※파이선 코딩 초보자를 위한 텐서플로우∙OpenCV 머신 러닝 2차 개정판 발행
http://blog.daum.net/ejleep1/1175
파이선 코딩 초보자를 위한 텐서플로우∙OpenCV 머신 러닝 2차 개정판 (하이퍼링크) 목차 pdf 파일
본서는 이미 2021년 11월 초부터 POD코너에서 주문 구입이 가능합니다. 참고로 책 목차에 따른 내용별 학습을 위한 코드는 이미 대부분 다음(Daum)블로그에 보관되어 있으며 아래에서 클릭하면 해당
blog.daum.net

Keras code 로 검색하면 쉽게 찾을 수 있는 Keras 예제 사이트에 수많은 예제들이 포함되어 있다. 그중에 이미 기초적인 코드 사례로 Timeseries 데이터의 Anomaly를 탐색하는 에제를 다루어 보았다.(https://blog.daum.net/ejleep1/1188)
이 사이트에 예제들은 잘 다듬어져 있어 구글 Colab 에 셀별로 복사하여 붙인 후 실행하면 별 문제 없이 실행이 잘되는 건 사실이다.
하지만 Keras 코드 예제 하나하나가 상당한 난이도를 가질뿐만 아니라 python 언어에 대단히 능숙성이 필요한 것 또한 사실이다. 그런 난이도에도 불구하고 코드를 효율적으로 요령있게 이해하여 파악할 수 있는 방법을 강구해보자.
사실 본 불로그에서 다루고자하는 semantic segmentation Image Classification예제는 앞서 포스팅했던 Timeseries 데이터의 Anomaly를 탐색하는 예제에서 채용했던 Autoencoder 기법과 높은 연관성을 가지는 주제임을 지적하고자 한다.
Autoencoding 이란 단적인 예를 들어 10종의 fashion mnist 이미지 데이터세트를 대상으로 1개층의 hidden layer 를 넣어 이미지 크기를 latent dimension 수만큼 Down Sampling 과정인 컨볼루션(convolution) 작업을 통해 줄인 후 다시 역으로 Up Sampling 과정을 통해 원래 크기로 원상 복구시키는 기법으로서 어느정도 입력 데이터 이미지와 비교하여 노이즈가 완전히 제거되었으면서도 유사한 이미지 결과를 출력해준다.
이 Autoencoding 기법을 fashion mnist 데이터 세트를 실대상으로 실질적으로 이해 보려면 latent dimension 값을 64,16,... 로 낮추면서 실행시켜보면 된다. 마지막 단에서 1X1 컨볼루션을 사용할 경우 복구된 이미지를 보면 거의 상당 부분의 원 이미지 정보를 분실한다는 것을 쉽게 확인할 수 있다. 1X1 컨볼루션 작업은 semantic segmentation 과정에서는 object 의 픽셀 단위까지 클라스 라벨 값을 부여하기 위한 과정에서 대단히 중요하다는 점을 지적한다.
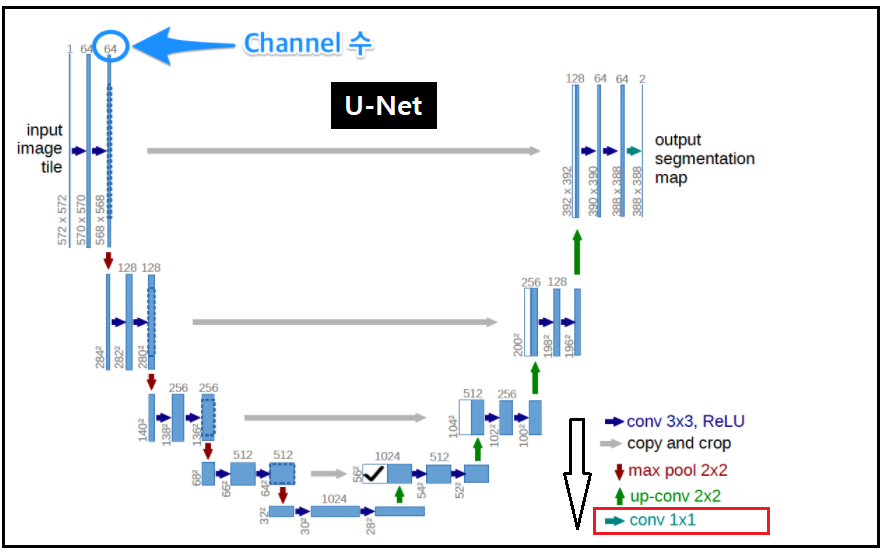
하지만 이 기법을 그대로 훨씬 더 복잡한 semantic segmentation에 적용하기에는 너무 조잡하여 원상복구된 이미지의 질(quality)가 너무 떨어진다는 지적이 있어 왔으며 이를 극복하기 위한 대안들이 2012년 이후로 홍수처럼 많이 연구되었다. 그 중에서도 초기에 U-Net 기법이 제안되었으며 Up Sampling 과정 중에서 이미지 정보 손실이 일어나는 부분을 보상해 주기위해서 Down Sampling 시의 중간 정보 데이터를 받아다가 단게별로 연결(concatenation) 보상해줌으로서 효율적인 이미지 복구가능한 알고리듬으로 제안 되었다.
다음의 U-Net 그림에서 초기에는 3X3 컨볼루션 작업에서 중앙으로 갈수록 컨볼루션 큐모가 줄어 결국 1X1 컨볼루션까지 축소된다는 점을 알 수 있다. 즉 이와같이 1X1 컨볼루션까지 작용하게 되면 Up Sampling 복원 단계에서 정보 손실이 많음을 지적해 두자.
한편 U-Net 의 대칭적인 구조를 이용하여 Down Sampling 에서의 정보를 Up Sampling 단계로 이관이 가능하다.
본론으로 돌아 와서 이미지 데이터세트들을 구글 Colab에서 다운로드 하자. 왼쪽의 압축파일과 아울러 압축해제된 annotations 폴더와 images 파일들이 있음에 유의하고 이 폴더를 열어서 파일 내용들을 살펴 보도록 한다.

