How to do Image Classification on custom Dataset using TensorFlow
Image classification is basically giving some images to the system that belongs to one of the fixed set of classes and then expect the…
medium.com
공기정화 식물이 싱싱한지 아니면 수분 부족으로 인해 시들시들해졌는지 스마트폰 사진촬영을 통해서 살펴보자. Capacitive 토양수분센서를 사용할 경우 80% 이상에서 임계조건에서 잎줄기들이 축 쳐지게 된다. 다음 사진에서 왼쪽은 수분 건조현상이 시각적으로 전날 밤 10시에 관찰된 이 후 12시간 경과 한 오전 10시의 이미지로서 전체 잎줄기들이 축 쳐진 상태이다. 오른 쪽 사진은 급수 후 3시간이 경과하여 어느 정도 회복 중인 상태로서 중앙의 잎줄기들은 빨리 회복이 되었으며 주변 잎줄기들이 아직 회복 중인 상태이다.

왼쪽 사진의 경우처럼 지나치게 시들기 이전 즉 어느 정도 시들기 시작하는 시점의 사진들을 사용하여 시든 사태를 학습하도록 한다. 다소 근접하여 사진을 찍되 반드시 잎줄기들이 쳐진 부분을 포함하도록 찍도록 한다.
준비된 이미지를 다음과 같이 구글 Colaboratory에서 사용할 수 있도록 첫 줄에 구글 드라이브 마운팅 명령을 실행한다. /content/drive/까지는 mandatory 로 요구된다. 실행 후 URL 안내가 나오면 클릭하여 그쪽 사이트에서 제공하는 상당히 긴 authorization 코드를 Cntr+C 로 복사하여 Cntr+V로 붙여 넣자.
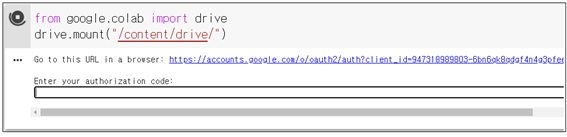

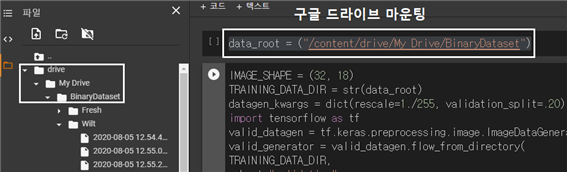
/content/drive/까지 구글 마운트 드라이브 즉 구글 탐색기 시스템이 설치되면 My Drive 폴더와 그 이하에 사용자가 지정하는 폴더들을 준비하도록 한다. My Drive 까지 mandatory 로 알고 있었으나 My Drive 사이의 블랭크로 인한 에러 메시지가 발생되므로 구글 마운트 작업에 주의하도록 한다. My Drive 폴 더 설정 및 그 산하의 즉 예를 들면 현재 다루는 예제에 있어서 BinaryDataset 폴더는 사용자가 명명한다.
여기에 Fresh 및 Wilt 폴더를 만들고 각각에 15매씩의 이미지를 업로딩 하여 저장하도록 한다. 이 업로딩 작업은 NDRIVE에서 직접 하면 더욱 편하다.
IMAGE_SHAPE 설정은 이미지 파일의 픽셀 해상도를 뜻하며 CNN 알고리듬 내에서는 컬러를 고려하여 3을 추가하게 된다.
데이터 생성을 위한 key word arguments(kwargs)를 준비한다. 많은 항목이 있지만 rescale 팩터와 전체 샘플수 대비 validation 용 샘플 수 비율을 설정하고 나머지느 ㄴDefault 로 잡힌다. 이들은 tf.keras.preprocessing.imageImageDataGenerator()에 **kwargs 표현을 사용하여 총괄적으로 arguments 공유가 이루어지며 flow_from_directory() 명령을 사용하여 구글 마운팅 된 폴더 내에서 학습(train)용 데이터와 검증(validatio)용 데이터가 구체적으로 준비된다.
Keraslens 코드에서 처리하는 해상도는 (18,32,3) 으로 처리하도록 한다. 아울러 디지털 필터의 수는 대체로 64개를 많이 사용하지만 컴퓨팅 부담을 줄여 보기 위해서 32 로 낮춰 보도록 한다. 아래의 계산 결과를 참조해 보도록 하자. 적은 수의 샘플 이미지를 사용하지만 100% 의 인식률을 확인할 수 있다. 요구되는 최소한도의 이미지 수가 5,000 개 수준이지만 어쨌든 적은 수의 이미지를 사용하여 100% 인식이 되므로 그대로 사용해도 될 것이다.

