
AI가 큰 발전을 했다고는 하지만 아직은 AI에 의한 그림 그리기 알고리듬들이 그다지 흔하지는 않아 보인다. 일반이 쉽게 찾아 볼 수 있는 자료가 바로 구글에서 제공하는 아래의 사이트일 것이다.
https://www.tensorflow.org/tutorials/generative/style_transfer?hl=ko
tf.keras를 사용한 Neural Style Transfer | TensorFlow Core
5월 11~12일 Google I/O에서 TensorFlow에 참여하세요. 지금 등록하세요. tf.keras를 사용한 Neural Style Transfer Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번
www.tensorflow.org
겉보기에는 굉장히 쉬워보이지만 막상 코드를 뜯어보면 이해하기가 만만치 않은 알고리듬으로 채워져 있으므로 단계별로 우리가 이해할 수 있는 언어를 사용하여 해설해 보기로 하자.
_____________________________________________________________________________________________________
알고리듬 요약: 1000종의 이미지들에 대해서 사전학습된 vgg19의 5단계 블록 중에서 blocki_conv1(i=1,2,3,4,5)에 해당하는 레이어 데이터를 흉내내고자 하는 스타일 처리용으로 할당하고 Gram 매트릭스를 계산하여 대체한다.
아울러 block5_conv2 레이어 데이터 하나는 스타일을 전이시키고자하는 사진이나 그림에 할당하여 그대로 사용하도록 한다. 이러한 레이어 설정을 가지고 style_image 를 적용하여 style_target을 연산하고 아울러 content_image 를 적용하여 content_target을 설정한다. 이로부터 style_image 의 스타일이 전이된 content_image 를 학습을 통해 창조하기 위해서 변수형태의 텐서 image 를 tf.Variable(content_image) 로 초기화하고 image 로 두어 학습을 준비한다.
학습에 필요한 style_content_loss함수는 일단 image 를 class StyleContentModel 에 입력하여 'style' 과 'content' dictionary 를 각각 계산하고 앞서 준비한 2개의 target들과의 차이를 계산하여 제곱하고 상대적인 비율을 감안하여 합산한다. Adam 옵티마이저를 사용하여 학습하되 gradient 가 계산되면 동시에 image를 업데이트 해 나간다.
______________________________________________________________________________________________________
우선적으로 이 코드를 Colab 에서 셀별로 실행하는 것으로 생각하자.
Colab에서 이 코드를 실행하려면 우선적으로 2개의 그림파일 입력이 있어야 할 것이다.
즉 컨텐츠 그림 하나와 스차일 그림 하나가 각각 필요할 것이다.
컨텐츠 그림은 유명 화가의 스타일을 입힐 사진이나 밑 그림에 해당한다.
스타일 그림으로부터는 미술적인 요소(색상, 명암, 선굵기, 면요소의 터치 감각 등)들을 추출하게 될 것이다.
이 두 그림들은 Colab NDRIVE 외부에 해당하는 사용자 PC 로부터 드래그에 의해 NDRIVE 에 반입되어야 할 것이다.
NDRIVE의 이 그림들을 코드에서 읽어들이기 위해서는 Colab 코드 시작 단계부터 NDRIVE 를 구글 마운팅해야 한다.
이 명령을 실행했을 경우 Colab 코드와 연결되는 NDRIVE 폴더 구조는 다음과 같이 구성된다. content/drive/MyDrive 까지는 구글에 의해 정해진 폴더 구조에 명칭이다.

# 컨텐츠 lakehouse.jpg 와 스타일 stlimmg.jpg 이미지들의 경로를 설정하자. 이외에도 git http:// ... .git 와 같은 방법도 있으나 네트워크 상에 미리 저장해둬야 하므로 직접 준비한 그림들을 불러 읽어 들이는 방식이 훨씬 편리한 듯하다.
content_path = ("/content/drive/My Drive/imagedata/lakehouse.jpg")
style_path = ("/content/drive/My Drive/imagedata/stlimg.jpg")
print(content_path)
# 이미지 경로 설정이 완료되었으므로 아래의 load_img( ) 함수를 사용하여 확장자가 jpg인 이미지 파일들을 읽어들이자.
이미지 폭과 높이 중 최대값 범위를 512 로 두고 컬러(channel=3)로 가정하자.
이미지 픽셀 값이 정수(int)일 수도 있으므로 모두 실수(tf.float32)로 변환한다.
이미지 shape 값을 출력--> [332,333,3]-->shape=3이다.--> matplotlib에 의한 이미지 출력을 위해서는 shape 값을 2로 변환해야 함. 코드 중에서 슬라이싱 기법에 해당하는 [:-1] 은 [332,333,3]에서 마지막 기준 하나 앞을 뜻하므로 [332,333] 로 shape 값=2 로 처리된다. PyTorch 까지 포함한 많은 머신 러닝 코드에서 matplotlib 에 의한 그래픽 출력을 위해 이러한 처리가 필요함에 유의하자.