annotations 폴더를 열어 README 파일을 읽어 보자 37종의 애완동물 데이터세트로서 각 클라스 별로 200 여매의 이미지를 제공한다. 37종이라고는 하지만 list.txt 파일 점검해보면 개와 고양이 위주로 37종인듯 하다.
아울러 각 동물의 세부 종명(breed), head of ROI(?), 픽셀 레벨 트리맵(3종의 맵 즉 배경, 전경, 분류불가)을 제공한다.

더 내려가 보면 trimaps 대한 설명과 아울러 list.txt 파일에 담겨 있는 데이터 구조로서 클라스 라벨명을 종명(SPECIES), 세부 종명(BREED), ID(?) 로 기술하고 있다. 즉 개는 1번, 고양이는 2번 그런 방식이다.
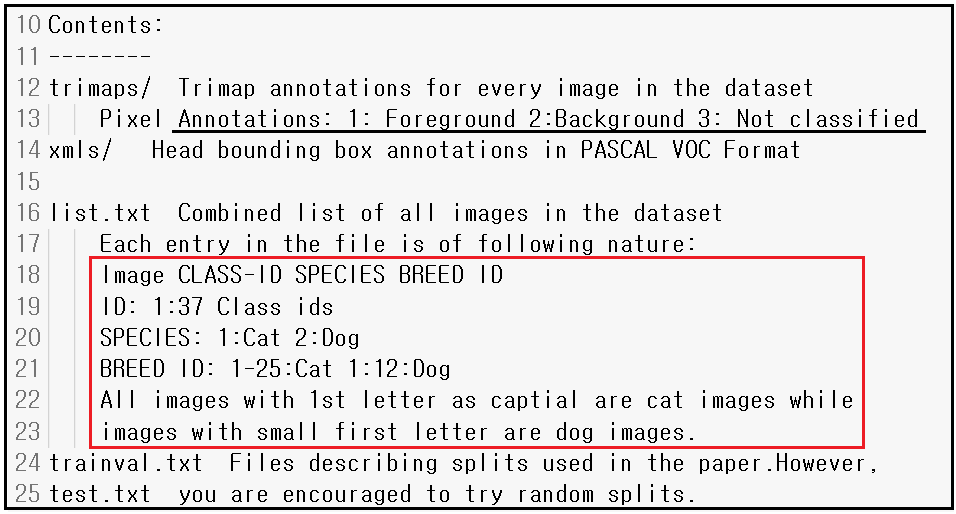
다음은 list.txt 파일 내용 사레로서 LabelMe 작업에서 보았던 것과 유사한 파일들이 생성되어 있다.

