처음 입문하는 초보자에게는 인공지능 발전사 전체 요약 내용이 다소 익숙치 못해 이해하기 어렵다고 느낄 수 있으나 이어지는 각론에서 다룰 것이므로 완전히 이해하지 못해도 그다지 문제될 것이 없다.
지금도 인공지능의 핵심적인 분야를 차지하는 통계 확률적 분류 작업 즉 classification 알고리듬은 1901년 Pearson 교수의 PCA 기법에서 기원한다. PCA 기법은 Pearson 교수가 역학 전문가였던 동료로부터 Mohr’s Circle 이론을 참조하여 제시한 알고리듬이다.
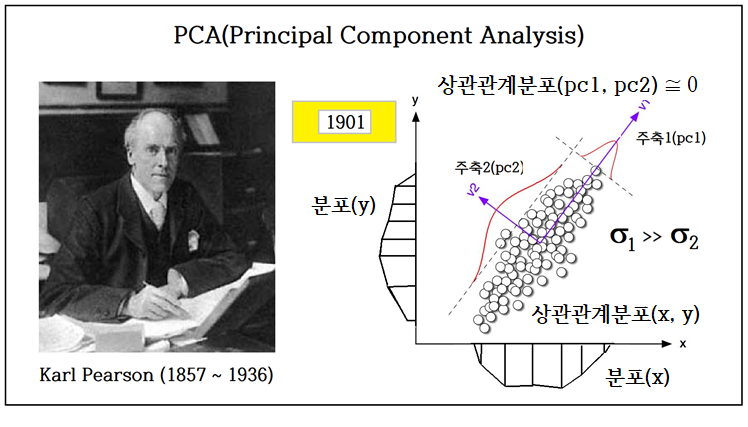
PCA 알고리듬에 이어 1936년 Fisher 교수의 iris flowers를 분류하기 위한 통계학 기반의 LDA (Linear Discriminant Analysis) 알고리듬이 출판되었다.
아래 2차원 좌표계에서 푸른색 점들과 붉은색 점들은 좌표계를 적절히 회전시킬 경우 projection2 에서 처럼 색상별로 분리가 가능한 상태를 얻을 수 있다. 이때의 좌표계 회전 각도를 Eigenvalue 분석에 의해 찾을 수 있다. Fisher 교수의 LDA 기법은 종류별로 50개로 이루어진 3종의 붓꽃 데이터를 분류할 수 있는 가장 뛰어난 통계적 기법이다.

아래의 예제에서 3종류의 Iris flowers 를 분류하기 위한 학습(training) 과 검증(validation) 으로 이루어진 통계학적 접근법을 실습해 보자.
참조: Scikit-learn 라이브러리 지원 Iris Flowers 예제
https://ejleep1.tistory.com/839
이 예제 실행을 위해서는 아나콘다 설치 시 향후 OpenCV 를 사용 Image Classification 머신러닝 코드 작성을 위한 가상환경 basic 에서 다음에 열거한 라이브러리를 설치(install)하자.:
⓵ python,
⓶ opencv-python,
⓷ scikit-learn,
④ pandas, ⑤ numpy, ⑥ matplotlib, ⑧ tensorflow, ⑨ keras,

