※파이선 코딩 초보자를 위한 텐서플로우∙OpenCV 머신 러닝 2차 개정판 발행
http://blog.daum.net/ejleep1/1175
OpenCV를 비롯한 object detection 코드에서 Image에 포함된 object들을 찾아낸 후 보기에 편하게끔 흔히 사각박스를 작도하여 보여준다. 즉 object 를 둘러사는 이 사각박스를 흔히 Bounding Box 라고 하며 그 주위에 찾아낸 object 의 클라스 즉 라벨 명을 기입하곤 한다.

OpenCV 비전 코드 사용 사례를 보면 object 를 찾긴하되 ROI(Region of Interest) 즉 관심 영역의 크기를 사용자가 형태와 크기, 예를 들면 직사각형 및 가로 세로 크기 값을 지정하게끔 되어 있다. 한편 원을 지정할 경우에는 원의 반경과 반경을 지정해 줘야 한다. 이러한 방식으로 Bounding Box 즉 BBOX 를 이미 많이 사용하고 있다.

지금의 Image Classification 영역에서는 더 나아가 검출(detect)된 각각의 object들의 경계선을 긋고 Object의 픽셀 하나하나에 클라스 라벨 값을 확인하여 색상을 입히는 semantic segmentation 과 더 세밀한 instance segmentation 작업이 광범위하게 이루어지고 있다.
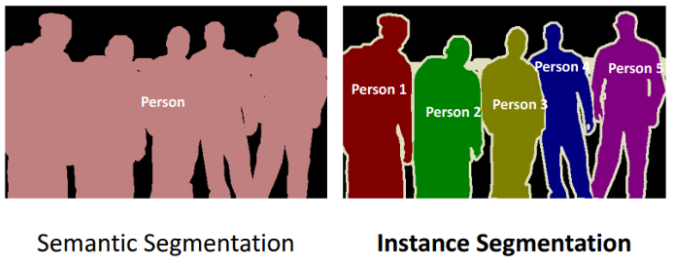
이와같은 정밀도를 얻어내기 위한 중간 과정으로서 일단 object 들이 detect된 상황에서 이러한 segmentation 작업을 세밀히 하기 위해서좀 더 해상도를 높일 수 있도록 Anchor Box 개념까지 확장하여 적용되고 있다. 앵커박스는 하나의 Ground Truth Box 가 결정되면 그 중심점에 대해서 축척과 aspect ratio를 사용하여 5~9개를 정의하여 object 의 세밀한 검출을 시도하며 실시간 실행이 어려울 정도로 컴퓨팅 부담이 상당히 커진다.
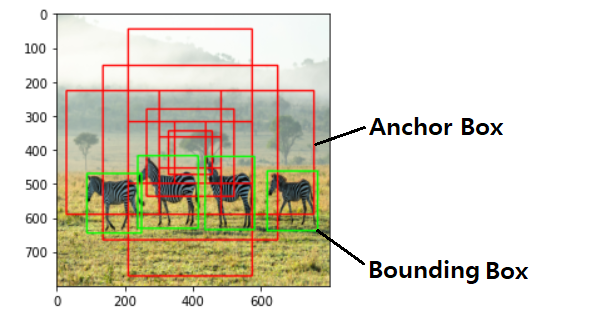
개개의 object 를 둘러 싸는 Bounding Box 는 일단 사용자가 눈으로 보든 아니면 특정한 알고리듬을 사용하든 사용자가 직접해야 한다고 볼 수 밖에 없는데 여하튼 사용자가 결정한 Bounding Box를 Ground Truth Box 로 하여 상대적으로 고해상도로 object의 픽셀 단위까지 찾아내어 색상 처리하기 위한 다소 복잡한 알고리듬으로 분류되는 FCN, R-FNN, Fast R-CNN,... 등의 다양한 알고리듬들이 이미 출현했음에 유의하자.
