
MNIST 문제에서처럼 수기 숫자 데이터를 샘플해서 DB를 만들 듯이 알파벳 문자도 비슷하게 처리하면 되지 않을까? 고 반문할 수도 있을 것이다. 다음의 MNIST 수시 숫자 샘플들을 살펴보자 수많은 사람들이 임의로 작성한 수기문자임에도 불구하고 뭔가 잘 정리되었으면서도 인위적인 느낌이 많이 나지 않는가?

그렇다. 이 수기숫자 DB 구성을 위해서 숫자 하나당 크기 방향 굵기를 비롯하여 많은 요인들이 이미 관리 된 상태에서 샘플된 데이터이다. 그렇다면 아무런 제약 조건 없이 샘플되는 글자는 어떤 기하학적 특징을 가지게 될것이가? 다음과 같이 기본적인 4가지 요소 즉 병진, 확대, 회전 및 가중 여부가 큰 영향을 미칠 것이다.

즉 MNIST에서 처럼 DB가 일정한 조건하에처럼 구성되지 않으면 softmax에 의한 인식 작업이 인식율이 떨어지면서 무의미 해 질 수 있다.
다음의 회전된 문자 X에 대해서 이들이 같은지 다른지 판단해 보기로 하자. 사람 입장에서는 이들이 유사하게 X 라고 직접 쉽게 판단할 수 있다. 하지만 컴퓨터 입장에서는 어떤 방식으로 처리해야 할 것인지 쉽지 않다. 같으면 왜 같은지 아니면 왜 서로 디른 글자인지 근거가 제공되어야 할 것이다.

다음은 컴퓨터가 이미지를 인식하는 방법에 근거해서 표현해 보면 흰색은 +1 검은 색은 –1로 둔자. 0∼255 로 둘 수도 있지만 Rosenblatt 의 아이디어를 그대로 따르기로 한다.

이 2가지의 데이터를 가지고 컴퓨터가 가장 쉽게 할 수 있는 일은 각 셀들의 값을 비교해서 매치(match)가 되는 지 확인하는 일 일 것이다. 다음 그림에서 match 작업 결과를 보여 준다. 흰색은 정확하게 매치가 되는 픽셀이며 붉은 색 표시는 매치가 안 되는 픽셀들을 나타낸다. 이 결과를 가지고 단순하게 판단한다면 5개는 매치가 되고 8개는 매치가 되지 않으므로 결과는 서로 다르다. 이런 식으로 컴퓨터가 판단한다면 그 컴퓨터도 너무 순진해 보인다.

이러한 작업 수행에 필요한 컴퓨터 알고리듬으로서 오래 전 닥터 후벨이 고양이 시각 피질 연구에서 알아낸 그러한 종류의 알고리듬이 필요하지 않을까 싶다.
CNN에서는 MNIST 에서와는 달리 전체 이미지가 매치되는지 비교하기 보다는 이미지를 작은 요소로 나눈 후 이 작은 요소들의 특징들이 얼마나 유사한지 또는 매치가 되는지 쉽게 체크해 볼 수 있는 방법을 택한다. 다음의 ConvNets 그림에서 두 개의 이미지들을 대상으로 부분적으로 매치가 되는 공통점을 찾아보자. 중앙의 X자형 5개 픽셀들은 동일하며 2개짜리 대각선 픽셀들은 서로 위치가 좀 변경되었다.

다음 페이지의 그림에서 좀 더 체계적으로 이미지를 구성하는 3개의 작은 기본적인 이미지 요소들을 고려하자. 즉 3X3 매트릭스 크기의 대각선형 ⓵번 ⓷번과 x자형 ⓶ 이미지 요소들이다. 이 세 가지 작은 요소들을 사용하여 주어진 전체 이미지를 재구성이 가능하다. 여기서부터 세부적인 특징을 추출해 문자를 식별해 나가게 되는 CNN 의 필터링 과정을 살펴보자.

