LeNet-5
PyTorch 에서 은닉층이 없는 간단한 MNIST 문제를 다뤄 보자.
Colab 에서 !pip install ⦁⦁⦁ 명령에 의한 별도의 PyTorch 라이브러리 설치 없이 torch 와 torchvision 을 import 하여 사용할 수 있다.
| 1 | # Simple Network MNIST import torch import torch.nn as nn import torch.optim as optim import torchvision |
torch 가 import 되면 torch.nn 과 torch.optim 을 사용할 수 있으며, torchvision 이 import 되면 이를 상속하여 datasets.MNIST를 사용할 수 있다.
60,000개의 데이터중 50,000개는 학습용이며 10,000개는 검증용이다.
| 2 | i# Load MNIST data train = torchvision.datasets.MNIST('data', train=True, download=True) test = torchvision.datasets.MNIST('data', train=False, download=True) print(train.data.shape, train.targets.shape) print(test.data.shape, test.targets.shape) ____________________________________________________________________ torch.Size([60000, 28, 28]) torch.Size([60000]) torch.Size([10000, 28, 28]) torch.Size([10000]) |
각각의 데이터 사이즈는 (28, 28) 이므로 flatten 하여 X_train 즉 일차원 어레이 리스트로 변환하여 정규화 한다. y_train 은 라벨값을 지정한다. 검증용도 마찬가지로 처리하자.
| 3 | X_train = train.data.reshape(-1, 784).float() / 255.0 y_train = train.targets X_test = test.data.reshape(-1, 784).float() / 255.0 y_test = test.targets |
class Baseline 을 선언하자. 외부에서 선언된 class 인 nn.Module 을 인수로 입력한다.
메서드 init 에서 self 변수들을 설정하여 초기화하도록 하자.
가장 먼저 특별하게 초기화해야 할 것은 외부에서 입력되는 즉 nn.Module 로서 super__init__() 으로 처리한다. 이는 nn.Module 내부에서 초기화가 이루어지지 않는다는 의미를 포함한다.
self 변수들 즉 랜덤수로 채워진 (784, 784) self.layer1, ReLU 활성화 함수를 사용하는 self.act, s랜덤수로 채워진 (784, 10) 인 elf.layer2 로 초기화한다.
self 변수와 메인으로부터 입력 데이터 x를 인수로 하여 순전파 메서드 forward 를 선언하자.
self 변수와 입력 데이터 x를 사용하여 순전파 연산을 실행한다.
| 4 | class Baseline(nn.Module): def __init__(self): super().__init__() self.layer1 = nn.Linear(784, 784) self.act1 = nn.ReLU() self.layer2 = nn.Linear(784, 10) def forward(self, x): x = self.act1(self.layer1(x)) x = self.layer2(x) return x |
class Baseline 을 model 로 설정하자.
optimizer 는 SGD(stochastic gradient) 를 사용한다. model.parameters() 는 모든 웨이트 값들을 포함하고 있는 변수를 의미한다. learning rate 는 0.01 로 둔다.
Loss 함수는 Cross Entropy 를 사용한다.
batch_size 는 100 으로 둔다.
| 5 | model = Baseline() optimizer = optim.SGD(model.parameters(), lr=0.01) loss_fn = nn.CrossEntropyLoss() loader = torch.utils.data.DataLoader(list(zip(X_train, y_train)), shuffle=True, batch_size=100) |
epoch 를 10 으로 설정하자. 하나의 epoch 연산이 완료되면 이때 얻어진 가중치들은 그 다음 epoch 단계에서 사용하여 정밀도를 올리게 된다.
지정된 epoch 담계에서 batch_size 를 100 으로 5000 번 반복 학습을 시킨다.
optimizer.zero_grad() 명령으로 기울기(gradient) 를 0.0 으로 초기화한다. 한편 Transfer Learning 의 경우 0.0 이 아닌 pretrained 값을 사용하는 경우를 참조하자.
