붓꽃 데이터세트
붓꽃은 setosa, versicolor, virginica 3 종류가 있으며 이들은 서로 다른 꽃받침(sepal) 크기와 꽃잎(petal) 크기를 특징(feature) 파라메터로 가진다.

Cost 함수가 사용되지 않는 퍼셉트론 학습은 epoch 별로 출력 값을 체크하여 정답에 도달하지 못했을 경우에 정답과 오답과의 차이 값에 대해서 작은 크기의 학습률을 곱해 업데이트하여 다음 epoch를 연산한다. 제어 공학에서 오차에 이득(gain)을 곱하여 피드백 해주는 기법과 유사하다. ※ 머신러닝에서 한 싸이클에 해당하는 학습을 생물 진화론에서 1세대에 해당하는 epoch 란 용어를 관행적으로 사용함에 유의하자.
붓꽃 분류문제는 농업 바이오 통계학 분야의 토대를 만들었고 다윈의 후계자로도 유명한 Ronald Fisher 교수가 1936년 Edgar Anderson 교수의 morphology 연구를 통해 얻어낸 인공지능(머신러닝) 초기 데이터세트로 이 세종류의 꽃들을 분류하기 위한 통계학적 LDA(linear discriminant analysis) 기법 적용에 사용되었다.
엑셀 csv 확장자 형태인 csv 파일로 제공되는 붓꽃 데이터세트를 pandas 라이브러리를 사용하여 읽어들이고, class 명령 형태로 작성된 퍼셉트론을 사용하여 붓꽃 데이터 세트(Iris dataset)를 종류별로 분류(classification) 해 보자.

pandas 라이브러리에 의한 붓꽃 데이터 읽기와 출력
pandas 는 엑셀 스프레드 시트 기능을 최대로 활용하는 라이브러리이다. 즉 엑셀로 헤더(header)를 넣고 row 단위로 column 별로 데이터를 입력하여 구성되는 데이터세트를 쉽게 다룰 수 있다.
iris.data를 서버에 보관하고 제공하는 서버 주소가 다양하게 있으며, 아래는 그중 하나다.
한편 실행 코드가 들어 있는 폴더에 iris.data 를 저장하고 불러 쓰는 사례이다.
| df = pd.read_csv('https://archive.ics.uci.edu/ml/' 'machine-learning-databases/iris/iris.data', header=None) df.tail() df = pd.read_csv('iris.data', header=None) df.tail() |
pandas 라이브러리를 사용 read_csv 명령으로 읽은 데이터를 iloc[⦁⦁⦁].values 명령으로 출력해 보자. iloc 은 정수형(integer) 위치(location)을 의미하며 values 는 숫자 값 자체를 의미하되 출력은 반드시 ndarray 형태인 즉 array([ num1, num2, ⦁⦁⦁]) 가 된다.
numpy.where 명령은 조건에 해당하는 y == 'Iris-setosa' 즉 y 값이 문자열 'Iris-setosa' 에 해당하면 불리언 값이 참(True) 이 되며,‘-1’값을. 반면 거짓(False) 이면 ‘+1’을 부여한다.
결과 출력은 ndarray 형태이다.
| # select setosa and versicolor y = df.iloc[0:100, 4].values y = np.where(y == 'Iris-setosa', -1, +1) # seosa 는 ‘-1’, versicolor는 ‘+1’ |
아래의 문제를 실습해 보자.
| a = np.arange(10) print(a) np.where(a < 5, a, 10*a) print(a) print(np.where(a < 5, a, 10*a)) """ [0 1 2 3 4 5 6 7 8 9] # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) 와 동일한 결과임 [ 0 1 2 3 4 50 60 70 80 90] """ |
퍼셉트론 알고리듬에 의한 학습
Fisher 교수가 제안한 통계학적 접근법인 LDA 도 중요하지만 인공지능 전체 역사를 볼 때에 더욱 중요한 역할을 담당했던 퍼셉트론 알고리듬으로 붓꽃 문제를 다루어 보자.