다음 그림에서처럼 위 그림에서의 대각선형 ⓵번과 매치되는 부분에서의 필터링 연산을 고려해 본다. 원래 컨볼루션은 필터 매트릭스를 윗부분 코너로부터 우측으로 스트라이딩 시킨 후 우측 벽에 닿으면 TV 주사선이 움직이듯이 다시 왼쪽으로 옮겨가 스트라이딩 작업을 계속해 오른쪽 하단에 닿을 때까지 실행하는 것이다. 지금 필터링 계산은 스트라이딩 와중에 그 부분에 이르렀을 때에 실행하는 필터링 계산 예이다. 필터와 매치되고 있는 부분들끼리 서로 곱셈을 실행해서 우측 상단의 3X3 매트릭스에 적어 넣자. 9번 작업 후 우측 하단의 3X3 매트릭스에서 볼 수 있듯이 전부 다 1 이 된다.

이 9개의 결과를 모두 합해서 9로 나누어 평균을 구해서 다음 페이지 그림의 오른쪽 회색 보드에서처럼 3X3 매트릭스 중앙에 평균 값 1을 처리해 넣는다.
컨볼루션 필터링 작업은 처음 스트라이딩 시작할 때부터 지정된 중앙 위치에 평균값을 넣기 시작하여 끝날 때까지 처리하면 9X9 매트릭스에 외곽 한 줄이 비는 7X7 사이즈의 작은 매트릭스가 얻어지게 된다. 컨볼루선 필터링 이전과 동일한 크기의 매트릭스를 얻고 싶으면 9X9 매트릭스 외곽을 인위적으로 padding 작업을 해주어 11X11 매트릭스를 만들고 padding 된 위치에는 0의 값을 넣어 두면 된다.

다음 그림은 스트라이딩 과정 중에서 가운데 X 자형 이미지 부분에서 필터링 작업을 하게 되면 평균값이 0.55 가 된다. 항상 1의 값 이 얻어지는 것은 아니란 점을 참고하자.
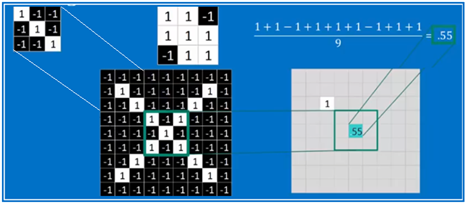
이와 같이 ⓵ 번 대각선 필터를 사용하여 처리해서 다음 그림에서처럼 7X7 매트릭스를 얻어낼 수 있음을 알 수 있다.

이 작업 결과에서 9X9 이미지의 기하학적 특성과 ⓵ 번 대각선 필터에 의해 필터링 된 7X7 매트릭스의 특징을 비교해 보면 특히 ⓵ 번 대각선 방향으로만 1.0에 가까운 숫자를 보여주며 나머지는 숫자 값이 상대적으로 작아 쉽게 구분할 수 있다. 즉 ⓵ 번 대각선 특징이 필터링 된 것이다.
그렇다면 ⓶ 번 x자형 이미지 와 ⓷번 대각선 이미지를 사용하여 필터링 한 결과를 함께 비교해 보기로 하자. 다음과 같이 3개의 7X7 매트릭스가 얻어지는데 기대했던 바대로 원래의 9X9 매트릭스에서의 특징을 그대로 필터링 한 닮은 결과가 얻어진다.

TensorFlow CNN 라이브러리 사용 시에 보통 32~256개의 디지털 필터를 사용함에 유의하자.
이어지는 6-4절에서 CNN의 pooling 원리에 대해서 알아보자.
'머신러닝' 카테고리의 다른 글
| CNN 필터와 스트라이딩 코드 작성을 위한 워밍업 (0) | 2021.07.09 |
|---|---|
| CNN 이미지 인식: Pooling to Deep Stacking (0) | 2021.07.09 |
| 6-2 컨볼루셔널 뉴럴 네트워크(CNN:Convolutional Neural Network)의 이미지 인식 (0) | 2021.07.09 |
| 6-1 고양이 시각피질의 edge detection 실험과 CNN(Convolutional Neural Network) (1) | 2021.07.08 |
| 5-4 2차 방정식 TensorFlow 머신 러닝 (0) | 2021.07.07 |