순전파 연산이 완료되면 loss.backward() 명령에 의한 역전파 연산을 시행한다.
optimizer.step() 명령에 의해 스텝벼로 연산을 진행한다.
model.evaluate() 명령을 사용하여 정밀도를 출력한다.
| 6 | n_epochs = 10 for epoch in range(n_epochs): model.train() for X_batch, y_batch in loader: y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) optimizer.zero_grad() loss.backward() optimizer.step() # Validation model.eval() y_pred = model(X_test) acc = (torch.argmax(y_pred, 1) == y_test).float().mean() print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100)) |
은닉층이 없는 Simple Network를 사용한 정밀도는 92.6% 가 상한이다.
| 7 | Epoch 0: model accuracy 84.46% Epoch 1: model accuracy 88.37% Epoch 2: model accuracy 89.58% Epoch 3: model accuracy 90.28% Epoch 4: model accuracy 90.60% Epoch 5: model accuracy 91.10% Epoch 6: model accuracy 91.49% Epoch 7: model accuracy 91.86% Epoch 8: model accuracy 92.19% Epoch 9: model accuracy 92.33% |
PyTorch class CNN
transforms.Compose 명령에 의해 일단 입력 데이터를 Tensor 이미지로 변환 후 평균이 0.0 이고 표준편차가 128 인 조건 하에서 정규화를 시킨다.
batch_size 가 100 인 학습 데이터와 검증용 데이터를 준비한다.
| 8 | # Simple CNN: Load MNIST data transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0,), (128,)), ]) train = torchvision.datasets.MNIST('data', train=True, download=True, transform=transform) test = torchvision.datasets.MNIST('data', train=False, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(train, shuffle=True, batch_size=100) testloader = torch.utils.data.DataLoader(test, shuffle=True, batch_size=100) |
class nn.Module을 인수로 받아 들이는 class CNN 을 선언하자.
메서드 init 에서 self 변수들을 설정하여 초기화하도록 하자. 인수로 받는 nn.Module을 super__init__() 으로 초기화 한다.
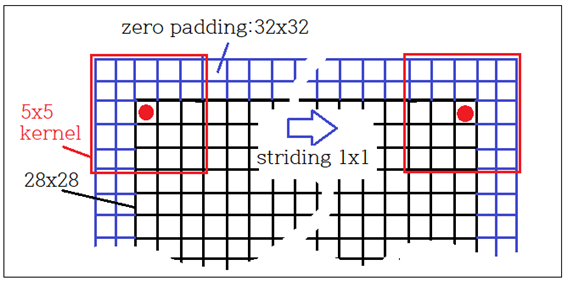
⓵ Conv2d( 1, 10, ⦁⦁⦁) 에서 양쪽으로 2개씩 0.0 으로 padding 하면 grayscale 이미지 ( ?, 28, 28, 1) 으로부터 10개의 특징 맵 ( ?, 32, 32, 10)을 얻을수 있다. 5x5 커늘을 사용, stride 는 1x1 을 적용하면 ( ?, 28,28, 10) 이 얻어진다.
⓶ ReLU 처리 시 shape 변화는 없다.
⓷ 커늘 사이즈 2x2 에 stride=1 로 하여 Pool 처리하면 (?, 27, 27, 10) 을 얻는다.
⓸ Dropout(0.2) 는 overfitting을 방지하기 위해 무작위로 20% 네트워크를 끊어 버린다.
⓹ Flatten()에 의해 (?, 27, 27, 10) 을 (?, 27*27*10) 으로 shape을 바꾼다.
⓺ 완전연결계층 처리를 위해 Linear 명령을 사용 27*27*10개에서 128개로 수를 줄인다.
⓻ shape 변화가 없는 ReLU 처리를 한다.
⓼ Linear 명령을 사용 128개에서 128개로 식별을 위한 class 수인 10으로 수를 줄인다.
| 9 | class CNN(nn.Module): def __init__(self): super().__init__() self.conv = nn.Conv2d(1, 10, kernel_size=5, stride=1, padding=2) self.relu1 = nn.ReLU() self.pool = nn.MaxPool2d(kernel_size=2, stride=1) self.dropout = nn.Dropout(0.2) self.flat = nn.Flatten() self.fc = nn.Linear(27*27*10, 128) self.relu2 = nn.ReLU() self.output = nn.Linear(128, 10) |
self 변수들과 입력 데이터 x를 인수로 받아 순전파 연산을 위한 메서드 forward 를 선언한다.