아래는 퍼셉트론 클라스 코딩에 나타나는 중요 인수들에 대한 설명이다.
| 1 | """Perceptron classifier‘s Parameters eta : 학습율, Learning rate (between 0.0 and 1.0) n_iter : 학습횟수 random_state : 랜덤 가중치 초기화를 위한 난수 생성 seed Attributes w_ : 1차원 어레이 형태의 가중치 errors_ : 리스트 데이터, 각 epoch 별 잘못 분류된 샘플 수 """Fit training data. Parameters ---------- X : {array-like}, shape = [n_samples, n_features] 붓꽃 데이터세트는 3종류로 각 50개의 데이터들로 구성 y : array-like, shape = [n_samples], Target values. 각 샘플별로 1, 2, 3 또는 virginica, self : object """ |
퍼셉트론 클라스 코드의 구조.
⓵ 퍼셉트론 클라스에 필요한 기본적인 파라메터로서 3가지 즉 learning rate, 학습 횟수 및 랜덤 수 생성을 위한 seed 를 준비하자. 동일한 랜덤 seed를 적용하면 항상 같은 결과를 얻을 수 있다.
class 코드에 처음에 eta 값이 0.01 로 지정되어 있지만 메인 코드에서 instance 값으로 0.1 을 부여하게 되면 부여된 일회용 instance 에 맞춰 class 내 self에 의해서 self.eta 값이 0.1로 변환된다.
마찬가지로 학습 횟수에 해당하는 n_iter를 class 코드에 처음에는 50 으로 설정해 두었지만 instance 값으로 클라스 명령을 호출하는 메인 코드에서 10의 값을 주면 self에 의해서 self.n_iter 값이 10으로 변환된다.
seed 값을 예를 두어 1 로 두면 이 값이 바뀌지 않는 한 항상 동일한 랜덤수를 생성하여 연산하므로 동일한 결과를 얻어 볼 수 있다.
⓶ 퍼셉트론 클라스에서 필요한 속성(Attribute)으로서 입력 벡터 성분 웨이팅을 위한 1차원 어레이 w_ 와 지정된 학습 횟수 내의 특정 에포크(epoch) 단계에서 전체 샘플들을 대상으로 생성되는 0.0 이 아닌 업데이트 값들을 합산하여 저장해 둘 리스트 데이터 즉 errors_를 1개 준비한다.
※ under bar “_”를 변수명에 사용하는 목적은 만약에라도 w를 사용하는 여타 변수와 중복을 피하기 위한 아이디어로 볼 수 있다.
이 코드에서 보고자 하는 중점 사항은 얼마나 빨리 업데이트(update) 값들의 합이 0.0 에 수렴하느냐는 것이다. 대체로 3∼6회에 0.0에 도달한다.
errors += int(update != 0.0)
연산된 업데이트 값의 정수값을 취하는데 이를 실수형(float) 으로 바꿔도 큰 변화는 없다.
※ 벡터 내적 연산 NumPy 명령 dot
3차원 numpy 어레이 벡터 v1
스칼라 값 0.5 를 곱하면 크기는 0.5배이며 방향은 동일
따라서 벡터의 내적을 계산 시 두 벡터가 이루는 각은 0 라디안이므로 코사인 값은 1.0
코사인 1.0 의 역함수를 계산하면 0.0 rad 이 출력된다.
| v1 = np.array([1, 2, 3]) v2 = 0.5 * v1 np.arccos(v1.dot(v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))) == 0.0 |
⓷ 아래에 퍼셉트론 class 파이선 코드를 참조하자.
3종류의 붓꽃 분류 문제에서 2종류의 붓꽃 데이터 50개씩을 선택적으로 취하여 4개로 이루어진 각각의 column 에서 2개만을 최종적으로 골라서 작도해 보자.
| # select setosa and versicolor X = df.iloc[0:100, [0,2].values # setosa 와 versicolor column을 선택 출력 |
2개의 column 데이터로 이루어진 X 를 사용하여 matplotlib 로 작도해 보면 직관적으로 2개의 영역으로 나뉘어지는 아래의 결과를 얻을 수 있다.