인식률 계산과 아울러 Cost 함수 및 Acuuracy 의 변동을 matplotlib를 사용하여 작도한다. 마지막으로 validation 용 데이터를 사용하여 라벨값을 적중 시킨 이미지는 녹색으로 출력하고 틀린 이미지는 빨간색으로 출력하도록 한다. 한편 머신 러닝에 실퍄한 사례도 나올 수 있는데 최종 확률을 출력해 보면 최대 확률 값이 0.5를 넘지 못하면서 분산되어 버린 경우로서 이때는 출력이 되지 않는다.
첨부된 Fresh_Wilt 코드는 구글 Colaboratory에서 GPU 지원 하에 실행하도록 하자. 수분 이내에 계산이 가능하다.
다음 사진은 수분 부족으로 축 쳐졌을 때와 급수 후 1시간이 경과하여 생기를 찾았을 때와의 차이를 보여준다. 즉 식물의 수분에 대한 반응을 시각적으로 충분히 볼 수 있음을 알 수 있다.

#FreshWilt.ipynb
data_root = ("/content/drive/My Drive/BinaryDataset")
#---------------------------------------------------------------------------------------
IMAGE_SHAPE = (32, 18)
TRAINING_DATA_DIR = str(data_root)
datagen_kwargs = dict(rescale=1./255, validation_split=.20)
import tensorflow as tf
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(**datagen_kwargs)
valid_generator = valid_datagen.flow_from_directory(
TRAINING_DATA_DIR,
subset="validation",
shuffle=True,
target_size=IMAGE_SHAPE
)
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(**datagen_kwargs)
train_generator = train_datagen.flow_from_directory(
TRAINING_DATA_DIR,subset="training",shuffle=True,
target_size=IMAGE_SHAPE
)
for image_batch, label_batch in train_generator:
break
image_batch.shape, label_batch.shape
for valid_image_batch, valid_label_batch in valid_generator:
break
valid_image_batch.shape, valid_label_batch.shape
label_batch[0:2]
print (train_generator.class_indices)
import matplotlib.pyplot as plt
plt.imshow(valid_image_batch[2])
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import Adam
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
model = Sequential([
Conv2D(32,(3,3),activation = 'relu',input_shape=(32, 18, 3)),
MaxPooling2D(2,2), Flatten(),
Dense(128,activation = 'relu'),
Dense(2, activation = 'softmax')
])
model.summary()
optimizer = Adam(lr=1e-3)
model.compile(
optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['acc'])
valid_image_batch.shape, valid_label_batch.shape
model.fit(
train_generator,
epochs=1,
validation_data=valid_generator)
#-----------------------------------------------------------
steps_per_epoch = np.ceil(train_generator.samples/train_generator.batch_size)
val_steps_per_epoch = np.ceil(valid_generator.samples/valid_generator.batch_size)
hist = model.fit(
train_generator,
epochs=100,
verbose=1,
steps_per_epoch=steps_per_epoch,
validation_data=valid_generator,
validation_steps=val_steps_per_epoch).history
#--------------------------------------------------------------------
final_loss, final_accuracy = model.evaluate(valid_generator, steps = val_steps_per_epoch)
print("Final loss: {:.2f}".format(final_loss))
print("Final accuracy: {:.2f}%".format(final_accuracy * 100))
#----------------------------------------------------------------------
import matplotlib.pyplot as plt
plt.figure()
plt.ylabel("Loss (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,50])
plt.plot(hist["loss"])
plt.plot(hist["val_loss"])
plt.figure()
plt.ylabel("Accuracy (training and validation)")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(hist["acc"])
plt.plot(hist["val_acc"])
val_image_batch, val_label_batch = next(iter(valid_generator))
true_label_ids = np.argmax(val_label_batch, axis=-1)
print("Validation batch shape:", val_image_batch.shape)
dataset_labels = sorted(train_generator.class_indices.items(), key=lambda pair:pair[1])
dataset_labels = np.array([key.title() for key, value in dataset_labels])
print(dataset_labels)
tf_model_predictions = model.predict(val_image_batch)
print("Prediction results shape:", tf_model_predictions.shape)
tf_model_predictions = model.predict(val_image_batch)
print("Prediction results shape:", tf_model_predictions.shape)
print(tf_model_predictions)
predicted_ids = np.argmax(tf_model_predictions, axis=-1)
predicted_labels = dataset_labels[predicted_ids]
print(predicted_labels)
plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range((len(predicted_labels)-2)):
plt.subplot(6,5,n+1)
plt.imshow(val_image_batch[n])
color = "green" if predicted_ids[n] == true_label_ids[n] else "red"
plt.title(predicted_labels[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (green: correct, red: incorrect)")
'머신러닝' 카테고리의 다른 글
| 머신러닝에의 초대 (0) | 2020.09.20 |
|---|---|
| TensorFlow Lite mnist.tflite 준비를 위한 Keras 예제 (0) | 2020.08.06 |
| 자동차 번호판 문자열 인식을 위한 Tesseract_OCTR 라이브러리 설치 (0) | 2020.08.06 |
| OpenCV 자동차 번호판 문자열 인식 (0) | 2020.08.01 |
| Keras 에 의한 CIFAR-10 구글 Colabo GPU 처리 (0) | 2020.06.09 |