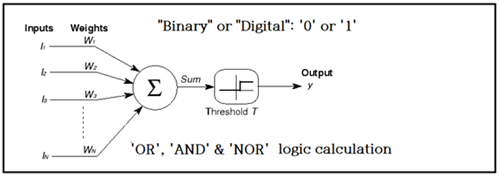
인공지능 발전사 연표를 보면 1943년 신경 병리학 의사였던 McCluch 과 기호 논리학자였던 Pitts 의 신경망 블록 다이아그램 및 로직 연산법을 다룬 논문 출판으로부터 시작되었다.
이들이 제안한 신경망 구조는 Cost 함수를 제외하곤 오늘날 우리가 사용하는 신경망과 동일함을 알 수 있다.
머신러닝에서는 카테고리 분류를 알아내기 위해 디지털이면서 확률적 특성으로 암호화된 One hot 코드를 사용한다. One hot 코드의 값을 더하면 “1.0”이 된다.
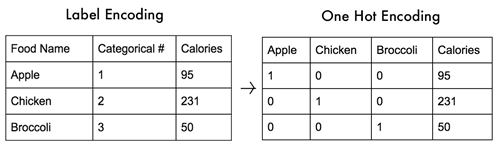
One hot 코드를 사용하는 머신러닝의 학습(train)과정은 Shannon 의 엔트로피(1948)를 최소화하는 즉 확률적 Uncertainty 를 최소화 시키는 과정에 해당하며 softmax 명령dp 의해 확률계산이 이루어진다. 통신의 시조라 할 수 있는 Shannon 이 머신러닝을 연구하지는 않았으나 샘플 데이터의 분류(classification)를 위해 One hot 코드를 적용함에 따라 자연스럽게 Shannon 의 엔트로피 최소화 기법이 도입되었다.

https://www.slideshare.net/bobcolner/a-brief-history-of-machine-learning
참조 : Rosenblatt's perceptron
https://jcblackmon.com/2018/01/08/rosenblatts-perceptron/
- 참조 영상 : Perceptron Applied to Images
- https://www.youtube.com/watch?v=cNxadbrN_aI
Rosenblatt 의 퍼셉트론 네트워크와 가중치 업데이트 알고리듬을 살펴보자.

아래 내용은 퍼셉트론을 창안한 Rosenblatt 박사의 1958년도 뉴욕 타임즈와의 신문 인터뷰 내용이다. 세계 최초의 머신러닝 시스템인 퍼셉트론을 만들어 발표한 Rosenblatt 박사가 아무리 장밋빛 환상에 빠져 있었다고 해도 1958년 당시 기준으로 앞으로 미래에는 말할 수도 있고 볼 수도 있고 쓸 수도 있는 머신러닝의 출현이 가능할지도 모르겠다는 언급은 불과 60년이 흐른 지금 2023년 모두 현실화되어 있음을 알 수 있다.

1959년 하버드 의대 실험실에서 후벨 박사와 그의 동료 뷔젤이 고양이 뇌의 시각피질에 전극을 설치하여 시신경(챇ㄷㅌ)을 통해 전달되는 자극 특성을 연구하였으며 이는 1980년대 초 노벨 의학상을 수상하는 계기가 되었다. 아울러 이 연구는 1998년 LeCUN 교수의 CNN (Convolutionary Neural Network) 발명의 과학적 기초가 되었다.

※ 참조: Deep Learning - STM 6 ( CNN 원리 뛰어난 해설 슬라이드 자료)
https://www.slideshare.net/Tricode/deep-learning-stm-6
1960년에 스탠포드대 Widrow 교수와 그의 박사과정이 최초로 Cost 함수 개념을 도입하였다. 수치해석에서 사용하는 뉴튼 랩슨 기법을 생각해 보자.

MIT에서 인공지능 실험실을 최초로 개설하여 로봇공학에서 많은 업적을 남겼던 Minsky 교수는 1969년 그의 저서 퍼셉트론에서 Rosenblatt 교수가 창안했던 퍼셉트론이 AND 와 OR 논리(logic)연산은 가능하지만 XOR 연산을 못한다는 악의적인 지적을 하므로서 인공지능 학계의 자해 행위를 하였다.

이로 인해 1970년대 Rosenblatt 교수의 사고사와 함께 국책 인공지능 연구비가 거의 10년에 걸쳐 100% 삭감되어 AI Winter 가 초래되었다. 인공지능에 관한 Minsky 교수의 연구실적을 추적해 보면 퍼셉트론이 XOR 연산을 못한다는 지적 외에 전무함을 알 수 있는데 이로 인해 결국 AI 학계의 최대 빌런으로 남게 되었다.