일반적으로 같은 종류라면 오른쪽 그래프에서처럼 중심점을 계산하여 대체할 수 있을 것이다. 중심점을 계산하기 위해서는 단순한 가중 평균을 사용하거나 또는 K means 기법을 사용할 수도 있을 것이다. 즉 직관적으로도 그을 수 있는 구분선을 퍼셉트론으로 정밀하게 계산하여 이를 decision boundary 또는 hyperplane 이라고 한다.
hyperplane 인 y = wx + b 의 가중치 w 와 바이어스 b를 결정할 수 있다면 2종류의 붓꽃을 분류할 수 있게 된다. 여기서는 각 샘플들의 중심점을 사용하여 그 조건을 간단하게 부등식으로 표현이 가능하다.
한편 Rosenblatt 의 퍼셉트론 알고리듬에서는 50개씩의 데이터 각각에 대하여 랜덤한 초기 가중치를 설정하여 반복 업데이트(update) 연산에 의해서 최종 가중치를 찾아내게 된다.
아래의 클라스 Perceptron 코드 내의 update 업데이트 연산을 중심으로 퍼셉트론의 알고리듬을 살펴보자.
- zip(X, y)은 튜플 데이터 즉 xi 와 target 을 반환한다. xi 와 target 에는 2종류의 붓꽃 데이터가 50개 플러스 50개 합 100개
가 각각 포함되어 있다.
※ 클라스 내에서 메서드를 불러 사용하기 위해서는 self.+메서드명 임에 유의하자.
- 메서드 self.predict(xi) 를 호출하면 메서드 net_input에서 2개의 원소를 가지는 리스트 데이터 xi를 인수 X 로 받아서
np.dot(X, self.w_[1:]) + self.w_[0]을 연산하여 반환한다.
※ self.w_[1:] 은 2번째 원소로부터 끝까지 이므로 2개의 가중치 성분 self.w_[1] 과 self.w_[2]를 뜻한다.
즉 붓꽃 샘플 중 하나의 (target – self.predict(xi)) 값 즉 오차를 계산하면 0.0, 1, 또는 –1 셋 중에 하나의 값을 가진다. 아주 작은 값 self.eta 를 곱해 역시 작은 값 값을 가지는 update 값을 얻는다.
일종의 fedback 제어값으로 볼 수 있는 update 값을 사용하여 입력으로 볼 수 있는 xi 와 곱해 새로이 가중치 self.w_[1:] 과 self.w_[0] 을 얻는다.
한편 update 값이 0.0 이 아니라면 소숫점 이하를 버리고 정수화하여 errors 에 합산한다.
이 작업은 n_iter 한 번에 대해서 zip(X, y) loop에서 즉 100회씩 연산이 이루어지는데 실제 출력해 보면 대부분이 0에 해당한다.
- n_iter 한 번에 대해서 100회씩 연산 결과는 변수 errors_ 로 처리하여 리스트 데이터로 첨부 append 시킨다.
| ⦁⦁⦁ for xi, target in zip(X, y): update = self.eta * (target – self.predict(xi)) self.w_[1:] += update * xi self.w_[0] += update ⦁⦁⦁ errors += int(update != 0.0) self.errors_.append(errors) return self def net_input(self, X): return np.dot(X, self.w_[1:]) + self.w_[0] def predict(self, X): return np.where(self.net_input(X) >= 0.0, 1, -1) |
※ 100회 누적된 eta*(target – self.predict(xi)) 값 계산 결과가 대부분 아주 작으며, n_iter
값만큼 반복 연산해 보면 불과 n_iter = 6 이면 거의 0.0 에 도달한다. 즉 target 값
예측이 가능할 정도로 50개씩의 데이터들에 해당하는 가중치 값을 찾아내었음을 뜻한다.
아래 그래프의 결과를 참조하자.

퍼셉트론 알고리듬 다이아그램
이 과정을 아래와 같이 뉴론의 Perceptron algorithm 으로 요약하면서 가중치가 무엇인지 생각해 보자.

