찾아주시는 분들께 양해의 말씀을 드린다. 이 글 작성 후 많은 시간이 흘러 이제는 AI 버전으로 퀵 리메이크하여 올려 드린다. 코딩에 많은 참고되시길 바랍니다.
Prompt: 구글 Colabo에서 Keras에 의한 CIFAR-10 image classification 작업을 재현 할 수 있는 코드를 작셩해주세요
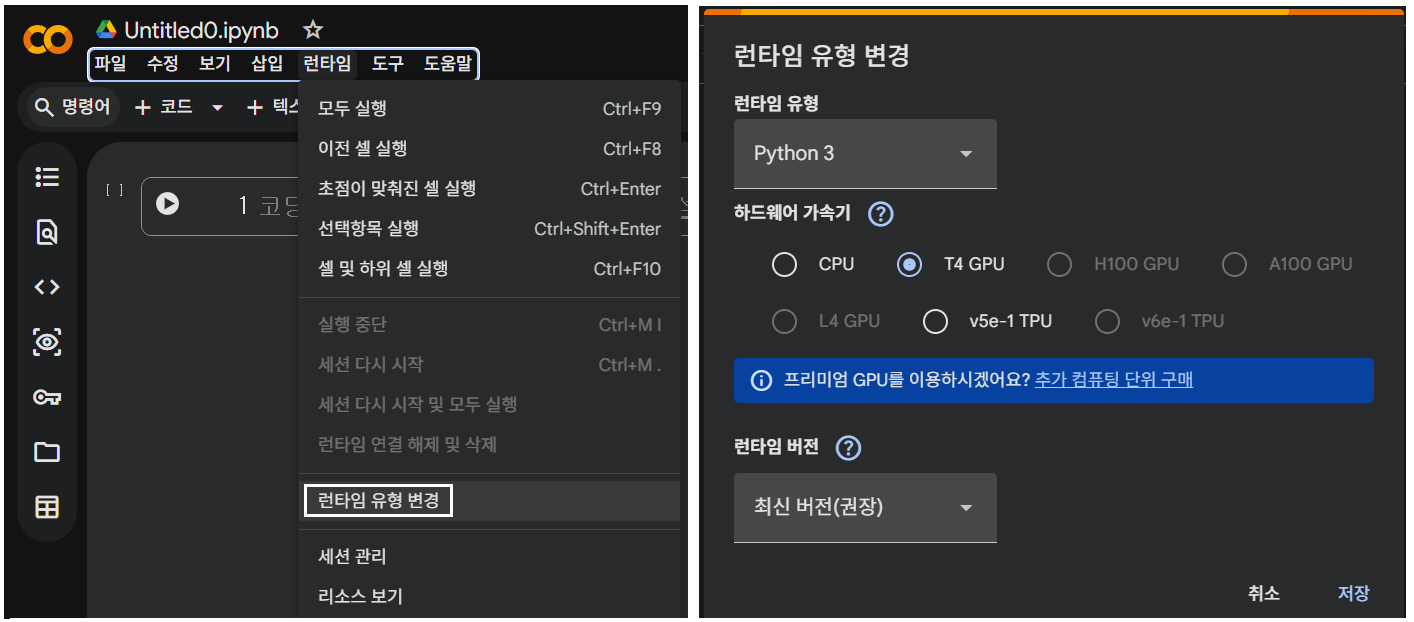
크롬에 로그인 후 NDRIVE 로 들어가서 +신규 버튼을 눌러 나타나는 메뉴에서 더보기를 눌러 Colaboratory 를 선택하여 Colab 편집기를 열고 아래와 같이 런타임 유형 변경에서 무료 GPU 서비스 가능한 T4 를 클릭하여 준비를 끝낸 후 아래의 코딩 작업을 계속한다.
구글 코랩(Google Colab) 환경에서 바로 복사해서 실행할 수 있는 Keras 기반 CIFAR-10 이미지 분류 코드입니다.
CIFAR-10은 10가지 카테고리(비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 배, 트럭)로 분류된 60,000개의 컬러 이미지 데이터셋입니다.
1. 라이브러리 임포트 및 데이터 로드
코랩에는 이미 Keras와 TensorFlow가 설치되어 있어 별도의 설치 없이 바로 시작할 수 있습니다.
아래의 코드는 위에 주어진 Prompt 로 Gemini 에서 동일한 코드 생성이 가능하며, 또는 여기서 직접 복사 가능하다. 아니면 하단에 첨부한 코드를 다운받아 실행시켜도 될 것이다.
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 1. 데이터셋 로드 (학습용 5만 장, 테스트용 1만 장)
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 2. 데이터 정규화 (0~255 사이의 픽셀 값을 0~1 사이로 변경)
train_images, test_images = train_images / 255.0, test_images / 255.0
# 클래스 이름 설정
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
2. CNN(합성곱 신경망) 모델 구성
이미지 특징을 추출하기 위해 Convolution 레이어를 쌓은 모델을 정의합니다.
model = models.Sequential([
# 특징 추출부 (Convolution & Max Pooling)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
# 분류부 (Dense layers)
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10) # 최종 출력 클래스 10개
])
# 모델 설정
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
3. 모델 학습 및 평가
코랩의 GPU 런타임을 사용하면 훨씬 빠르게 완료됩니다. (상단 메뉴: 런타임 > 런타임 유형 변경 > T4 GPU 선택)
일반 PC에서 실행하면 상당한 컴퓨팅 연산이 필요할 수 있으므로 반드시 GPU 효과를 실감해보자.
# 3. 모델 학습 (10회 반복)
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
# 4. 모델 평가
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'\n테스트 정확도: {test_acc*100:.2f}%')
4. 학습 결과 시각화
학습이 진행됨에 따라 정확도가 어떻게 변하는지 그래프로 확인합니다.
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()
💡 실행 팁
- 정확도를 높이려면? Dropout 레이어를 추가하여 과적합(Overfitting)을 방지하거나, 레이어 층을 더 깊게 쌓아보세요.
- 데이터 증강(Data Augmentation): 이미지를 좌우 반전시키거나 회전시켜 학습 데이터를 늘리면 성능이 더 좋아집니다.
이 코드를 실행하신 후, 특정 클래스(예: 고양이와 개)의 판별 능력을 더 높이고 싶다면 모델 개선 코드를 추가로 짜드릴까요?
녜로 답하면 수정된 코드를 제공할 것이다.
'머신러닝' 카테고리의 다른 글
| 윈도우즈 10 아나콘다3(64비트) 설치 및 가상환경 설정 (0) | 2022.07.23 |
|---|---|
| 심전도 데이터 Time Series Anomaly Detection (0) | 2022.02.13 |
| Keras 기초 예제: Time series anomaly detection using an Autoencoder (0) | 2021.12.28 |
| 스마트폰 촬영 데이터를 사용한 식물 Fresh/Wilt 판별 Keras 학습 코드 작성 (0) | 2021.09.17 |
| 암호화폐 상대강도지수 파이선 알고리듬:Python Cryptocurency RSI(Relative Strength Index) (0) | 2021.07.18 |