이와같은 상황에서 Image Classificatin 을 제대로 이해하기 위해서는 단계적으로 사용자의 알고리듬 이해를 대단히 기초적인 단계로 부터 체계적으로 학습해 나가야 할 필요가 있을 것이다. 그렇치 못할 경우 엄청나게 시간적으로나 경제적으로 시행착오를 겪을 가능성이 농후하다.
제대로 된 Image Classification 코드 작성을 위한 출발점으로 Bounding Box 를 찾아내고 라벨값을 부여하는 코드를 GitHub에서 다운받아 연습해 보도롣 하자. 이 코드는 Python 2.7 이므로 다운 후 실행 코드에서 몇가지 수정하여 Python 3 버전화 하도록 한다.
Multi Class용 BBox-Label-Tool: https://github.com/jxgu1016/BBox-Label-Tool-Multi-Class
아래는 GitHub 와 다운받아 압축 해제 후 설치한 폴더들을 보여준다.
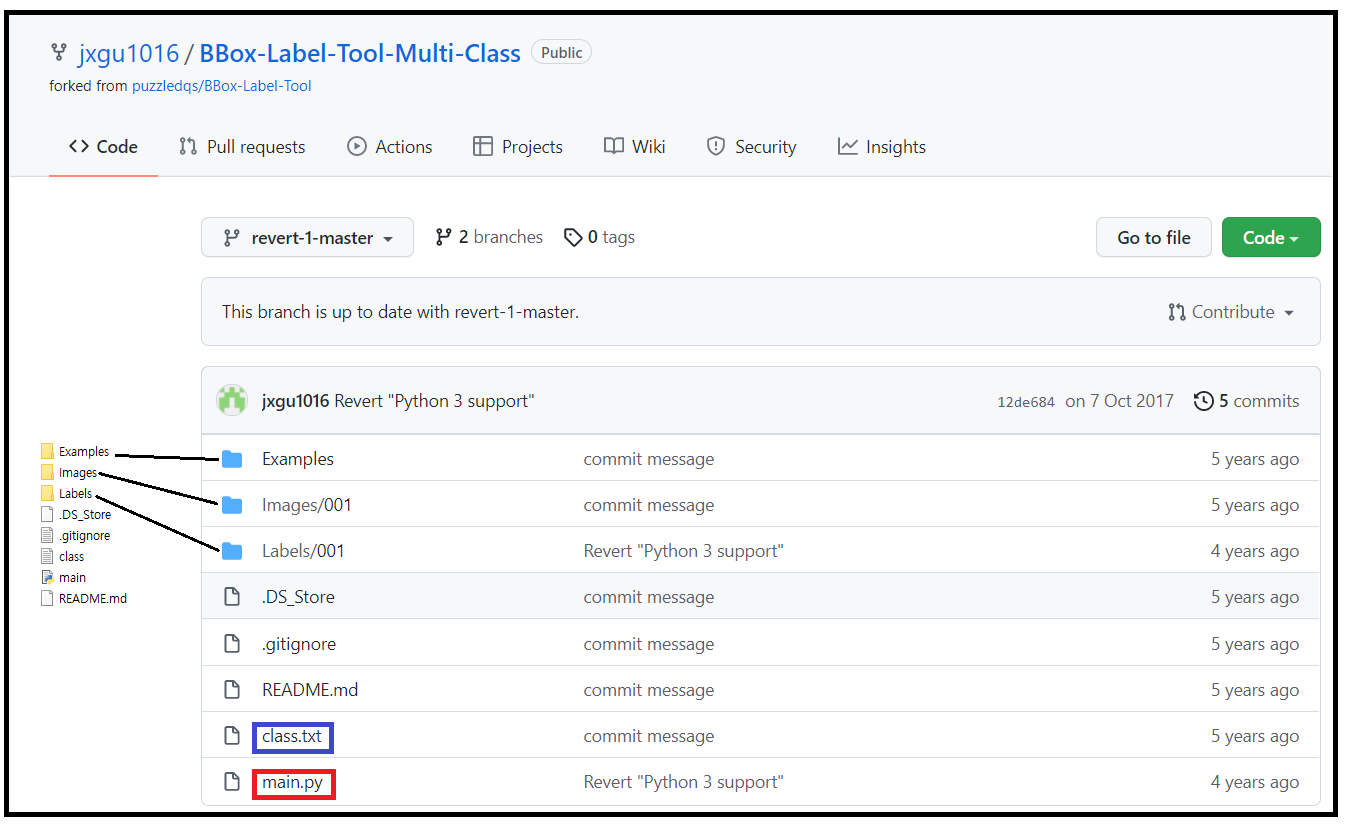
main.py 를 아나콘다에서 실행하면 tkinter 그래픽에 의한 팝업 편집창이 뜨며 Examples 에 포함된 3개의 개이미지들이 이미 Bounding Box 처리되어 뜬다.
