴더를 설치하였다.
데이터 수록 순서는 0.1∼0.9, 1.1∼1.9, ⚫⚫⚫, 9.1∼9.9 까지 이다. 소수점 값이 다르면 같은 글자라도 픽셀 위치가 다르다.
이 png 데이터별로 파일명 위에 보이는 작은 숫자는 이미지임에 유의한다. 이 이미지를 보기 원한다면 윈도우즈에서는 그림판 소프트웨어를 사용하자.
숫자를 포함하는 문자 이미지 학습이나 인식을 위해서는 비교를 하기 위한 기본데이타로서 위와 같은 일정한 픽셀 규모 예를 들자면 MNIST 예제서는 28X28 인 반면에 본 예제에서는 아주 간단한 8X8로 준비된 그림 파일이 반드시 필요하다. 0∼9까지의 숫자 인식을 위한 최소한도의 해상도가 8X8 이다.

숫자 판별 인식을 위한 코딩 단계에서 위의 그림 데이터들을 직접 모두 읽어 들여 DRAM 메모리에 저장하기에는 부담스러울 우려가 있다. 따라서 위의 png 그림 파일들을 모조리 읽은 후 텍스트 파일로 데이터 구조를 변환해 저장해 두고 필요하면 불러 쓰도록 하자. 택스트 파일로 변환해 버리면 굳이 PIL의 Image 라이브러리를 사용하지 않아도 된다.
따라서 함수 createExamples 에서 png 데이터 파일들이 들어 있는 폴더 위치를 정확히 지정하여 생성할 파일명을
'numArEx.txt' 로 모드는 ‘a’ 즉 append 로 두어 오픈하여 numberArrayExamples 로 설정하자. 참고로 ‘r’ 이면 read, 'rb'이면 read binary, ‘w’면 write 모드가 된다.

텍스트 파일 생성을 위해서 range(1,10) 을 변수 numbersWeHave 로 두어 for 명령의 loop 범위로 설정하면 eachNum은 [1, 2, ⚫⚫⚫, 9] 즉 1 부터 시작해서 9개의 정수 데이터들에 순차적으로 대응하는 index를 나타내게 된다.
이중 구조의 for 루프를 설정하여 넘버링 작업을 하고 images 폴더 내부의 numbers 폴더에 포함되어 있는 png 파일 중에서 0.1png∼0.9png 를 제외한 나머지를 대상으로 리스트 형 데이터인 imgFilePath를 생성한다.


eiar = np,array(ei) 명령은 NumPy 라이브러리 모듈의 지원으로 rank 가 64 인 1차원적인 어레이를 생성한다. 결국 2중 for 루프를 다 돌면 9X9 어레이가 생성되는 셈이다.
eiar.tolist() 명령은 생성된 eiar 1차원 어레이를 리스트 데이터화 하는 과정이다. 파이선 코딩에서 수학에서 사용하던 어레이나 매트릭스를 그대로 쓰는 것이 아니라 항상 리스트화 하여 문법에 적용하는 점에 유의하자.
str(eiar.tolist()) 명령은 리스트 데이터화 된 eiar.tolist()를 출력할 수 있도록 string 즉 문자열 처리하는 과정이다.
한편 lineToWrite 이라는 변수를 정의하고 이번에는 1∼9 까지의 eachNum 수에 :: 을 더하고 스트링 처리된 리스트 데이터 eiarl 을 라인 단위로 처리한 다음 \n 즉 줄 바꿈 기호를 덧붙여 numberArrayExamples 에 덧붙여(appending) 출력한다. 즉 images 폴더에 numArEx.txt 라는 테스트 파일로 출력되어 현재의 코드인 pixel_image.ipynb 와 동일한 폴더에 저장된다. 아래는 저장된 결과를 열어서 일부를 출력한 결과물이다.
주의할 점은 이 코드를 여러 번 실행 할 경우 같은 내용이 되풀이하여 덧붙이기 즉 append 된다. 따라서 파일을 열어보고 덧붙이기 되어있으면 삭제하고 새로이 한 번만 생성해야 한다. 문자로 처리된 numArEx.txt 파일만 불러 로딩해도 되므로 번거롭게 일일이 그림파일 1.1png∼9.9png 를 하나씩 불러들일 필요가 없어진다.

주의할 점은 이 코드를 여러 번 실행 할 경우 같은 내용이 되풀이하여 덧붙이기(append) 된다. 따라서 파일을 열어보고 덧붙이기 되어 있으면 삭제하고 새로이 한 번만 생성해야 한다.
일단 문자로 처리된 numArEx.txt 파일만 한번 불러 로딩해도 되므로 번거롭게 일일이 1.1png∼9.9png 를 하나씩 불러들일 필요가 없어진다.
더 구체적인 내용에 관해서는 아래의 원문 블로그를 참조해 보자.
참조: Introduction and Dependencies
How to perform basic image recognition with the use of Python
https://pythonprogramming.net/image-recognition-python/
'Python' 카테고리의 다른 글
| 쌍극좌표계 작도 (0) | 2025.03.18 |
|---|---|
| 리눅스 폴더 구조와 구글 마운팅 (0) | 2022.08.15 |
| Jupyter Notebook Tutorial: 파이선 코딩 기초 (0) | 2022.07.23 |
| 파이선 파형 그래프 작성 기초예제 (0) | 2021.12.26 |
| 파이선 Matplotlib 오실로스코프 듀티 파형 FFT 애니메이션 예제 V (0) | 2021.12.26 |