클라스 perceptron 명령을 사용하기 위해서 다음과 같이 인수 etha 와 n_iter 값을 설정한다.
퍼셉트론 학습은 클라스인 ppt를 상속하여 학습을 위한 메서드인 fit을 사용한다. 이때 샘플 데이터 X 와 target y 를 입력한다. 아울러 ppn.errors_를 반환받을 수 있다.
| ppn = Perceptron(eta=0.1, n_iter=10) ppn.fit(X, y) plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o') plt.xlabel('Epochs') plt.ylabel('Number of updates') plt.show() |
⓸ class Perceptron(object) 의 코드 상 위치는 필요로 하는 라이브러리 모듈들을 import 한 다음이 헤더 영역이 좋을 것이다.
Pandas 라이브러리 사용 데이터 읽기와 출력
⓹지정된 서버 주소로부터 저장되어 있는 Iris data 세트를 읽어오자. 이 명령들이 셸(Shell)에서 실행되면 df.tail() 명령에 의해 끝 자락의 몇 줄 데이터를 출력해 주지만 파이선 편집기 내부 코드로 실행되면 df.tail() 결과를 볼 수 없음에 유의하자. 아무런 출력이 없다는 것은 제대로 실행이 잘된다는 의미이다.
df = pd.read_csv('https://archive.ics.uci.edu/ml/'machine-learning-databases/iris/iris.data', header=None)
df.tail()
⓺ 다시 한번 데이터를 읽어 오는 작업인데 이 내용은 현재 실행하는 파이선 코드 저장 위치와 읽어 온 Irsis-flower data set 저장 위치를 동일하게 해주는 역할이다.
df = pd.read_csv('iris.data', header=None)
df.tail()
⓻ 머신 러닝 작업을 하기 전에 Iris 데이터를 작도해 보자.
setosa 와 versicolor 2 종류의 붓꽃 데이터를 불러오자.
df.iloc[0:100, 4].values 는 150개로 구성되는 Iris 데이터에서 0번에서 99번까지 100개의 데이터 중 마지막 4번째 줄 데이타를 불러와 출력한다는 뜻이다.
Iris data 는 꽃 하나 당 0∼3번에 해당하는 4개의 실수형 숫자 데이터와 마지막 4번에 해당하는 문자열 꽃 이름으로 구성된다. 4개의 실수 데이터는 각각 꽃받침 길이와 폭 그리고 꽃잎의 길이와 폭 데이터로 구성된다.
불려온 데이터는 np.where() 명령에 의해서 ‘Iris-setosa’인지 확인 후 사실이면 라벨 값 –1을 부여하고 아니면 +1 값을 부여한다. 50개만 Iris-setosa 이므로 –1 데이터 및 +1 데이터가 각각 50개씩 생성된다.
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
⓼꽃받침과 꼬치잎의 길이 데이터만 가지고도 setosa 와 versicolor 종을 쉽게 구별할 수 있으므로 이 2종류의 데이터를 가지고 입력 벡터 데이터들의 샘플을 준비하자.
#extract sepal(꽃받침) length and petal(꽃잎) length
X = df.iloc[0:100, [0, 2]].values
⓽ 2종류의 붓꽃 데이터를 가로축은 꽃받침 길이 세로축은 꽃잎 길이로 하여 작도하자.
오차 최소화를 위한 학습 횟수
⓾ 2개의 좌표 즉 (꽃받침 길이, 꽃잎 길이)로 구성되는 붓꽃 데이터를 학습 시키자. 즉 이 좌표 데이터에 원래 데이터에서 매겨져 있던 타겟 라벨값 “+1” 또는 “-1” 이 되도록 지속적으로 웨이트 값을 업데이트하자. 각 데이터 합(∑,시그마)을 계산하여 그 부호가 +이면 “+1” 값을 – 이면 “-1” 값을 부여하는데 타겟 라벨 값과 같아지면 더 이상 업데이트 할 필요가 없으며 그 데이터는 학습이 끝난 것이다. 즉 그 데이터의 적절한 웨이트 값이 선정된 것이다.