1960녀대의 퍼셉트론의 특징은 단일 레이어를 사용한다는 점인데 이러한 제약하에서는 XOR 문제를 처리하지 못할 수 있으나 은닉층(hidden layer) 를 포함하는 multi-layers 를 채택함에 따라 즉 딥러닝(Deep Learning)을 함에 따라 쉽게 해결이 되었다. 1980년대에 이르러서 멀티레이어 신경망 연산을 가능케하는 오차 역전파(Backpropagation) 알고리듬이 제안되어 딥러닝 신경망 문제가 풀렸다. 지금 AI 학계의 양대 축인 LeCUN 교수와 Hinton 교수를 들수 있는데 그 중 Hinton 교수가 박사과정이었던 때였다.

1990년대에 들어 인공지능 분야의 괄목할 만한 연구성과로는 자연어 및 시계열 분석 분야의 RNN (Recursive Neural Network)을 들 수 있다. 자연어처럼 시계열적 배열을 가지는 데이터의 특성상 다음 시계열 데이터의 예측을 위해 단적인 예로서 이어지는 말, 단어, 문장 조각 맞추기 학습을 생각해 볼 수 있다.
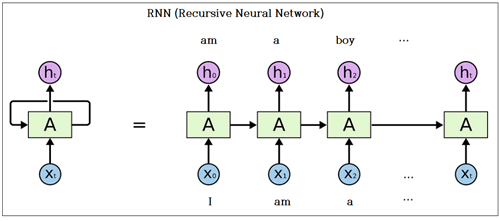
특히 긴 문장을 대상으로 하거나 맥락이 있는 대화 문제를 학습하기 위한 RNN 중에서도 문장 정보의 기억과 호출이 가능한 LSTM 알고리듬의 중요성이 부각되었다. 아래 개발 연표에 의하면 LSTM 연구의 중심무대는 유럽의 독일이었다. 이 LSTM 분야의 연구는 seq2seq 알고리듬을 근간으로 오늘날 구글의 ATTENTION 알고리듬과 TRANSFOMER 알고리듬으로 발전되었으며 이는 생성(Generative) 알고리듬 분야의 최대 성과로 보이는 초거대 AI 인 chatGPT 출현에 이르게 되었다.

1998년 LeCUN 교수의 리뷰 논문에서 수기문자 판독 처리를 위한 합성곱(CNN: Convilutionary Neural Network) 신경망 모델이 제안되어 지금의 Image Classification 의 토대를 제공하였다. LeCUN 교수의 CNN 의 기본 구조는 2012년 AlexNet 에 이르기까지 채용되고 있다.
CNN 은 convolution 필터링 및 활성화 함수 적용, 그리고 때때로 Pooling 작업에 의한 크기 축소로 이루어지며 마지막 단계에서 완전연결계층과 연결되어 마지막 단계에서 class 수 만큼으로 축소되어 softmax 적용에 의한 확률적 학습 처리가 이루어진다. CNN 의 이러한 기본적인 구조는 딥러닝 레이어의 길이가 늘어남에 따라 파라메터 수를 줄이기 위한 batch normalization 레이어가 추가되기도 한다.

다음 CNN 그림은 활성화 함수인 ReLU 와 이미지 크기를 줄이기 위한 Pooling 알고리듬 적용에 따른 중간 이미지 변화를 보여주는 다이아그램이다.

