구글 Colabo에서 Keras에 의한 CIFAR-10 image classification 작업을 GPU를 사용하여 처리해 보자.
구글 Colabo에서 imprt tensorflow as tf 명령 실행 후 tf.__version__ 명령을 사용하여 현재 설치되어 있는 텐서플로우 버전을 살펴보면 Default 가 2.2.0 임을 알 수 있다.
keras.dataset 로부터 cifar10을 라이브러리로 불러들여 학습자료(train_X, train_Y) 와 테스트자료(test_X, test_Y) 튜플로 처리해 버리자. 토론토 대학 서버로부터 zip 파일을 다운 받아 압축을 해제한다.

학습자료 train_X 중에서 0번서 5번까지 그래픽 출력해 보자. 개구리, 트럭,트럭, 개, 자동차, 자동차 순이다.

Keras에서 CNN을 구현하기 위한 Sequential 로부터 옵티마이저에 이르기까지 필요한 모든 요소를 import 한다.
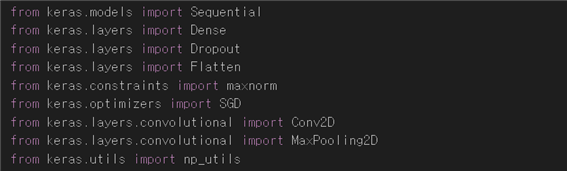
Keras에 의한 image classification 작업을 위해 Sequential, Flatten, Dense, Dropout 및 CNN을 지원하는 Conv2D 와 MaxPooling2D를 import 하자.
학습용 데이터와 테스트 데이터를 255로 나누어 0.0~1.0 사이로 normailzation 작업을 수행하자.

학습용 및 테스트용 라벨 데이터를 on hot code 로 변환하고 아울러 cifar10 의 전체 클라스를 출력해 보자.

Sequential을 선언하여 모델을 설정하자. kernel_constrain=maxnorm(3) 조건 즉 크기가 3을 넘지 말아야 한다는 조건을 제외하고는 텐서플로우 CNN 알고리듬과 거의 동일하다. maxnorm 조건은 최종 accuracy에 영향을 미치는 것은 사실이나 배제한다고 해도 코드 실행에 큰 문제는 없다.

GPU 지원을 받아 10 epoch 에 걸쳐 SGD 옵티마이져를 사용하여 loss 함수를 최소화 시키자. 이 단계에서 구글 Colabo 의 런타임 유형 변경에서 GPU 모드를 반드시 확인하자.

최종적으로 테스트 데이터를 사용하여 인식율을 체크해 보면 68% 임을 알 수 있다. 그다지 높은 값이 아니다. 마지막 unseen 외부 데이터를 사용해서 verification을 해 보면 50: 50을 조금 넘을 수 있는 수준임을 알 수 있다. 적어도 90~95%는 넘어야 안정적으로 classification 이 이루어진다.

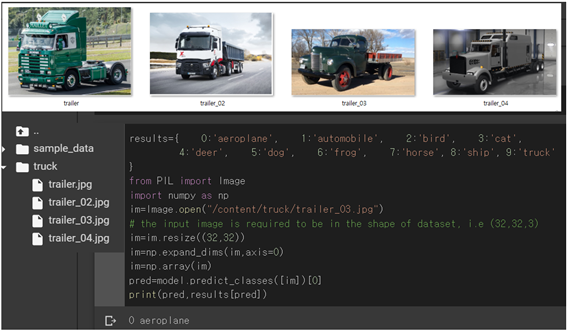
unseen 데이터로서 4종의 트럭 이미지를 외부에서 가져다 업로딩하여 테스트 해보면 첫 번째와 네 번째 이미지는 제대로 판독이 되고 두 번째 세 번째는 aeroplane 으로 잘못 판독한다. 평균 인식률이 70% 이므로 대략 50:50 판독률 수준이다. truck 폴더를 미리 준비 한 후에 그림 좌측처럼 이미지들을 업로드 하고 image.open() 명령에서 경로를 정의한다.
'머신러닝' 카테고리의 다른 글
| 자동차 번호판 문자열 인식을 위한 Tesseract_OCTR 라이브러리 설치 (0) | 2020.08.06 |
|---|---|
| OpenCV 자동차 번호판 문자열 인식 (0) | 2020.08.01 |
| 7-18 Haarcascade 특징추출(Feature Extraction) 원리와 드로우잉 스케치 OpenCV AI 안면인식 (0) | 2020.04.17 |
| 2-18 Fashion MNIST 텐서플로우 머신 러닝 Simple 네트워크 예제 (0) | 2020.02.27 |
| 1-17 TensorFlow Lite 안드로이드 스튜디오 업로딩 예제 (0) | 2020.02.17 |