첫번째 이미지를 보면 다음과 같은 특수한 고양이 이미지 파일임을 알 수 있다. 이 semantic segmentation 학습(train) 을 위해 그 많은 짐승 종류별 상당한 준비 작업이 이루어 졌음을 알 수 있다.

그 다음 셀에서 이미지 처리과정을 살펴보면 images 폴더와 annptations/trimaps/ 폴더를 이미지 읽기를 위한 경로로 지정한다. 이미지 데이터와 학습된 이미지 데이터를 구분하기 위해서 각각 jpeg 및 png 확장자를 쓰고 있다.
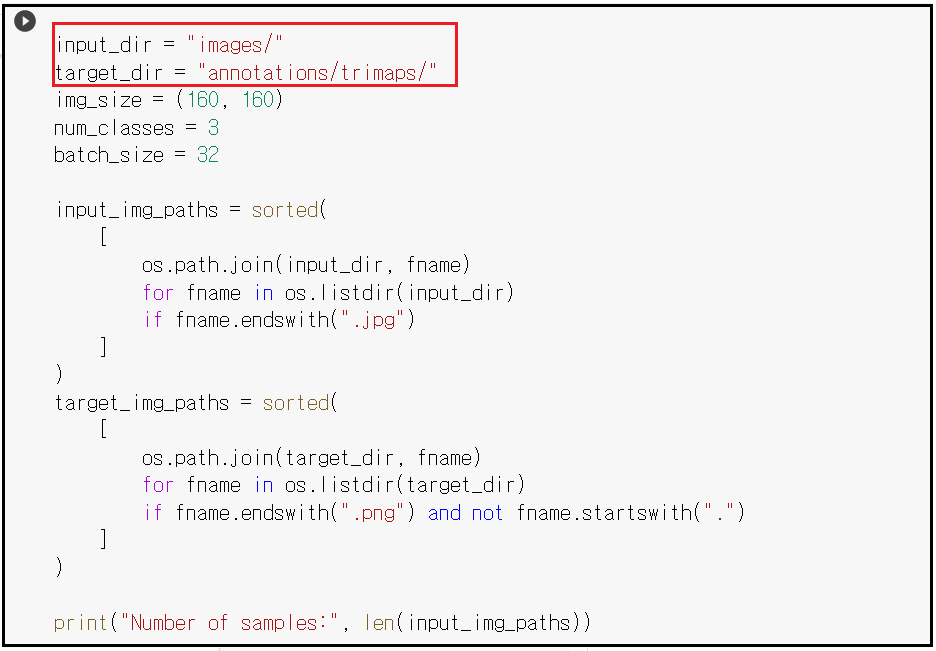
이 단계에서 semantic segmentation 작업을 위한 학습된 이미지르 보고 싶으나 어쩐 이유인지 출력이 되지 않는다. 파일 내용을 살펴보니 html과 마찬가지로 꺽쇠로 코딩된 xtml 코드인데 웹 출력 css 요소가 빠진 알맹이 내용만 확인 가능하였다.( labelMe 로 볼 수 있을 지 모르겠다.)
그대신에 그 다음 셀의 명령들을 사용하여 출력해 보도록 하자.

