참조: YOLO v3 anchors for traffic sign detection
anchors 값 설정 사례 - K means cluster
참조: How to perform object detection with YOLO v3 in Keras
https://machinelearningmastery.com/how-to-perform-object-detection-with-yolov3-in-keras/
code 사례
참조: YOLO v3: You Only Look Once - Real Time Object Detection
https://www.geeksforgeeks.org/yolo-you-only-look-once-real-time-object-detection/
Pc , Confidence Score 계산법 설명 포함
참조: YOLO for Object Detection, Architecture Explained!
RCNN을 중심으로 파생된 image classification 작업은 rjdml 2000개에 달하는 영역 제안 도출과 그 이후의 작업으로 2단 처리됨을 알 수 있다. 반면에 YOLO(You Only Look Once) 모델에서는 한 번에 처리하기 위해서 적절한 크기의 그리드 구성 환경에서 이미지 객체가 탐색되는 즉시 영역 제안 없이 직접 앵커박스 기법을 적용하여 이미지를 탐색하는 스피디한 기법을 제안하였다. 특히 YOLO 버전3 코드는 오픈소스로 공개되어 COCO 데이터 세트에서 사전학습된 결과를 사용하며 또는 필요시 사용자가 직접 학습시켜도 된다.
YOLO3 v3 코드의 실행 과정을 이해하기 위해서 darknet 폴더에 들어 있는 아래 3개의 코드를 살펴보자.
| yolov3.cfg, yolov3.py, image.py |
yolov3.cfg 즉 configuration 파일을 열어보면 다음과 같이 YOLOv3 의 architecture를 서술하는 텍스트 내용들이 들어 있다. 네트워크 전체의 기본적인 network 구조 설정인 [net] 와 이어지는 convolutional neural network 들이 서술된다.
이 내용을 yolov3.py 에서 함수 parse_cfg 를 사용하여 필요한 부분만 추려내도록 한다.
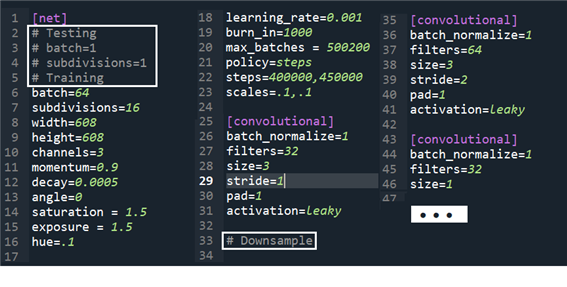
아울러 darknet 폴더에 포함되어 있는 yolov3.py 코드를 살펴보면 함수 parse_cfg(cfgfile) 과 YOLOv3Net(cfgfile, model_size, num_classes) 이 들어 있는데 YOLOv3Net 의 첫 줄에서 함수 parse_cfg를 사용하고 있음에 유의하자.
YOLOv3Net 은 cfgfile, model_size 및 num_classes 를 인수로 한다.
model_size 는 컬러 이미지로서 형상(shape) 이 (416, 416, 3) 이다.
YOLOv3 첫부분에서의 pase_cfg 작업내용을 살펴보자.
cfgfile을 열어서 읽어 들이되 New line ‘\n’ 및 ‘#’ 가 들어간 라인은 제거하여 전체를 하나의 리스트 데이터화 한다.
| def parse_cfg(cfgfile): with open(cfgfile, 'r') as file: lines = [line.rstrip('\n') for line in file if line != '\n' and line[0] != '#'] holder = {}; blocks = [] ⦁⦁⦁ return blocks def YOLOv3Net(cfgfile, model_size, num_classes): blocks = parse_cfg(cfgfile) ⦁⦁⦁ |
dictionary holder 와 리스트 blocks를 선언하자. 라인에서 첫 번째 문자가 브라켓 ‘[’ 이면 ‘type’ 단어와 라인의 두 번째부터 마지막까지(:-1) 내용을 까내어 합친다. rstrip() 은 알맹이만 뽑은 후 오른쪽 blank 를 제거한다.
첫 loop 에서 len(holder) 값은 0 이므로 blocks.append(holder)를 건너뛴 후 ‘=’ 을 중심으로 key 와 value 값을 나누어 저장한다.
key 의 오른쪽 blank를 제거하여 key 로 처리하고 value 의 왼쪽 blank를 제거하여 value 값으로 처리하여 dictionary item 화 시킨 후 holder 에 저장한다.
그 다음 loop 부터는 len(holder) 값이 더 이상 0 이 아니므로 리스트 blocks 에 key 와 value 로 이루어진 dictionary item 내용인 holder를 첨부(append) 시키고 다시 새로이 holder 를 선언한다.
loop 작업이 완료되면 마지막으로 holder 를 blocks 에 첨부(append)하고 반환한다.
| holder = {}; blocks = [] for line in lines: if line[0] == '[': line = 'type=' + line[1:-1].rstrip() if len(holder) != 0: blocks.append(holder) holder = {} key, value = line.split("=") holder[key.rstrip()] = value.lstrip() blocks.append(holder) return blocks |
아래는 함수 parse_cfg 에서 lines 의 각 line 별 처리 결과를 blocks 로 첨부한 결과를 보여준다. 전체를 감싸는 하나의 리스트 내에 여러 개의 key: value 들로 이루어진 dictionary 들의 집합이 내용물이 된다.