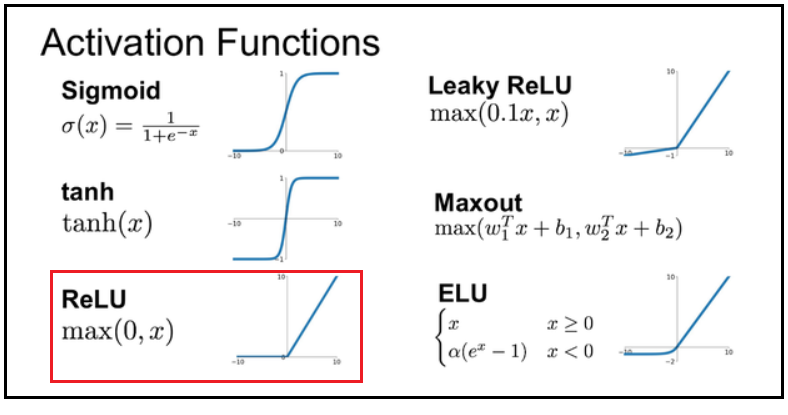
2000년 이전의 LSTM 알고리듬에서는 tanh 가 , 2014년 이후에 출현한 YOLO 에서는 Leaky ReLU 가 활성화 함수로 흔히 사용되었으며. 최근에는 Hinton 교수의 보급으로 주로 ReLU 가 사용된다. 특정한 활성화 함수의 채택 문제는 multi-layers 로 이루어진 딥러닝 신경망에서 레이어 별 기울기들의 곱 연산 결과가 폭발(explosion)해 버리거나 0 에 수렴해 버리는 문제 해결에 필수적임에 유의하자.
2012년 스탠포드 대학에서 만든 1000종의 사물 이미지 데이터세트인 ImageNet 의 image classification 알고리듬인 AlexNet GPU 연산 결과가 컨퍼런스에서 발표되었다.

2013년 AlexNet 보다 좀 더 복잡한 구조의 VGG-16 신경망이 93% 인식률로 제안되었다. 이 신경망은 GAN 신경망에 적용되기도 하였다.

2014년 구글이 제안한 Google 신경망으로서 93%의 인식률을 보여준다.

2012년 이후로 제안된 중요 신경망들의 특징을 살펴보면 학습과정에서 출현하는 파라메터 수가 관건임을 알 수 있다. 인식률을 높이려면 파라메터 수가 급증함을 알 수 있다. 따라서 파라메터 수를 줄이는 알고리듬 연구가 스탠포드 대학 중심으로
이루어진다. 대표적인 것이 SqueezeNet 이나 SSD 또는 MobileNet 들이 있다.


YOLO v3 의 신경망 구조는 수많은 Convolution 레이어와 파라메터 수를 줄이기 위한 ResNet 에서의 skip 레이어를 사용하지만 마지막 단의 완전연결 계층이 없다. Down sampling 작업을 통해 1차로 특징 맵을 추출 후 up sampling 작업이 이루어진다. Up sampling 단계에서는 down sampling 단계에서 잃어버리게 되는 정보를 저장해 두었다가 보충 작업을 실행하여 Up sampling 에서 완전한 이미지를 복구하도록 한다. Up sampling 단계별로 특징 맵을 2회 추출한다. 즉 대중소에 해당하는 3개의 특징 맵을 추출하여 이미지에 포함되어 있는 객체들을 크기에 따라 위치 인식까지도 가능하도록 한다.이처럼 이미지에 포함된 겍체들의 클라스와 위치까지 예측을 단순한 Image Classification 과 비교하여 객체탐지(Object Detection) 라고 하며, 자율주행을 구성하는 중요 요소로 등장했다.

최근의 Object Detection 분야의 알고리듬 개발 동향으로는 텍스트 데이터 입력을 중심으로 하는 Transformer 알고리듬에 이미지 CNN 데이터와 이미지에 포함된 객체의 위치 텍스트 데이터를 입력 가능하도록 하는 DETR 알고리듬이 Facebook AI 랩에서 제안하였다.
'인공지능 응용 공학' 카테고리의 다른 글
| 1990년대 말 CNN 응용의 길을 튼 LeCUN 교수의 LeNet-5 CNN 모델을 PyTorch 로 실습해보자. (0) | 2023.08.28 |
|---|---|
| OpenCV 의 BGR, RGB, GRAY 및 Matplotlib 의 RGB format 비교 (0) | 2023.07.10 |
| YOLO v3 meerkat 1 class Training (0) | 2023.06.27 |
| YOLO v3 3 Classes Custom Data Training: 오바마, 저커버그, 일런머스크 (0) | 2023.06.21 |
| 인공지능응용 공학∙ OpenCV 비전코딩 목차 pdf 파일 (0) | 2023.06.14 |