Images 폴더에는 사용자 연습용 그림이 3개 들어 있다.
Labels 에서는 이미 작업이 완료된 Examples/demo 에 포함되어 작 이 완료된 이미지들의 Bounding Box 좌표 2개와 라벨 값(dog, cat 등)이 기입된 텍스트 파일이 test, test2, test3 순서로 들어 있다.
main.py 를 아나콘다에서 열어보면 구2.7 python버전의 Tkinter 를 확인할 수 있다. 대문자 T를 소문자 t로 변경한다.
코드 중간 중간에 print 명령이 ( ) 없는데 다 넣도록 한다. 실행시키면 팝업창이 뜬다.

Image Dir 박스에 1을 입력 후 Load 버튼을 클릭하면 아래의 팝업창을 볼 수 있다.
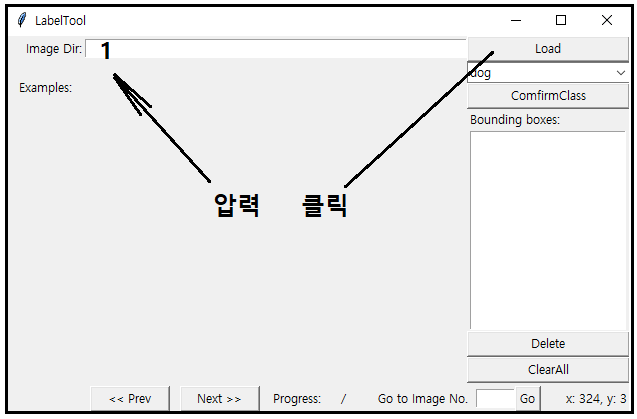
팝업창에 3개의 Examples/demo 이미지들과 Images 폴더의 첫번째 그림이 뜬다. 이 첫번째 그림 이미지파일명 testfmf 대상으로 여기서 Bounding Box 작업을 하고 Load 버튼 밑에 object들의 라벨 값이 보이는데 이들은 class.txt에 등록된 클라스 라벨 값으로서 dog 은 이미 등록되어 있다. 어떻게 결과가 얻어지는지 확인하기 위해서 test.txt 에 작성된 내용이 있다면 지워 두도록 한다.