아래의 함수 load_img 에서 읽어 들이는 이미지 데이터들인 content_image 나 style_image 는 폭과 높이가 약간의 차이는 있을 수 있다. 구글에서 주어진 style 이미지를 출력해 보면 거의 520:520임을 알 수 있다.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3) # Detects it is a BMP, GIF, JPEG, or PNG
img = tf.image.convert_image_dtype(img, tf.float32) # 실수형 데이타 유형-->(0,.1.0)
shape = tf.cast(tf.shape(img), tf.float32)[:-1]
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :] #??
return img

이미지 출력 확인 후 우선적으로 content image 를 대상으로 사전학습된 vgg19 커늘을 사용하여 content image 인식 작업을 수행하자. vgg19 은 1000종의 이미지를 대상으로 한 ImageNet 을 사용하여 학습되었으며 이 예에서는 'castle' 즉 74% 확률로 '고성'으로 인식된다.

Architecture
style transfer 작업에 적합한 CNN 이미지 네트워크는 오픈소스로서 적정한 수의 CNN layer를 갖춘 모델이 좋다. 인식률이 가장 높다고 알려진 ResNet 의 경우는 마키텍츄어에 포함된 layer 수가 너무 많아 style transfer 작업에 적합치 않으며 2014년 ILSRC 컨퍼런스에서 2등을 했던 vgg19 이 오히려 적합한 모델 중의 하나이다.

2014년 ILSRC 컨퍼런스에 vGG16과 VGG19 2개의 아키텍츄어가 제안되었다. 둘 다 classifiation 성능은 비슷하지만 style transfer 작업에는 스타일 정보를 더 많이 추출할 수 있는 즉 layer가 많은 모델이 좀 더 유리할 수 있을 것이다.
tf.keras.applications에서 제공하는 모델들은 케라스 함수형 API를 통해 중간층에 쉽게 접근할 수 있도록 구성되어있다. 아래 코드의 내용에 포함된 확장자가 h5인 binary vgg19 학습결과 파일을 사용하여 CNN layer 정보를 추출하자. 이미지 필터링 과정에서 activation 함수는 단지 gradient 계산과 관련성이 있으며 pool 레이어는 이미지 크기 축소와 연관되며 특히 CNN에서는 convolution layer들이 이미지 정보를 추출(extraction)하는 핵심 역할을 한다.
include_top=False 는 vgg19 아키텍츄어에서 fully connnected layers 부분을 배제하고 특징추출(feature extraction) 역할을 하는 컨볼루션 레이어들까지만 사용할 예정이다.

함수형 API를 이용해 모델을 정의하기 위해서는 모델의 입력과 출력을 지정해야 한다. 함수 vgg_layers 는 리스트 데이터인 layers_names 를 인수로 사용한다. style_layers 는 5개의 데이터를 포함하는 반면에 contents_layers 는 1개의 데이터를 포함한다.
함수 vgg_layers는 내부에서 이미지 데이터 입력을 제외한 나머지 웨이트 값들을 미리 불러다 둔 상태이기 때문에 이미지 데이터를 제공해주면 일종의 prediction 출력이 가능하다.
이 함수는 후반부의 class StyleContentModel 내부로 상속된 후에도 재사용된다.