앞서 초기화 과정에서 선언된 self 변수 명령들을 사용하여 순전파 연산이 이루어지며 최종 연산 결과 x를 instance 값으로 반환한다.
| 100 | def forward(self, x): x = self.relu1(self.conv(x)) x = self.pool(x) x = self.dropout(x) x = self.relu2(self.fc(self.flat(x))) x = self.output(x) return x |
class CNN을 불러 model 을 설정하자.
CNN에서 사용된 모든 가중치들을 의미하는 model_parameters()를 Adam optimizer 의 인수로 제공하고 Cross Entropy를 Loss 함수로 두자.
| 11 | model = CNN() optimizer = optim.Adam(model.parameters()) loss_fn = nn.CrossEntropyLoss()사용 27*27*10개에서 128개로 수를 줄인다. |
⓵ epoch를 10회로 설정한다.
⓶ 각 epoch 별로 model을 한번씩 학습(train)하고 평가(evaluate)가 이루어진다. 즉 하나의 epoch 가 완료되면 그때의 가중치를 초기값으로 둔 상태에서 다시 학습(train)과 평가(evaluate)가 이루어지게 된다. 따라서 epoch를 거듭할수록 정밀도가 좋아지게 된다.
⓷ Loss 함수 값은 X_batch 데이터를 사용한 순전파 연산된 결과인 y_pred 와 주어진 라벨값인 y_batch 와의 오차를 가지고 Cross Entropy 함수를 준비한다.
⓸ 단 매회의 epoch 에서 학습시 Shuffling 에 의한 데이터 준비가 이루어져 있으며, 단지 기울기 값은 0.0 으로 초기화 된다.
⓹ 역전파 연산을 실행한다.
⓺ optimizer 로 하여금 step 별로 가중치를 업데이트하여 학습을 진행한다.
| 12 | n_epochs = 10 for epoch in range(n_epochs): model.train() for X_batch, y_batch in trainloader: y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) optimizer.zero_grad() loss.backward() optimizer.step() |
아래와 같이 인식률이 얻어지지만 Conv2d 의 파라메터들이 최적화 되지 않았기 때문에 인식률이 그다지 높지는 않다.
| 13 | Epoch 0: model accuracy 76.12% Epoch 1: model accuracy 84.81% Epoch 2: model accuracy 87.05% Epoch 3: model accuracy 88.06% Epoch 4: model accuracy 88.79% Epoch 5: model accuracy 88.96% Epoch 6: model accuracy 89.51% Epoch 7: model accuracy 90.03% Epoch 8: model accuracy 90.34% Epoch 9: model accuracy 90.69% |
LeNet-5 코드를 살펴보자 . PyTorch class CNN 과 유사한 구조이지만 파라메터 설정에서 차이가 나며 보다 최적화 되어 있다.
① 첫 번째 Conv2d( 1, 6, ⦁⦁⦁) 에서 양쪽으로 2개씩 0.0 으로 padding 하면 grayscale 이미지 ( ?, 28, 28, 1) 으로부터 6개의 특징 맵 ( ?, 32, 32, 6) 이 얻어지는데, 5x5 커늘 사용, stride 는 1 을 적용하면 ( ?, 28, 28, 10) 이 얻어진다.
② 활성화 함수는 tanh을 사용한다. 1990년대에는 ReLU 가 사용되지 않았다.
③ 커늘 사이즈 2x2 에 stride=2 로 하여 AvgPool 처리하면 (?, 14, 14, 6) 을 얻는다.
④ 두 번째 Conv2d( 6, 16, ⦁⦁⦁) 에서 padding=0 이면 이미지 ( ?, 14, 14, 6) 으로부터 16개의 특징 맵 ( ?, 14, 14, 16) 이 얻어지는데, 커늘은 5x5 커늘 사용, stride 는 1 을 적용하면 ( ?, 10, 10, 16) 이 얻어진다.
⑤ 활성화 함수는 tanh을 사용한다. shape 에 변화가 없다.