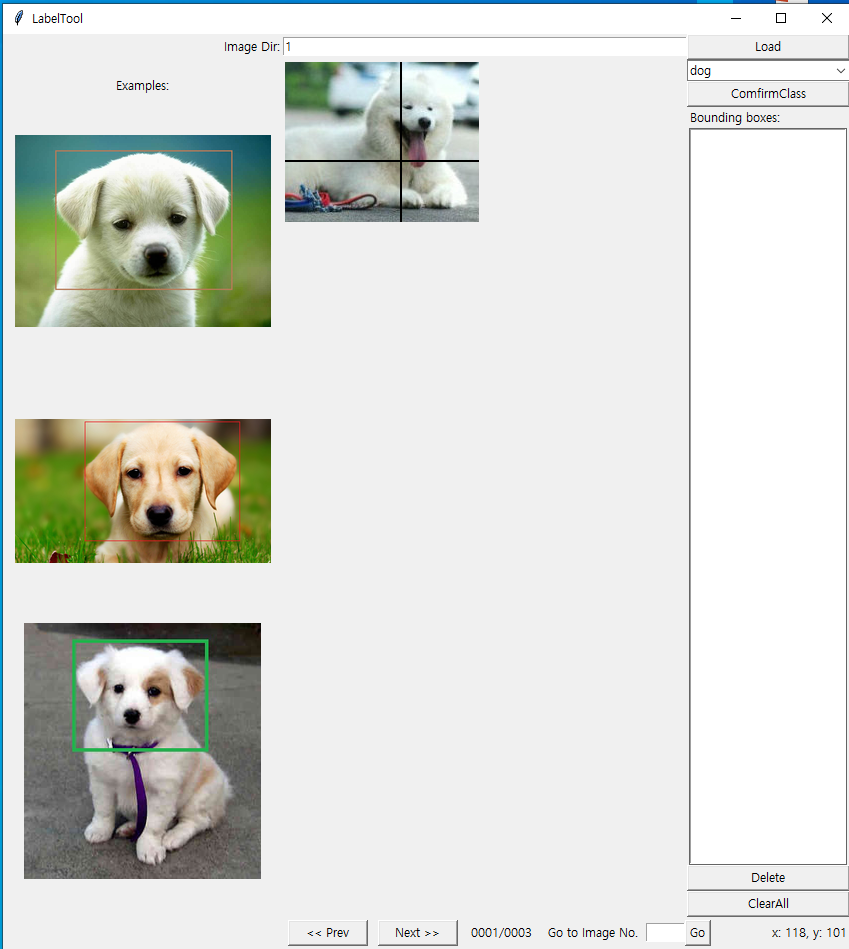
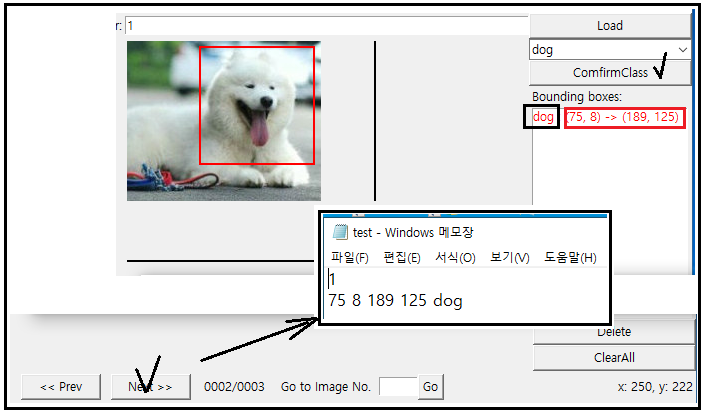
ConfirmClass 버튼을 누르면 dog 이 입력되고 커서를 움직여 Bounding Box 작업을 해주면 좌표 2개가 나타난다.