Tensorflow Keras 라이브러리 지원하에 이미지를 입력하고 정규화(normalization)를 실행한다.
아래는 blocks[0] 을 출력한 결과이다. 그 내용은 convolution 을 비롯한 딥러링 레이어 자체가 아니라 YOLO v3 를 규정하는 하이퍼 파라메터들에 해당한다.

blocks 는 type 별로 5 종류 즉 convolution, upsample, route, shorcut, yolo 들로 구성된다.
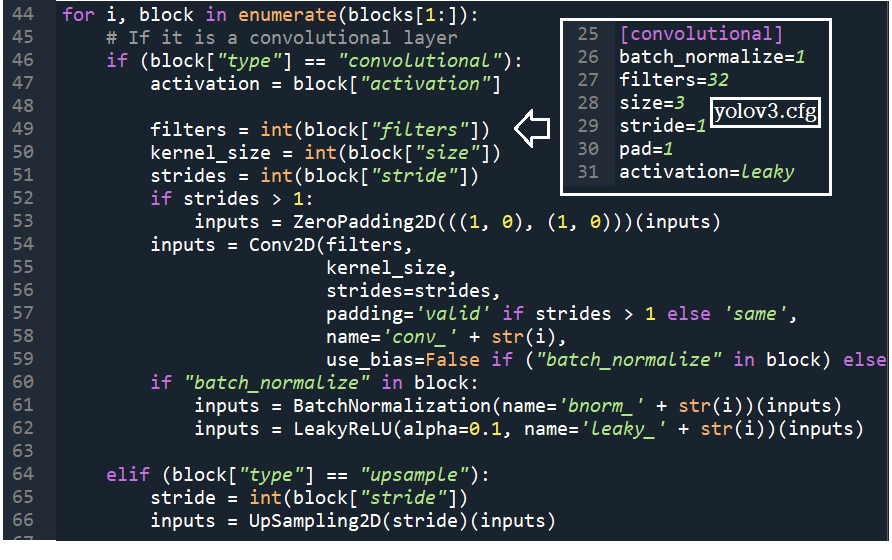
net 을 포함하는 blocks[0] 을 제외한 blocks[1:] 은 첫번째 부터 type 별로 해당 항목들이 있는지 조사해서 처리한다.
| ... inputs = input_image = Input(shape=model_size) inputs = inputs / 255.0 for i, block in enumerate(blocks[1:]): if (block["type"] == "convolutional"): ... elif (block["type"] == "upsample"): ... elif (block["type"] == "route"): ... elif block["type"] == "shortcut": ... elif block["type"] == "yolo": ... |
YOLO v3 에서는 batch normalization 레이어가 있는지 여부에 따라서 2종류의 75개 convolution 레이어가 있다.
batch normalization 레이어의 경우 LeakyReLU 활성화 함수를 사용한다. 그렇치 않은 경우에는 linear 를 사용한다.
아울러 strides 값이 1 이상이면 이미지 둘레에 0 값을 넣는 Zeropadding2D 명령을 실행한다.
[route] 레이어는 4회 출현하는데 첫번째 layers = - 4 는 4회 backward 를 의미한다. 두번째 layers = - 1, 61 은 앞 레이어와 61번째 레이어를 합치도록(concatenate) 하는데, 이는 이미지를 원상 복구해야 하는 업샘플링 과정에서 이미 소실되었던 정보를 앞 레이어로부터 보충함을 뜻한다.
[shortcut] 레이어는 23회 출현하는 바 from = -3 에서 즉 3회 backward 한 frature map 을 바로 앞 레이어에 합치도록 한다. 이는ResNet 에서 사용된 skip 구조로서 backpropagation 연산 과정을 단순화 시키면서 컴퓨팅 부담을 경감시키는 구조이다.
[yolo] 레이어는 3회 출현하는 바 객체를 탐지 및 bounding box 를 세분화 하는 역할을 한다.
YOLO 의 전체 레이어 작업에 의해서 최종적으로 13x13, 26x26, 52x52 크기 3종류의 특징 맵이 얻어진다.
즉 원래의 이미지를 사용 Down Sampling 이 진행되어 얻어지는 이미지는 원 이미지에서 많은 이미지 정보들이 소실되어 간신히 알아볼 수 있을 정도의 정보만 남은 이미지일 것이다. 26x26 이미지는 13X13 에서 Up Sampling 하여 구성하는 이미지이므로 많은 정보 손실로 인해 그 이미지가 흐려질 수도 있으나 한 참 전단계에서 보관 저장했던 정보를 리바이벌하여 concatenation 함으로써 보다 완벽하게 살려낼 수 있을 것이다. 52x52 이미지도 Up Sampling 하여 구성하는 이미지이므로 Down Sampling 단계에서 보관 저장했던 정보를 사용하여 concatenation 함으로써 마찬가지로 완벽하게 살려낼 수 있을 것이다.