⑥ 커늘 사이즈 2x2 에 stride=2 로 하여 AvgPool 처리하면 (?, 5, 5, 16) 을 얻는다.
⑦ 세 번째 Conv2d( 16, 120, ⦁⦁⦁) 에서 padding=0 이면 이미지 ( ?, 5, 5, 16) 으로부터 120개의 특징 맵 ( ?, 5 5, 120) 이 얻어지는데, 5x5 커늘 사용, stride 는 1 을 적용하여 AvgPooling 하면 ( ?, 1, 1, 120) 이 얻어진다.
⑧ 활성화 함수는 tanh을 사용한다. shape 에 변화가 없다.
⑨ 마지만 뉴럴 계층에서는 더 이상 AvgPool 적용이 없으며 Flatten 명령을 적용, shape(120,)를 가지는 결과물을 얻어낸다..
⑩ Linear 명령을 사용 120개에서 84개로 수를 줄인다.
⑪ 활성화 함수 tanh 을 적용한다. shape 에 변화가 없다.
⑫ Linear 명령을 사용 84개에서 MNIST class 수인 10개로 수를 줄인다.
| 14 | class LeNet5(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=2) self.act1 = nn.Tanh() self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2) self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0) self.act2 = nn.Tanh() self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2) self.conv3 = nn.Conv2d(16, 120, kernel_size=5, stride=1, padding=0) self.act3 = nn.Tanh() self.flat = nn.Flatten() self.fc1 = nn.Linear(1*1*120, 84) self.act4 = nn.Tanh() self.fc2 = nn.Linear(84, 10) |
self 변수들과 입력 데이터 x를 인수로 받아 순전파 연산을 위한 메서드 forward 를 선언한다.
앞서 초기화 과정에서 선언된 self 변수 명령들을 사용하여 순전파 연산이 이루어지며 최종 연산 결과 x를 instance 값으로 반환한다.
| 15 | def forward(self, x): x = self.act1(self.conv1(x)) # input 1x28x28, output 6x28x28 x = self.pool1(x) # input 6x28x28, output 6x14x14 x = self.act2(self.conv2(x)) # input 6x14x14, output 16x10x10 x = self.pool2(x) # input 16x10x10, output 16x5x5 x = self.act3(self.conv3(x)) # input 16x5x5, output 120x1x1 x = self.act4(self.fc1(self.flat(x))) # input 120x1x1, output 84 x = self.fc2(x) # input 84, output 10 return x |
이 class LeNet5()를 실행하기 위한 코드는 앞의 class CNN() 과 동일하므로 결과만 얻어보자. 상당히 높은 거의 98%에 육박하는 좋은 결과가 얻어졌다.
| 16 | Epoch 0: model accuracy 89.65% Epoch 1: model accuracy 92.86% Epoch 2: model accuracy 94.24% Epoch 3: model accuracy 95.72% Epoch 4: model accuracy 96.11% Epoch 5: model accuracy 96.34% Epoch 6: model accuracy 96.61% Epoch 7: model accuracy 96.83% Epoch 8: model accuracy 97.16% Epoch 9: model accuracy 97.18% |
참조: Handwritten Digit Recognition with LeNEt5 Model in PyTorch
이 참고 블로그에서 MNIST 데이터를 읽어 들이는 코드 한 줄에 고의적인 error 가 있을 수 있으므로 사용자가 알아서 수정하도록 하자.
https://machinelearningmastery.com/handwritten-digit-recognition-with-lenet5-model-in-pytorch/
첨부된 파일을 다운받아 Colab 에서 GPU 를 사용하여 실행해 보자.
'인공지능 응용 공학' 카테고리의 다른 글
| OpenCV 의 BGR, RGB, GRAY 및 Matplotlib 의 RGB format 비교 (0) | 2023.07.10 |
|---|---|
| 인공지능 발전사 (0) | 2023.06.29 |
| YOLO v3 meerkat 1 class Training (0) | 2023.06.27 |
| YOLO v3 3 Classes Custom Data Training: 오바마, 저커버그, 일런머스크 (0) | 2023.06.21 |
| 인공지능응용 공학∙ OpenCV 비전코딩 목차 pdf 파일 (0) | 2023.06.14 |