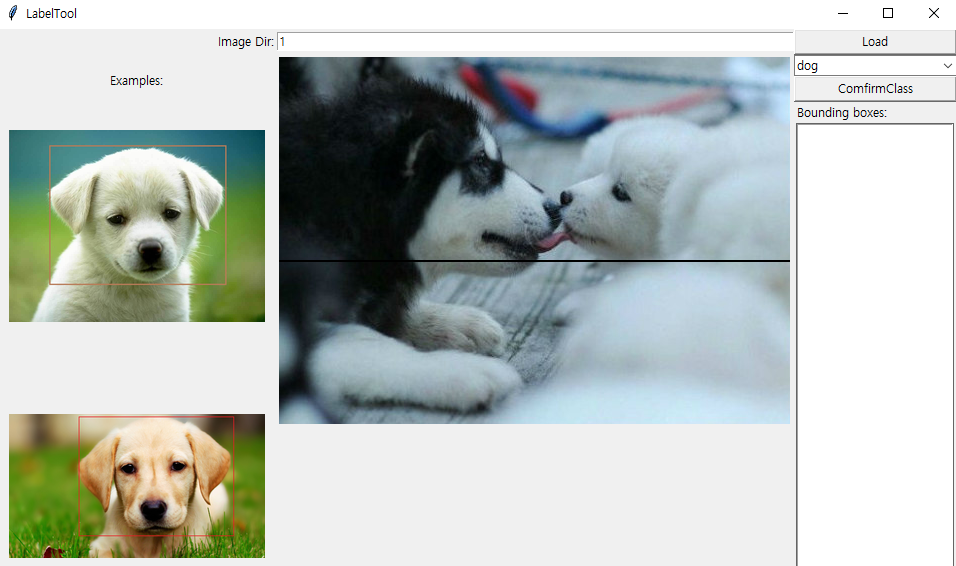
하단의 Next 버튼을 클릭하면 test.txt 파일이 그림 중앙의 결과 처럼 업데이트 됨을 알 수 있다. 아울러 팝업 창에는 그 다음 대상 이미지가 나타난다.
그다음 이미지가 나타난 펍업창
이런 과정이 Bounding Box 를 확정하는 알고리듬이다. OpenCV에 의한 object detection 코드라면 object들의 중심점을 찾아내지만 그 크기는 사용자가 모양과 크기를 지정해 주어야 하는 알고리듬이 바로 이 블로그에 소개한 내용일 것이다.
이 기초적인 Bounding Box 처리 알고리듬이 FCN, RCNN, Fast RCNN, Segmentation,... 관련 블로그를 읽는데 도움이 되길 바란다.
이어서 사각형 Bounding Box가 아닌 이미지의 윤곽을 도려내는 보다 세밀하게 다각형 형태로 윤곽을 따낼 수 있는 LabelMe 에 대해서 살펴보기로 하자. 아래 url 전체를 다운로드 받아 압축을 해제하고 폴더를 설치하자.
https://github.com/wkentaro/labelme
한편 설치 방법이 리눅스 우분투 윈도우즈 3가지 방식이 있는데 여기서는 윈도우즈 10의 아나콘다를 대상으로 그 방법을 살펴보기로 한다. python3을 택하여 설치하자. 첫줄 conda 명령에서 python 버전을 요즈음 기준으로 3.7 또는 그 이상으로 설정한다.
source activate labelme 명령은 리눅스형이므로 윈도우즈10에서는 conda 명령으로 대체해서 실행하자.
실행 후 가상환경 (base) 가 (labelme) 로 바뀌는 것을 볼 수 있다.
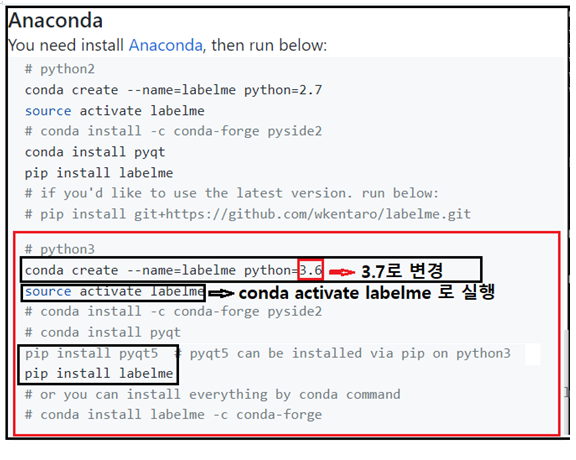
labelMe 를실행 시키는 가장 간단한 방법은 Open Terminal에서 아래와 같이 command line 명령 labelme 를 실행하는 방법이다.