자 그렇다면 이미지 학습 시에 제공되는 학습 데이터는 어떤 방식일까 알아보자. 아래의 그림들은 labelImg 를 사용하여 얻어낼 수 있는 학습용 이미지 처리 결과라 볼 수 있는 Ground Truth Data 이다. 해당 오브젝트 별로 사각형 Ground Truth 박스의 좌표는 labelImg 학습 데이터 준비단계에서 생성되는 txt 파일에 저장되어 있으므로 정확히 알 수 있다.

한편 SxS 그리 셀로 구성된 이미지의 각셀에서 중앙 점들에 해당하는 각각의 앵커점들에 대해서 3개의 축척비에 대한 총 9개의 앵커박스들을 고려한다. 즉 주어진 ground thruth 박스에 대해서 각 축척별로 SxS 그리드 셀의 중앙점에 대한 9개의 앵커박스들을 겹친 후 교집합 비율 즉 IoU(Intersection of Union) 값을 계산하자.

3개 축척별 이미지에 대해서 어느 하나는 아래 그림과 같이 IoU 값이 높은 비율을 유지하는 경우를 찾을 수 있을 것이다. IoU 값이 0.7 이상이면 찾은 셈이며 0.3 이하면 버리도록 한다. 하지만 경우에 따라서 0.7 이상을 찾을 수 없으 때는 IoU threshold = 0.5 를 적용하도록 한다.
※ 참고로 Faster R-CNN에서는 IOU threshold = 0.5 대신 highest 값을 사용하기도 한다.

특징 맵별 로 이미지 하나당 SxS 의 수에 해당하는 만큼의 그리드 셀 중심 즉 앵커 중심에 대응하여 3개씩 도합 9개씩의 앵커박스가 있으나 이를 아래의 통계 확률적 기법인 K-means 기법을 사용하여 변경해보자.
즉 학습 데이터 세트로부터 주어지는 혹은 얻을 수 있는 bbox 의 폭과 높이에 관한 통계적 분포도를 작성한 후 K-means 기법을 사용하여 이들을 그룹별로 나눠어 오른쪽에서 처럼 3개로 분류된 결과를 얻어낼 수 있다. 특히 각 그룹에서 K-means 의 중심값을 얻을 수 있으며 이를 학습을 통해 최종 bounding box 를 결정하기 위한 앵커박스의 초기 박스 크기 값으로 삼자.
실제 CoCo 데이터세트에 대해 작성된 YOLO v3 코드에서는 대중소 특징 맵 별로 3개씩 합계 9개의 초기화용 박스 크기값을 제공한다. CoCo 데이터세트 정도면 개인들이 준비하는 웬만한 학습 데이터세트 보다는 통계적 품질이 좋다고 볼 수 있을 것이다.