대부분의 데이터들이 1∼2회에 학습이 완료되며 나머지 아주 소수의 데이터들이 3∼5회면 거의 끝난다.
ppn = Perceptron(eta=0.1, n_iter=10) ( learning rate = 0.1, 학습횟수를 10으로 하여 class Perceptron 실행에 의해 instance ppn을 생성한다)
ppn.fit(X, y) (입력 벡터 X 와 타겟 라벨 값 y를 사용하여 class perceptron 내부의 fit 함수에 의해서 학습을 시킨다)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o') ( 에러의 합을 계산해 두었다가 학습횟수 증가에 해당하는 에포크(epoch) 별로 그 값을 그래프로 출력한다)
plt.xlabel('Epochs')
plt.ylabel('Number of updates')
plt.show()
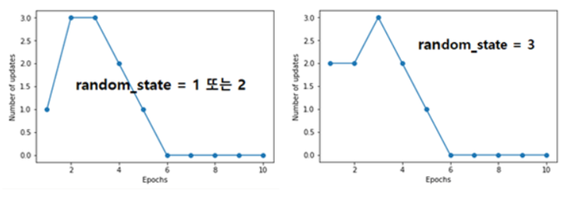
랜덤 수의 초기 값에 해당하는 random_state 값이 1 또는 2일 때와 3일 때의 두가지 경우가 출력되는데 워낙 간단한 문제라 계속 바꿔 봐도 둘 중의 하나가 출력된다. 5회까지 웨이트를 업데이트 하면 100개의 데이터 학습이 완료됨을 알 수 있다.
여기까지가 위 스캐터 플롯에서 보듯이 두 무더기로 이루어지는 Iris flower data set 100개를 대상으로 한 학습 과정이라면 두 무더기 데이터들을 구별할 수 있도록 쉽게 직선을 그을 수 있으며 이러한 특성을 “선형적으로 구분 가능하다“ 또는 ”linearly separable“하다고 정의 한다.
선형 구분선은 임의로 보고 긋는 것이 아니며 설정된 가로축과 세로축 공간에서 범위를 정해 바둑판 처럼 눈금을 생성하면 눈금 좌표들이 생성되는데 이 좌표들을 일일이 학습시켜야 할 필요가 있다. 즉 학습이 되면 전체 눈금들에 대해 “+1” 인지 “-1”인지 라벨 값이 결정이 되는데 이 값들을 이용하여 contour를 작도하면 contour 레벨 값에 해당하게 되는 색상 속성이 부여된 라벨 값들이 딱 2가지뿐이므로 색상이 불연속적이 되는 경계선을 시각적으로 볼 수 있으며 이 경계선을 decision boundary 라고 한다.
붓꽃 데이터세트퍼셉트론에 의한 학습 결과
⑪ decision boundary를 작도하기 위한 함수를 구성해 보자. X 는 입력 벡터이며 y는 입력 벡터에 대응하는 라벨 값이다. classifier는 미리 앞에서 선언해둔 class Perceptron을 불러필요 시 instance를 생성한다. 해상도는 눈금 데이터 생성 시 해상도 간격을 뜻한다. 다음 그림에서 보면 해상도 간격이 커질수록 decision boundary 가 엉성해 짐을 볼 수 있다.

과제
데이터 0, 1, 2, 3 중 0, 2 번 특징 데이터가 아닌 데이터 2개를 선택하여 classification 작업을 해보도록 하자.
Decision boundary 작도를 위한 클라스 명령 plot_decision_regions 코드 구조
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))]) ( unique(y) 값이 “+1” 과
“-1” 두가지이므로 ‘red’ 와 ‘blue’ 색상만 컬러맵 작성에 사용된다.
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 (가로축 데이터 범위에
각각 1만큼씩 양쪽으로 여유를 준다)
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 (세로축 데이터 범위에
각각 1만큼씩 아래 위 양쪽으로 여유를 준다)
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
앞서 설정한 범위 내에서 해상도를 0.02 단위로 하여 세밀한 눈금 좌표를 생성한다.