_paths 다음에 이미지 파일 번호를 지정하면 원 jpeg 이미지와 학습시킨 즉 LabelMe 작업까지 마친 이미지 사례를 볼 수 있다. 기본적인 배경, 개, 고양이의 3 클라스 처리를 위한 semantic segmentation 처리를 위해서 이 정도 규모의 학습 준비를 해야 하므로 만만치 않을 정도의 엄청난 노가다 작업이 필요할 것이다. 얻어진 이미지를 관찰해 보면 일종의 Autoencoding 된 "MASK" 로 볼 수도 있을 것이다.

해당 사이트 내용이 길므로 하이퍼 링크형의 shortcut 을 보고 해설하도록 하자. 이미 3파트를 처리했다. 나머지도 항목별로 클릭하면 블랙박스가 뜨므로 copy & paste 기법으로 구글 Colab 을 실행하면 된다.
나머지 내용은 데이터 벡터화 준비 단계, Keras 모델준비, Validation 분리, 학습, 예제 시각화이다.
Keras Model 준비 단계를 살펴보자. 제공하는 이미지의 shape 값이 (160, 160) 으로 설정되어 있다. 따라서 CNN 작업 전에 RGB 색상을 포함하는 이미지이므로 shape 값을 (3,160,160)으로 설정할 필요가 있다. 아울러 첫번째 컨볼루션 작업은 shape 값 (160, 160) 을 기준으로 Conv2D 를 그대로 적용한다. 하지만 그 다음 hidden layer 로 넘어가서 부터는 Conv2D 가 아닌 SeparableConv2D를 적용함에 유의하자. 그 중요한 이유중의 하나는 이 단계에서 Conv2D를 그대로 사용할 경우 수반될 수 있는 심각한 컴퓨팅 부담을 급격히 경감 시키기 위함이다. 이 문제에 관해서는 별도의 해설을 참조하기 바란다. (https://blog.daum.net/ejleep1/1204 )

특히 학습에 걸리는 시간이 25분 이상이므로 여유있게 실행해 보도록 하자.

학습(train)단계에서는 아래와 같이 train_gen 데이터를 사용하자.
model.fit(train_gen, epochs=epochs, validation_data=val_gen, callbacks=callbacks)반면에 validation 과정에서는 별도의 val_gen 데이터가 사용된다. model.predict( ) 명령에 val_gen 데이터를 입력하여 prediction 이 이루어진다. 한편 validation 원본 동물 이미지 데이터에 대한 비교를 위해서 LabelMe 작업 결과와 prediction 된 결과 (그 크기가 작음)를 비교하게 된다.
callback 파라메터를 사용하므로 학습된 가중치를 재학습 없이 pretrained 로 재사용이 가능하다.
val_gen = OxfordPets(batch_size, img_size, val_input_img_paths, val_target_img_paths)
val_preds = model.predict(val_gen)예측 결과를 보면 정답에 해당하는 가운데 이미지와 비교 시 어느 정도 유사성을 확인할 수 잇는 듯하다. 이미지 번호를 변경하여 많이 해 보도록 하자.

이와 같이 단일 object 즉 동물 한마리가 포함되어 있는 이미지의 segmentation 작업이 성공했다면 그 다음 이미지에 여러 종류의 object 들이 포함되어 있는 이미지의 segmentation 작업이 될 것이다.
Multiclass semantic segmentation using DeepLabV3+
https://keras.io/examples/vision/deeplabv3_plus/
Keras documentation: Multiclass semantic segmentation using DeepLabV3+
» Code examples / Computer Vision / Multiclass semantic segmentation using DeepLabV3+ Multiclass semantic segmentation using DeepLabV3+ Author: Soumik Rakshit Date created: 2021/08/31 Last modified: 2021/09/1 View in Colab • GitHub source Description: I
keras.io
Under Construction ...
'Semantic Segmentation' 카테고리의 다른 글
| Image Bounding Box 작업을 위한 윈도우즈10 LabelImg 설치 (0) | 2023.06.09 |
|---|---|
| Object Detection 코드 Bounding Box 생성 알고리듬 (0) | 2022.01.08 |