이 초기화 값들은 사용하는 데이터세트에 따라 별도로 계산하여 yolov3.py 코드에서 mask 값으로 제공할 필요가 있다.
이 초기화 값들을 416x416 을 대상으로 작도해 보면 아래 왼쪽과 같다. 오른쪽 object detection 결과와 비교해 보면 차이가 크다는 점을 느낄 수 있다. 즉 초기값으로부터 변동된 크기를 알아내야 한다는 점이다.

아래는 YOLO v3가 대중소 이미지 크기별로 읽어낸 mask 값들이며 9개에 해당한다. 이 값들은 Faster R-CNN 에서 인위적으로 사용하는 scale 및 aspect ratio 들의 1, 1.25, ... 들과는 당연히 다를수밖에 없다. 위 왼쪽 그림에서 작도된 결과를 살펴보자.

inputs 의 shape 을 리스트화 해서 출력해 보자.

n_anchors = 3, out_shape 의 [1] 과 [2] 를 사용하여 바로 앞에서 보여준 inputs.shape (None, 13, 13, 255) 를 아래와 같이 reshape 한다.
3x13x13 = 169x3 = 507, 80 + 5 = 85 --> 13x13x255 = 169x3x85 = 507x85
이 과정은 for loop 의 enumerate(blocks[1:]): 에서 13x13, 26x26, 52x52 애 대해서 reshape 작업이 이루어지게 된다.

inputs 의 (None, 507, 85) 에서 507 = 3x13x13 은 즉 SxS 그리드 중 가장 성긴 3x13x13 에 대하여 85개의 파라메터를 설정하자. 여기서 3x 는 컬러 이미지임을 뜻한다. 물론 26x26, 52x52 에 대해서도 동일하게 적용되어야 한다.
CoCo 데이터세트의 80개 class 와 앵커박스 파라메터 즉 폭w, 높이h, 중심점 x 좌표 와 y 좌표 및 confidence 5개로 이루어진다.
85개중 box_centers 는 [ :, :, 0:2] 이므로 0, 1 즉 할당된 2개 즉 앵커박스의 중심좌표를 나타낸다.
역시 2개가 할당된 box_shapes 는 [ :, :, 2:4] 이므로 2, 3 즉 폭과 높이에 해당한다 에 해당한다.
1개가 할당된 confidence 는 [ :, :, 4:5] 이므로 4, 즉 confidence 값에 해당한다.
- confidence score 는 앵커박스 중심점을 가지게 되는 SxS 그리드 셀 각각에 대해서 정의된다.
- 셀에 객체가 없으면 셀의 중심점을 공유하는 앵커박스도 객체가 없으므로 IOU = 0.0, confidence score = 0 이다.
- 반면에 셀에 객체가 있으면 앵커박스도 객체가 있으므로 IOU ≠ 0.0 이므로 confidence score = 1* IOU 로 정의 한다.
- '셀에 객체가 없으면'이라는 확률 조건은 P(object) = 0.0
- '셀에 객체가 있으면'이라는 확률 조건은 P(object) = 1.0
- 셀에 객체가 있는지 없는지 여부는 앵커박스와 ground truth box 와의 IOU 값이 threshold 이상이냐 이하로 결정하자.
- confidence score = P(object) * IOU 가 된다.
507, 2029, 8112 개의 그리드 셀에 대응하는 앵커박스들에 대해서 confidence threshold 가 0.5 이상이면서 가장 큰 IOU 값을 가지는 불과 몇개의 경우를 찾아내자. 특히 하나의 Object 에 대해서 2개 또는 3개의 GRID 가 반응을 보일 경우에는 NMS 알고리듬을 사용하여 걸러내자. 이 앵커박스들의 IOU 값이 1.0 아니므로 학습에 의해서 앵커박스의 중심점, 폭, 높이를 찾아내어 최종 confidence 를 계산한다.
YOLO v3 학습을 위한 Cost 함수를 살펴보자.
⓵ Regression loss 는 그리드 셀의 중심 점과 학습이 이루어지는 앵커박스의 중심점 사이의 offset 값,
ground truth box 의 폭 및 높이의 제곱근과 앵커박스 폭과 높이의 제곱근과의 offset 값으로 구성된다.
⓶ Confidence loss 는 초기값과 변동되는 중심점, 폭, 높이로부터 계산되는 IOU 값과 차이의 제곱항으로 구성하되 셀에 객체가 있는 경우뿐만 아니라 셀에 객체가 없는 경우도 포함한다.(?)
⓷ Classification loss 는 각각의 그리드 셀에 부여된 class 확률과 확률라벨 값과의 차이의 제곱을 최소화 하도록 한다.