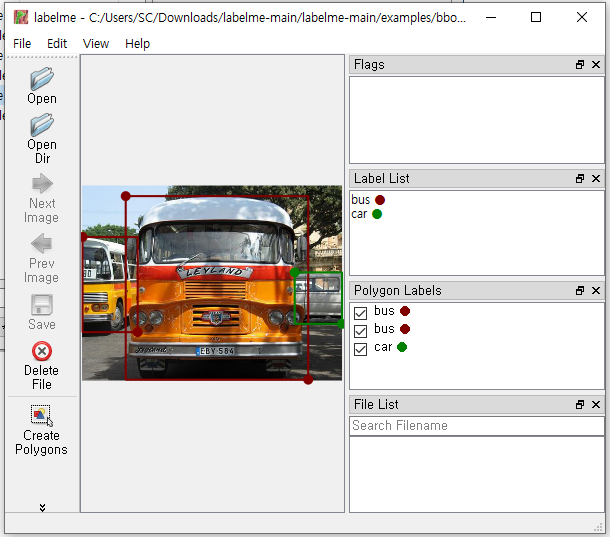
팝업 창에서 Open 아이콘을 사용하여 Examples 폴더에서 승합차 이미지를 불러오자. 이미 annotated(주석 작업이 이루어진) 된 즉 Bounding Box 작업이 이루어졌다.
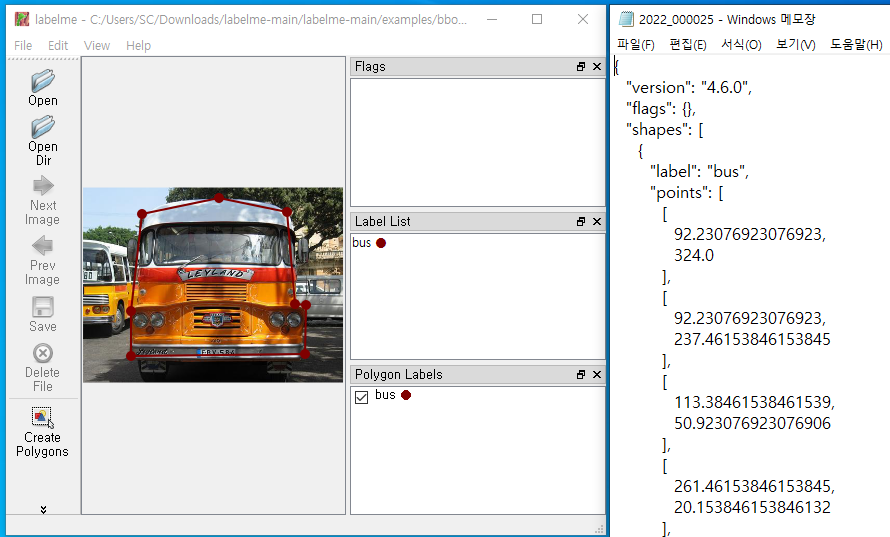
이미 작성된 내용을 지우고 다시 승합차 이미지를 대상으로 Polygon(다각형)작업을 실시한 후 열어본 json 형식의 텍스트 데이터 파일이다. 라벨 값과 polygon 조표값 생성을 확인할 수 있다. 이런 작업이 바로 semantic segmentation 학습 을 위한 train 데이터 준비에 필요하다는 측면에서 살펴 보았다.
스토리가 연결되는 다음 사이트를 읽어보세요.
Keras 기초 예제: U-Net 아키텍처 동물이미지 semantic segmentation
http://blog.daum.net/ejleep1/1198
Under Construction ...
'Semantic Segmentation' 카테고리의 다른 글
| Image Bounding Box 작업을 위한 윈도우즈10 LabelImg 설치 (0) | 2023.06.09 |
|---|---|
| Keras 기초 예제: U-net 아키텍처 동물이미지 semantic segementation (0) | 2022.01.08 |