컬러 색상의 227X227X3 이미지 입력으로 이루어지는 AlexNet의 아키텍츄어를 살펴보자. MAX POOL 알고리듬에 3X3 커늘에 스트라이딩 값 2를 적용하는 바 이는 오버래핑을 허용하는 알고리듬이다.
전체적으로 크기를 줄여나가는 Convolution 및 pooling 레이어들과 마지막 부분의 Fully Connected Layer 구조로 이루어짐을 알 수 있다.
그밖에 다층의 신경망 적용에 따른 큰 수의 생성 폭발 및 gradient 값의 굽속한 감쇠를 방지하기 위해서 활성화 함수 ReLU를 채택하고 batch normalization 기법에 의해서 컴퓨팅 부담을 최대로 낮춘 후 부족한 데이터를 인위적으로 늘리기 위한 data augmentation 알고리듬을 채택한다.
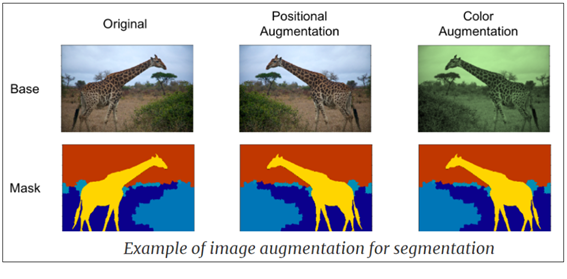
data augmentation은 아래 그림과 같이 제한된 수의 이미지 데이터로부터 기하학적인 대칭 조건들이나 색상 변화등을 적용하여 이미지를 뒤집든지, 회전시키든지 또는 잘라내든지 하여 이미지 데이터 수를 늘리는 기법으로 PyTorch를 비롯한 이미지 데이터 준비과정에서 흔히 이루어지는 작업을 뜻한다.
총 52,378,344개의 파라메터를 가지는 AlexNet 의 구체적인 아키텍처를 살펴보자.
Colab에서 사전학습된 AlexNet의 class 명령 alexnet(pretrained=True)를 사용해 리트리버 개를 분석해 보도록 하자.
전체적으로 크기를 줄여나가는 Convolution 및 pooling 레이어들과 마지막 부분의 Fully Connected Layer 구조로 이루어짐을 알 수 있다.
그밖에 다층의 신경망 적용에 따른 큰 수의 생성 폭발 및 gradient 값의 굽속한 감쇠를 방지하기 위해서 활성화 함수 ReLU를 채택하고 batch normalization 기법에 의해서 컴퓨팅 부담을 최대로 낮춘 후 부족한 데이터를 인위적으로 늘리기 위한 data augmentation 알고리듬을 채택한다.
data augmentation은 아래 그림과 같이 제한된 수의 이미지 데이터로부터 기하학적인 대칭 조건들이나 색상 변화등을 적용하여 이미지를 뒤집든지, 회전시키든지 또는 잘라내든지 하여 이미지 데이터 수를 늘리는 기법으로 PyTorch를 비롯한 이미지 데이터 준비과정에서 흔히 이루어지는 작업을 뜻한다.
총 52,378,344개의 파라메터를 가지는 AlexNet 의 구체적인 아키텍처를 살펴보자.

Colab에서 사전학습된 AlexNet의 class 명령 alexnet(pretrained=True)를 사용해 리트리버 개를 분석해 보도록 하자.
PyTorch 코드 실행을 위해서 torchvision을 설치하자.
| 1 | !pip install torchvision |
torchvision의 class 명령 models 를 불러오자. 이 부분은 Keras 와 거의 유사한 구조를 보여준다. Keras에서도 datasets, layers, models,losses를 불러 왔던 점을 생각해 보자. 즉 메타(전 페이스북) PyTorch 와 구글의 Keras가 비슷한 시기에 등장했던 것으로 보아 코딩 기법 내용도 유사한듯하다.
라이브러리 torch 와 torch.nn을 부른다. 텐서플로우의 tf와 tf.nn을 상기하자.