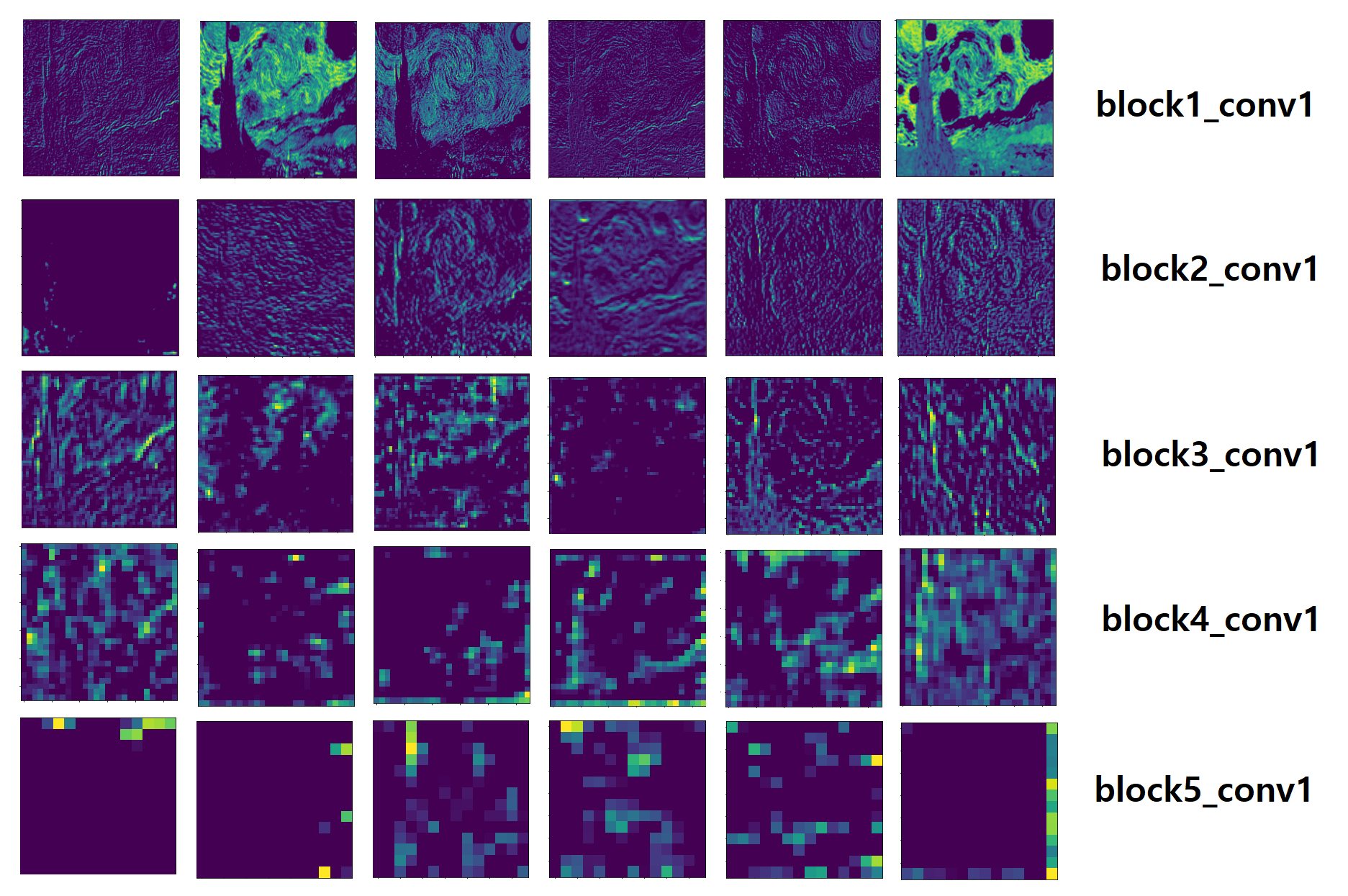
아래는 CNN 각 레이어 별로 6개의 feature map 이미지를 출력해 보았다. CNN 레이어가 깊어(Deep)질수록 구체적에서 모호함으로 바뀜을 알 수 있다.
고호의 Saint-remy
티븅겐의 castle 사진

Gram 매트릭스

vgg19 네트워크의 각 CNN 레이어는 아키텍츄어에서 볼 수 있듯이 일정 갯수의 필터 수를 보여준다. 예를 들자면 이미지 데이터는 510x512x3 으로 주어진다. 마지막 숫자 3은 RGB 컬러를 뜻하는 channel 이라 한다. 한편 컨볼루션을 적용하기 시작하면 첫번째 블록에서는 이미지 크기가 그대로 유지되면서 필터 수만 64 로 증가되어 510x512x64 가 된다. CNN 레이어가 깊어질수록 필터 수가 증가하게된다. 현재 코드에서는 함수 load_image( )에서 max_dim= 512 로 한정하였다.
아울러 Fully connected layer 이전에 위치하는 중간 CNN 레이어들이바로 feature map 에 해당한다. 예를 들어 style_image의 첫번째 컨볼루션 레이어 즉 'block1_conv1'에서 shape=(1,510,512,64) 이다. 따라서 이미지 크기는 510x512 이므로 이 필터를 row 또는 column 별로 뜯어내어 한 줄로 바로 펴서 261120X1 또는 1X261120 으로 만들어 feature vector 를 형성할 수 있다. 즉 이 첫번째 레이어에서는 필터수가 64개가 될 수 있다. 마찬가지로 두번째 이후로도 아래 그림에서 처럼 매트릭스의 row 또는 column 들을 한 줄씩 뜯어내어 긴 한줄의 i 번째 feature vector 를 형성할 수 있다.

한편 각 레이어의 모든 필터별 feature vector 를 형성하고 같은 레이어 안에서 이들 필터들 간의 즉 i 번째와 j 번째의 내적 값들을 연산해 낼 수 있을 것이다. 이 내적 값들로 구성된 것이 바로 Gram 매트릭스이다. 이 Gram 메트릭스 요소인 F(l,i,j)는 content_image 와 style_image 의 CNN 중간 층들에서 연산할 수 있는 양이다.
이 기법은 2014년 출판된 "A Neural Algorithm of Artistic Style"의 Method 편에 기술된 내용으로서 Gram 매트릭스 계산 알고리듬에 관한 기술인데 이해하기가 어려워 위의 다이아그램을 그렸으니 참고하기 바란다.