눈금 좌표들은 가로축 xx1 좌표 어레이와 세로축 xx2 좌표 어레이의 합성으로 구성되며
이들을 뜯어내 각각 한 줄짜리 어레이로 구성( flatenning process) 후 Transpose 형태를 취하자. 이어서 class Perceptron을 의미하는 classifier를 불러 instance를 생성시키는 과정에서 눈금 데이터 xx1과 xx2 를 사용하여 클라스 내부에 정의된 함수 predict를 불러 학습을 시킨다.
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape ) (가로축 1차원 데이터 어레이 xx1.shape 하나만을 reshape
하면 원래대로 원상 복구된다.)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap) ( 학습된 Z는 색상 레벨 값 데이터 를 가지고 있어 레벨 별 컬러로 표현이 된다. alpha는 색상의 진한 정도dlek.)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
decison boundary 로 분할되는 영역 설정 및 contour 작도를 위한 함수가 설정되었으면 눈금 데이터 contour 색상 작도에 중첩하여 matplotlib 라이브러리 모듈 명령을 사용하여 Iris flower data set을 scatter 형으로 함께 작도 하자.
#plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=cl,
edgecolor='black')
이어서 decision boundary를 포함하는 각 영역을 색상을 부여하여 작도한다.
plot_decision_regions(X, y, classifier=ppn)
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()
이 코드 전체를 실행하면 Rosenblatt이 뉴론에 대해서 관찰하고 모델링했던 방식으로 입력 벡터들의 웨이팅 된 합(∑,시그마)을 계산 후 웨이트 업데이터 과정에 따라 학습을 완료하여 선형적으로 구분 가능한 decision bounday를 포함한 공간을 컬러풀하게 시각화하여 보여주게 된다.
아래의 파이선 코드를 다운 받아 윈도우즈 10 아나콘다 스파이더에서 실행해 보자.
#Perceptron.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
class Perceptron(object):
def __init__(self, eta=0.01, n_iter=50, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
# 모든 self.w_ 즉 모든 w_[1:] 와 self.w_[0] 는 랜덤 수로 초기화
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
idx = 0
for xi, target in zip(X, y):
#idx = idx + 1
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
#print('idx :', idx, 'xi :', xi, target, update, 'self.w_ :', self.w_[1:])
errors += int(update != 0.0)
print(errors)
self.errors_.append(errors)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.net_input(X) >= 0.0, 1, -1)
v1 = np.array([1, 2, 3])
v2 = 0.5 * v1
np.arccos(v1.dot(v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)))
# ### Reading-in the Iris data
#df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data', header=None)
#df.tail()
df = pd.read_csv('iris.data', header=None)
df.tail()
# ### Plotting the Iris data
# select setosa and versicolor
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
# extract sepal length and petal length
#X = df.iloc[0:100, [0, 2]].values
X = df.iloc[0:100, [0, 2]].values
# plot data
plt.scatter(X[:50, 0], X[:50, 1],
color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1],
color='blue', marker='x', label='versicolor')
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
# plt.savefig('images/02_06.png', dpi=300)
plt.show()
# ### Training the perceptron model
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X, y)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o')
plt.xlabel('Epochs')
plt.ylabel('Number of updates')
plt.show()
# ### A function for plotting decision regions
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=cl,
edgecolor='black')
plot_decision_regions(X, y, classifier=ppn)
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()
'Opencv' 카테고리의 다른 글
| tflite 사전학습 가중치를 사용한 OpenCV 이미지 분류 (0) | 2023.06.02 |
|---|---|
| Remake: HTML 계산기+ 시계 + OpenCV 웹캠 Flask 웹서버 (0) | 2022.06.11 |
| 라즈베리 파이 B/B+에 파이 카메라와 Stretch 버전에 Opencv3.3을 설치해 보자. (0) | 2021.07.11 |
| 9-5 Opencv에 의한 세균 이미지 RGB HUE 색상 필터링 처리 (0) | 2020.06.01 |
| Flask Opencv 웹캠에 의한 웹서버상에서 안면인식 (0) | 2020.05.02 |