그래픽 지원을 위해 matplotlib.pyplot을 약어 plt로 둔다.
models를 출력해 보면 alexnet은 물론 수십종의 사전학습 이미지 네트워크를 지원하고 있음을 알 수 있다.
| 2 | from torchvision import models import torch ; import torch.nn ; import matplotlib.pyplot as plt dir(models) |
PyTorch 서버로부터 사전학습된 alexnet class를 불러ㄴ허고 츌력하면 AlexNet 의 신경망 구조를 보여준다.
| 3 | alexnet = models.alexnet(pretrained=True) #You will see a similar output as below #Downloading: "https://download.pytorch.org/models/alexnet-owt- 4df8aa71.pth" #to /home/hp/.cache/torch/checkpoints/alexnet-owt-4df8aa71.pth print(alexnet) |
torchvision 으로부터 라이브러리 transforms를 불러오자. 이 라이브러리는 image classification 작업에서 Crop 작업에 의해 적정 수만큼 이미지 수를 늘려주고 적당한 품질을 맞춰주는 augmentation 작업을 지원한다.
| 4 | from torchvision import transforms transform = transforms.Compose([ #[1] transforms.Resize(256), #[2] transforms.CenterCrop(224), #[3] transforms.ToTensor(), #[4] transforms.Normalize( #[5] mean=[0.485, 0.456, 0.406], #[6] std=[0.229, 0.224, 0.225] #[7] )]) |
구글 Colaboratory 좌측에 폴더를 클릭하면 화샇표 “↑” 기호가 들어 있는 업로드 아이콘을 볼 수 있다. 이 아이콘을 클릭하여 네 PC의 사용자 폴더 탐색기가 나타나면 미리 저장해 두었던 dog.jpg 그림 파일을 탐색하여 그림 파일을 NDRIVE 상의 sample_data 폴더 바로 밑에 직접 업로드 한 후 읽어서 이미지를 출력하도록 한다.
리트리버종 개 이미지를 출력해보자.
| 5 | # Import Pillow from PIL import Image img = Image.open("dog.jpg") plt.imshow(img) plt.show() |
 |
이미지를 resizing , croping 및 normalizing에 의해 torch텐서로 변형(transform)하고 shape을 출력해보면 [3, 224,224]임을 알 수 있다. Keras의 경우 (224,224,3)으로 출력된다.
여기에 unsqueeze 명령을 사용해 shape을 변경 증가시키도록 한다.
| 6 | img_t = transform(img) print(img_t.shape) batch_t = torch.unsqueeze(img_t, 0) print(batch_t.shape) |
torch.Size([3, 224, 224]) torch.Size([1, 3, 224, 224]) |
model.eval() 명령은 학습단계에서 overfitting 방지를 위해 적용했던 dropout 과 batch normalization 을 중지시킨 후 원래의 네트워크를 대상으로 테스트에 들어 가야 한다는 의미이다. 준비된 데이터 batch_t를 사용하여 alexnet을 실행하여 샘플 이미지 데이터의 label 값을 출력하도록 한다.
| 7 | alexnet.eval() out = alexnet(batch_t) print(out.shape) |
torch.Size([1, 1000]) |
웹 출력에 많이 사용하는 json format 데이터를 다운로드 받는다.
| 8 | import json from torchvision.datasets.utils import download_url download_url("https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json", ".", "imagenet_class_index.json") |
이미지 종류별 세부 라벨 값을 읽어 출력하자.
| 9 | with open("imagenet_class_index.json", 'r') as f: labels = json.load(f) print(labels) |
| '0': ['n01440764', 'tench'], '1': ['n01443537', 'goldfish'], '2': ['n01484850', ... |
인식률 순서대로 top10을 출력해보자.
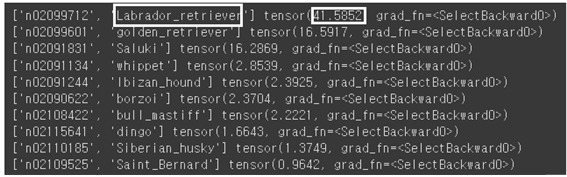
| 10 | #indices = out.argmax(dim=1) _, indices = torch.sort(out, descending=True) percentage = 100 * torch.nn.functional.softmax(out, dim=1)[0] for idx in indices[0][:10]: print(labels[str(idx.item())],percentage[idx.item()]) |
Labrador retriever가 가장 높은 확률인 41.5% 로 인식되었다.
첨부된 Colab 파일을 다운받아 실행해 보자.
'인공지능 응용 공학' 카테고리의 다른 글
| chatGPT로부터의 텐서플로우 선형회귀법 예제 (0) | 2023.01.28 |
|---|---|
| Colab에서 사전학습된 가중치를 사용 PyTorch에서 AlexNet을 실행해 보자. (2) | 2023.01.28 |
| AlexNet Architecture 요약 (1) | 2023.01.23 |
| Colab에서 CNN을 사용한 CIFAR10 이미지 인식 Keras 코드 작성 (0) | 2023.01.23 |
| Colab에서 CNN을 사용한 Keras MNIST 코드 작성 (0) | 2023.01.22 |