클라스 StyleContentModel 은 5레이어를 가지는 style_layers 와 1개레이어를 가지는 content_layers 를 합하여 즉 6개레이어로 입력 받을 수 있도록 def __init__(self, style_layers, content_layers): 에 명시하고 있다. 아울러 이미 앞에서 style_layers 각각의 레이어 별 웨이트 값 수치 데이터 instance를 추출하기 위해 사용되었던 외부의 함수 vgg_layers 도 상속 받도록 super 용법을 사용한다. 앞서 style_image*255을 적용하여 5개 각 레이어 별 통계 데이터를 얻어내었다.

class StyleContentModel( ), super( ),... 기법이 상당히 복잡한 이유로 인해서 다음과 같이 검증 계산을 해 보았다. 즉 Gram 매트릭스 연산 부분을 아래와 같이 # 처리하여 억제 시킨 후 style_image*255를 적용하여 6개 레이어에 대한 통계 데이터를 계산해 보면 앞 단계에서 style_image 데이터에 대해 5개 레이어에 대해서 vgg_layers 를 사용한 계산 결과와 비교 시 값이 좀 변동됨을 확인할 수 있다. 이와 같은 확인 작업 후 다시 원래 대로 원상 복구하여 사용하도록 한다. 아울러 style_layers feature map에 대해서만 Gram 메트릭스 계산이 이루어짐에 유의하자.

앞서서 class StyleContentsModel 을 사용하여 2개의 dictionary 를 준비했으므로 각각 분리해서 사용하기로 한다.

여기서 style_image 의 스타일이 전이된 content_image 를 창조하기 위해서 변수형태의 텐서 image 를 tf.Variable(content_image) 로 설정하자. content_image를 tf.Variable의 종속변수로 넣어 주는 이유는 텐서 Variable의 shape을 content_image 와 동일하게 하기 위함이며 변수텐서 tf.Variable 의 시작 점이 content_image 임에 유의하자. 아울러 clip-by_value 명령을 사용하여 최소값이 0.0, 최대값이 1.0이 되도록 초기화한다.
옵티마이저는 무난하게 Adam 으로 설정한다. 앞으로 style 과 content에 관한 2개의 loss 함수 설정에 대비하여 이들의 상대 적인 가중치 값을 미리 부여 한다. 이 값 설정에 따라 스타일이 전이 되는 효과가 크게 차이가 날 수 있다.

style 과 content에 관한 loss 함수를 정의하도록 하자. class StyleContentModel 을 사용하여 앞서 준비한 image = tf.Variable(content_image)를 사용하여 extract( ) 명령을 실행하면 dictionary 형태로 outputs 를 얻어낼 수 있을 것이다. 이로부터 함수 style_content_loss에 의해 스타일과 컨텐츠를 일정 비율로 합산한 loss 함수를 계산하여 반환한다.
되풀이 되는 style_content_loss 함수계산에서 image가 매회 업데이트 되면 ouputs, style_outputs, content_outputs가 변동되며 style_targets 와 content_targets 는 초기화 된 값을 그대로 유지한다.

@tf.function은 텐서플로우 코드의 연산 성능에 크게 기여하는 것으로 알려져 있다.
사실 머신러닝 코드에서 가장 컴퓨팅 부하를 감당해야 하는 곳은 최종 웨이트 값 서치를 위한 학습과정일 것이다.
따라서 train_step(image) 를 함수화 하여 @tf.function 을 적용하면 눈에 띄는 성능향상이 있어야 할 것이다.
현재 epoch=10, steps_per_epoch=100 으로 학습 시 GPU 설정 여부와 상관 없이 거의 2배 가까운 컴퓨팅 가속성능을 확인할 수 있을 것이다.

한편 train_step( ) 실행과정에서 매 회 마지막 줄의 assign( ) 명령에 의해 image 의 clip 처리 후 다시 image에 할당하여 업데이트 작업을 하게된다.

1000회 학습 결과 그럭 저럭 기대한 결과가 얻어진다.

이 알고리듬에서 좀 더 개선해 보자면 style 레이어들에 의한 loss 함수 기여가 균등하게 이루어지고 있으므로 이비율을 좀 더 조절하면 특정한 style 이 강조 될 수 있을 것이다.
Under Construction ...
'AI 페인팅' 카테고리의 다른 글
| Colab Stable Diffusion 그림그리기 (0) | 2023.02.07 |
|---|---|
| Style GAN AI Painting with Van Gogh's Saint Remy (0) | 2022.04.10 |
| Style GAN에 의한 AI 페인팅 (0) | 2022.03.20 |