학습을 위해서 4개의 파라메터들을 sigmoid 함수로 처리하면 결과 구간 [0, 1.0] 로 정규화 되는 효과를 준다.
각 셀당 9개인 앵커박스를 tile 명령을 사용하여 SxS 그리드 전체에 도배(tile)한다.

9개의 앵커박스를 tf.cast 명령을 사용하여 정수에서 실수로로 변환시켜, 엑스포넨셜 처리한 box_shapes 와 곱한다.

x축과 y축을 따라 각각 13개의 노드 점에 대한 메시를 생성하여 concatenation 에 의해 좌표를 생성 출력해 보자.
axis = -1 은 마지막 축을 나타내며 여기서는 axis = 1 을 의미한다.

cxy 를 [1, 3] 만큼 튀겨서 도배하자. 즉 row 방향으로 3배가 커지는데 이는 앵커박스가 3개씩임에 유의하자.
reshape에 관해서는 다음의 chatGPT 해설을 참조하자.

즉 '- 1' 은 앵커박스 수 3 에 해당함을 알 수 있다. 마지막 2 는 좌표 x 와 y 2개를 의미한다.
tuple 인 strides 를 계산하면 32, 16, 8 이 계산된다.
box_centers 에 cxy 를 더한 후 strides 를 곱하면 원 이미지 사이즈에 해당하는 box_centers 가 얻어진다.

scale = 0 이므로 결과들을 모두 concatenation 하되 axis=-1 으로 처리하자.
scale =0 이면 prediction.shape (None, 507, 85) 이며 else: 에서 concatenation 처리된다. 507 x 85
scale = 1 이면 prediction.shape (None, 2028, 85) 이며 if scale: 에서 처리. 3x26x26=2028
아울러 out_pred = tf.concat([out_pred, prediction], axis=1) = tf.concat([507, 2028],axis=1) => [2535]
scale = 1 이면 prediction.shape (None, 10647, 85) 이며 if scale: 에서 처리. 3x52x52=8112
아울러 out_pred = tf.concat([out_pred, prediction], axis=1) = tf.concat([2535, 8112],axis=1) => [10647]

블록별로 즉 인텍스 i 값에 대해서 if 문 처리가 완료되면 현재 상태의 inputs 를 output[i] 에 저장한다.
filters 는 append 시키도록 한다.
인덱스 i 가 전체 for looping 을 완료하면 input_image 와 out_pred 를 Model 의 인수로 주어 신경망 모델을 완성하여 model 로 두고 summary 보고서를 출력 후 준비된 model 을 반환한다.
텐서인 box(앵커박스) 의 center 값(Cell 의 중심, or 앵커박스의 중심)을 출력해 보자.


아래 블로그를 참조하여 Confidence 를 체크해보자.
YOLO: YOU ONLY LOOL ONCE - Real Time Object Detection
https://www.geeksforgeeks.org/yolo-you-only-look-once-real-time-object-detection/
keras 에서 Model 을 import 하자. main 에서 YOLOv3Net 를 부르면 결국 YOLOv3Net 애서 model = Model(...,...) 을 반환하므로 instance pred model 즉 Model 의 메서드인 다시말해서 keras 의 predict 를 사용할 수 있게 된다.

Keras 의 메서드 predict 를 사용하여 최종 객체의 score 확률, 박스의 위치, class 값을 얻어낸다.
utils.py 의 함수 out-boxes 를 사용하여 얻어진 걀과물 pred 를 입력 후 boxes, scores, classes, nums 를 뽑아낸다.
utils.py 의 함수 draw_outputs 를 사용하여 이미지 객체에 사각 표시와 score 확률값을 기입한 이미지를 출력한다.

참조: https://www.v7labs.com/blog/yolo-object-detection
참조: YOLO for Object Detection, Architecture Explained!
참고로 model.summary() 결과를 셸이 아닌 text 파일로 저장하는 기법
import sys
with open('model_summary.txt', 'w') as f:
original_stdout = sys.stdout
sys.stdout = f
model.summary()
sys.stdout = original_stdout
return model